自从ChatGPT公开发布以来,人们几乎没有一天不讨论LLM(大型语言模型)、RAG(检索增强生成:Retrieval Augmented Generation)和向量数据库的新内容。技术世界充斥着LLM的可能性,LLM被视为将改变我们生活的最新技术:对一些人来说是最好的,对另一些人来说则是最坏的。除此之外,检索增强生成(RAG)已经成为一种动态解决方案,以适应不断变化的知识环境。但是,在幕后还有一个至关重要的角色:向量索引和数据库。
虽然LLM、RAG和向量数据库已经被广泛并深入讨论过,但是支持这些创新的(向量)索引却鲜为人知。在本文中,我们将揭开向量索引概念的神秘面纱,以帮助您了解索引如何使得在大量集合中查找信息变得轻而易举。
1、什么是索引?
我们都遇到过这样的情况:你和你的朋友要在她家见面;但是,她事先提供给你的唯一信息是“我住在大都会区”。当您到达上述大都会区时,却遇到如下图所示的尴尬:

Yim在Unsplash上的照片
好吧,如果没有任何帮助,找到她的位置需要一段时间!不过,如果入口处有一张导航地图就好了……
这正是索引的意义所在:如何快速找到人员(或数据)所在的位置。
提示:黄页(https://www.yellowpages.com/)就是一个索引,它可以帮助你根据人们的名字找到他们的家。
索引是一种数据结构,用于提高数据检索操作对数据的速度。换句话说,这就是你如何组织信息,以便快速找到你想要的东西。
人们通常使用键对数据进行索引。数据的存储顺序基于键,而且可以使用多个键进行索引。例如,在前面的黄页网站中,第一个键是姓氏,第二个键是名字。
索引不一定存储全部数据。它只关注用于在整个数据中快速定位和访问特定数据片段的关键部分。
书籍后面的索引就是一个很好的例子:它显示了在哪里可以找到使用相应单词的页面;因此,它将每个单词映射到页码,而不是句子本身。
索引“隐藏”于搜索引擎和数据库背后:它们在提高数据检索操作的效率和速度方面发挥着至关重要的作用。
因此,如何组织数据的选择就显得至关重要,这要取决于上下文。
例如,在黄页的例子中,如果索引是按电话号码组织的,但是你只知道他们的名字,那么找到他们的地址将非常困难!
信息就在那里;你最终会找到它,但所需的时间会阻止你进行这样的尝试。另一方面,使用黄页,只需浏览一眼页面,就可以准确地知道是需要向后看还是向前看!字典顺序允许您进行大致的对数搜索。这就是为什么索引的选择是至关重要的。
一般来说,索引有一个非常精确的目的:它可以被设计为执行数据的快速插入或检索,或者执行更奇特的查询,如范围查询(“检索今年5月1日至8月15日之间的所有数据”)。要优化的操作的选择将决定索引的外观。
在线事务处理(OLTP)和在线分析处理(OLAP)数据库之间的主要区别在于它们想要优化的操作的选择:OLTP侧重于行上的操作(如更新条目),而另一个侧重于列上的操作。这两种类型的数据库不会使用相同的索引,因为它们不针对相同的操作。
(1)索引和数据结构之间的区别是什么?
数据结构(https://w.wiki/7ma9)是一种在计算机中组织和存储数据的方式,以便能够有效地访问和操作数据。这样解释,有时很难看出索引和数据结构之间的区别,那么到底它们之间的区别是什么呢?
简言之,索引主要用于插入、搜索、排序或筛选数据,但是数据结构则更为通用。索引是使用数据结构构建的,但通常不存储数据本身。
如果你考虑一个电影数据库,那么每当索引更新时,你不想在大文件中移动:你存储的是指向文件的指针,而不是文件本身。指针可以看作磁盘上文件的地址。
现在,您对索引应该有了大致的了解,接下来让我们关注数字示例。以下是一些常见的(数字)索引:
- 反向索引
- 哈希索引
- B-树
- 区分位置的哈希(LSH)
为了更好地理解索引是如何工作的,让我们研究一下最基本的索引之一:反向索引(Inverted index)。
(2)反向索引
反向索引是搜索引擎中使用的标准索引。
它旨在快速找到信息的位置:它旨在优化检索时间。
简而言之,反向索引将内容映射到它们的位置,有点像书的索引。
它通常用于将特性映射到具有该特性的数据。
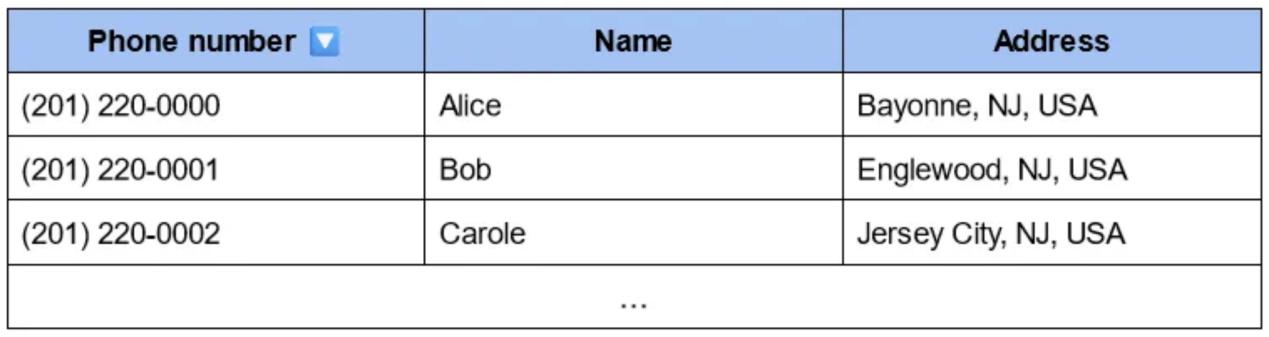
例如,假设你想知道谁住在同一栋楼里。
首先,你应该有一个表格,每个名字都对应一栋楼(这个表格本可以帮助你找到爱丽丝):
每当有人到达或离开该地区时,此表都会更新。
如果你想在这个表中找到住在B楼的人,你必须遍历整个表。
虽然这在技术上是可能的,但它不会缩放,因为计算时间会随着表的大小线性增加。
想想该地区的公寓数量:如果你想通过逐一查看所有档案来找到B栋的所有住户,这需要一段时间!
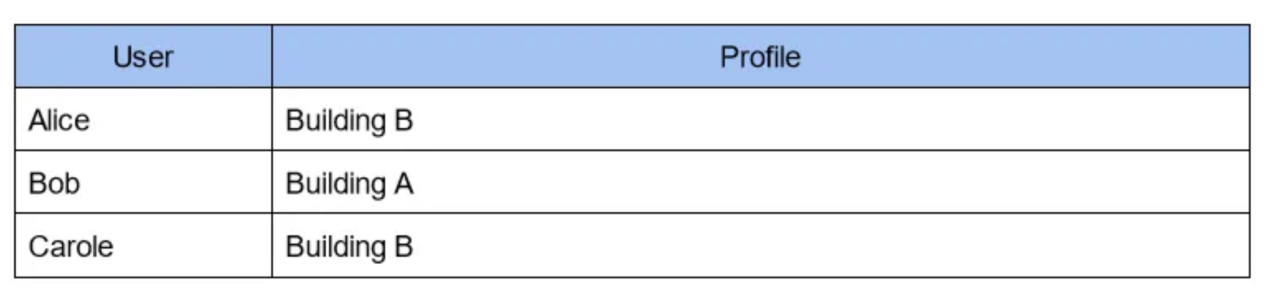
另一种解决方案是使用反向索引:您维护一个表格,其中的建筑物被用作密钥,并与居住在其中的人相连:

此表与上一个表同时维护:添加或删除新人的成本比以前略高,但检索时间已缩短到几乎为零!
要找到住在B栋楼的人,你只需访问此表的行“B栋楼(Building B)”即可获得结果!
还有一个典型的例子:反向电话查找也是电话号码的反向索引!
在实践中,反向索引有点复杂,因为它们处理的数据比配对(用户、兴趣)更复杂。索引通常存储为哈希表(https://w.wiki/7mdQ)中。
尽管反向索引相对简单,但它们是搜索引擎中最常见的索引之一。
(3)索引和数据库
数据库建立在索引之上。索引通过存储指向数据库数据的指针或引用来增强数据库中的数据检索。它不存储实际数据,而是作为一种快速访问数据的手段,显著提高了查询性能。
数据库不仅仅是索引,因为它是一个全面的数据管理系统。它存储、组织和管理实际数据,加强数据完整性,处理事务,并提供索引之外的一系列功能,使其成为数据存储和操作的中心枢纽。虽然索引加快了数据库中的数据检索,但数据库是数据存储、管理和检索的完整生态系统。

总之,索引就像数据库中的路标,为您查找的数据指明方向。相比之下,数据库是实际数据所在的存储库,并配备了各种工具和功能来管理和操作这些数据。
根据您的使用情况,您可能不需要整个数据库,而只需要索引,因为全面管理数据的成本可能非常高昂。
2、向量索引和向量数据库
(1)什么是向量索引?
简而言之,向量索引是一个索引,其中键是向量。
在我们的反向索引示例中,键是单词(爱好和名称)。在向量索引中,我们操纵向量:固定大小的数字序列。

两个大小为4的向量
我知道,我能听到你说,“我数学不好,我不想用向量”。
别担心,你不需要擅长数学就能理解向量索引。
您所需要知道的是,使用向量使您能够依赖强大且优化的操作。
你可能会问自己的第一个问题是,“你的向量有什么有趣的?”
比方说,你终于在爱丽丝家找到了她,现在你想找点吃的。你可能想找最近的餐馆。于是,你查找一份餐馆列表,最后得到一张餐馆、特色菜和地址的表格。让我们来看看您可以找到的信息:
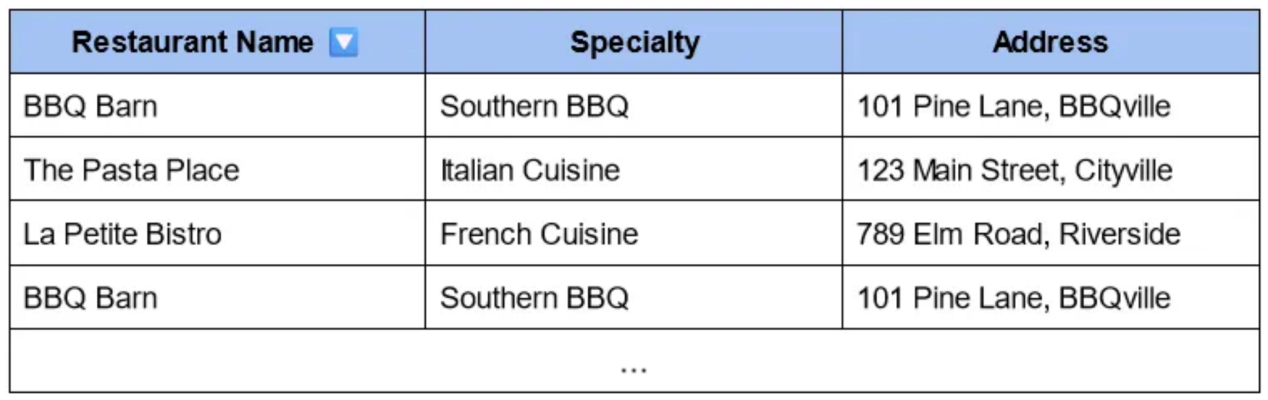
这看起来没有帮助,对吧?你唯一的选择是浏览列表,逐个读取地址,然后手动评估它离你有多近。我们可以尝试自动对最近的地方进行排名,但基于原始地址计算距离很困难(两条街道可能在附近,但名称不同)。
想象一下,现在你有一张表格,上面有GPS位置,代表每个餐厅的确切纬度和经度:
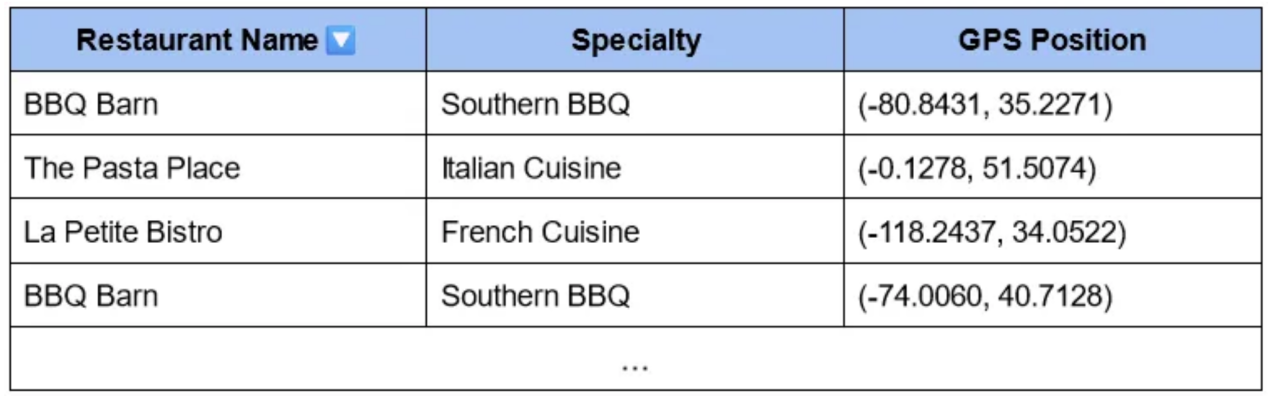
每个位置都是大小为2的向量。有了这些向量,你就可以通过简单快速的数学运算轻松计算到自己位置的距离。然后你可以快速检索到最近的餐馆,换句话说,距离你最小的餐馆!
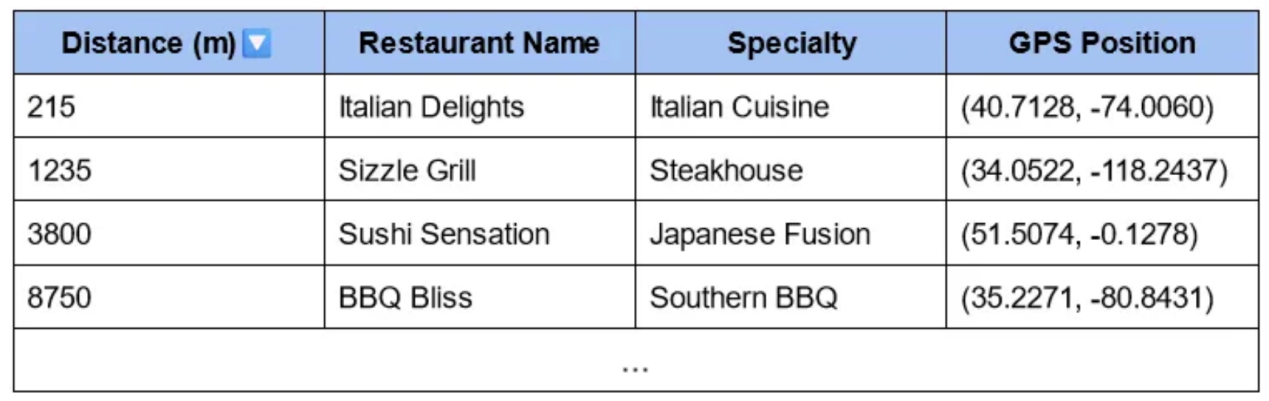
现在,你可以很容易地找到离你最近的餐馆了!
有趣的一点是,通过直接根据向量(本例中的GPS位置)对表进行索引,我们可以优化索引,从而快速找到距离最低的条目。
向量索引是专门的索引,旨在有效地检索与给定向量最接近或最相似的向量。这些索引依赖于优化的数学运算来有效地识别最相似的向量。
在我们的例子中,使用的距离是经典距离,但是针对所有现有距离或相似性都使用了索引,例如余弦相似性度量。
位置敏感哈希(LSH)是用于查找数据集中k个最相似数据点的最广泛使用的索引之一,它适用于不同的距离或相似性。
“这很好,但我没有在数据库中使用向量”。
这就是令人兴奋的部分:你可以将任何东西转化为向量。
简单地采用二进制表示是低效的,因为它可能包含噪声,所以找到一种保留数据特性的表示是至关重要的。
将不同的信息表示为向量以使用向量索引已成为提高系统效率的标准方法。向量化已经成为一门艺术。
例如,如果你有一个图像数据集,并且你想要一个数据库,在那里你可以找到与给定图像最相似的图像,那么,你可以使用图像的SIFT描述符。
(2)向量索引和向量数据库之间的区别是什么?
向量索引和向量数据库之间的区别与索引和数据库之间的差异相同:索引旨在快速找到数据所在的位置,而向量数据库使用向量索引快速执行检索查询,但它们也存储和维护数据,同时提供额外的操作和属性。
3、LLM和RAG之间的联系是什么?
既然您已经了解了向量索引,您可能会想,为什么这么多关于LLM和RAG的讨论也讨论了向量索引。为了理解原因,让我们首先快速解释什么是检索增强生成(Retrieval Augmented Generation,简称RAG)。AG是LLM的一个固有局限性的巧妙解决方案,即其知识有限。
LLM只知道它们接受过训练的数据。增加它们知识的一种技术是提示工程(Prompt Engineering),将额外的数据集成到查询提示中:“给定这些数据{data},回答这个问题:{question}”。
虽然这种方法很有效,但它面临着一个新的挑战:可扩展性。不仅提示的大小是有限的,而且包含的数据越多,查询的成本就越高。
为了克服这一点,检索增强生成通过只插入最相似的数据来限制数据量,这就是向量索引的作用所在!
它的工作原理如下:
所有文档最初都使用LLM转换为向量(1)。更具体地说,使用LLM的编码器部分。
这些向量被用作索引向量索引(2)中的文档的关键字。
在执行查询时,使用LLM对查询进行向量化(3)。然后在向量索引中查询得到的向量,以检索最相似的文档(4)。然后,使用提示工程将这些文档用于回答查询(5)。
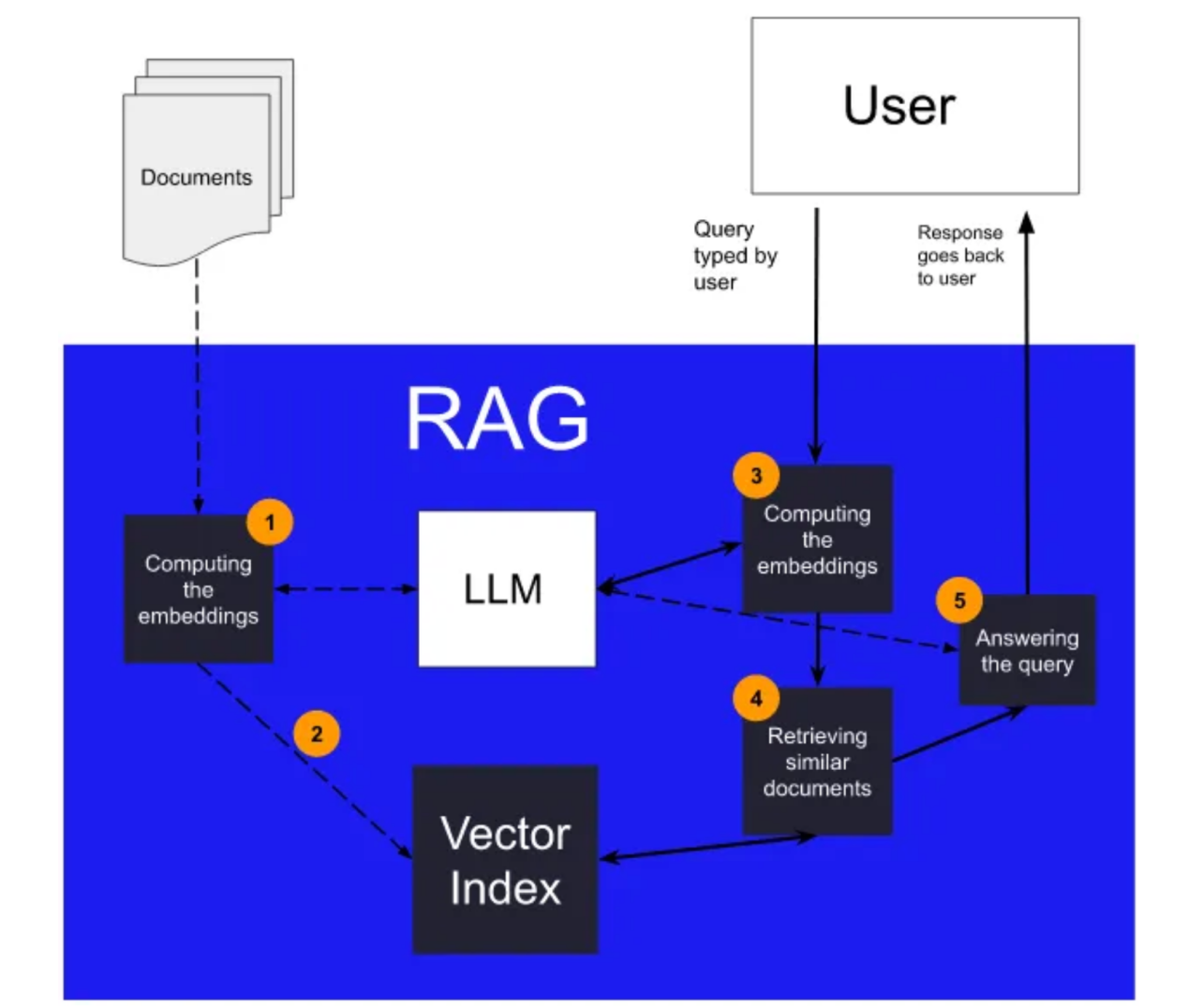
检索增强生成(RAG)依赖LLM和向量索引
就是这样!
正如您所看到的,与LLM类似,向量索引在RAG中占据中心位置。
有些人更喜欢使用向量数据库而不是向量索引。只要您想在多个应用程序中重用相同的数据,就可以了。但是,如果您主要关心的是检索效率或为每个应用程序定义索引的灵活性,那么部署单个向量索引通常更简单、更快。
结论
我相信你现在已经具备了参与那些关于LLM和RAG的激情讨论的所有背景知识。
索引在数据检索中起着核心作用。由于数据检索可能仍然是数据技术的关键组成部分,因此了解索引(包括向量索引)是关于什么的至关重要。
如果你想了解更高级的索引技术,我建议你阅读我关于LSH的文章(https://pathway.com/developers/showcases/lsh/lsh_chapter2)。如果你想学习更实用的东西,并想体验实时检索增强生成(RAG)的实际应用,可以考虑探索LLM应用程序(https://github.com/pathwaycom/llm-app),在那里你可以亲身体验这些技术的力量。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:The Hidden World of (Vector) Indexes,作者:Olivier Ruas
链接:https://towardsdatascience.com/the-hidden-world-of-vector-indexes-f320a626c3dd。