各位朋友听我一句劝,写代码提供方法给别人调用时,不管是内部系统调用,还是外部系统调用,还是被动触发调用(比如MQ消费、回调执行等),一定要加上必要的条件校验。千万别信某些同事说的这个条件肯定会传、肯定有值、肯定不为空等等。这不,临过年了我就被坑了一波,弄了个生产事故,年终奖基本是凉了半截。
为了保障系统的高可用和稳定,我发誓以后只认代码不认人。文末总结了几个小教训,希望对你有帮助。

一、事发经过
我的业务场景是:业务A有改动时,发送MQ,然后应用自身接受到MQ后,再组合一些数据写入到Elasticsearch。以下是事发经过:
(1) 收到一个业务A的异常告警,当时的告警如下:
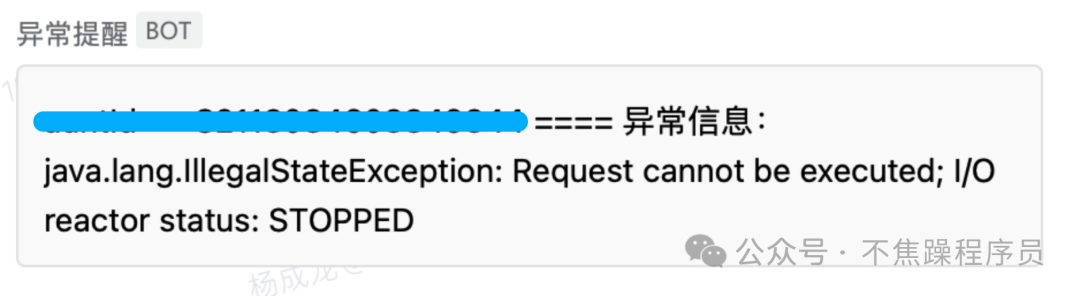
(2) 咋一看觉得有点奇怪,怎么会是Redis异常呢?然后自己连了下Redis没有问题,又看了下Redis集群,一切正常。所以就放过了,以为是偶然出现的网络问题。
(3) 然后技术问题群里 客服 反馈有部分用户使用异常,我警觉性的感觉到是系统出问题了。赶紧打开了系统,确实有偶发性的问题。
(4) 于是我习惯性的看了几个核心部件:
- 网关情况、核心业务Pod的负载情况、用户中心Pod的负载情况。
- Mysql的情况:内存、CPU、慢SQL、死锁、连接数等。
(5) 果然发现了慢SQL和元数据锁时间过长的情况。找到了一张大表的全表查询,数据太大,执行太慢,从而导致元数据锁持续时间太长,最终数据库连接数快被耗尽。
SELECT xxx,xxx,xxx,xxx FROM 一张大表(6) 立马Kill掉几个慢会话之后,发现系统仍然没有完全恢复,为啥呢?现在数据库已经正常了,怎么还没完全恢复呢?又继续看了应用监控,发现用户中心的10个Pod里有2个Pod异常了,CPU和内存都爆了。难怪使用时出现偶发性的异常呢。于是赶紧重启Pod,先把应用恢复。
(7) 问题找到了,接下来就继续排查为什么用户中心的Pod挂掉了。从以下几个怀疑点开始分析:
- 同步数据到Elasticsearch的代码是不是有问题,怎么会出现连不上Redis的情况呢?
- 会不会是异常过多,导致发送异常告警消息的线程池队列满了,然后就OOM?
- 哪里会对那张业务A的大表做不带条件的全表查询呢?
(8) 继续排查怀疑点a,刚开始以为:是拿不到Redis链接,导致异常进到了线程池队列,然后队列撑爆,导致OOM了。按照这个设想,修改了代码,升级,继续观察,依旧出现同样的慢SQL 和 用户中心被干爆的情况。因为没有异常了,所以怀疑点b也可以被排除了。
(9) 此时基本可以肯定是怀疑点c了,是哪里调用了业务A的大表的全表查询,然后导致用户中心的内存过大,JVM来不及回收,然后直接干爆了CPU。同时也是因为全表数据太大,导致查询时的元数据锁时间过长造成了连接不能够及时释放,最终几乎被耗尽。
(10) 于是修改了查询业务A的大表必要校验条件,重新部署上线观察。最终定位出了问题。
二、问题的原因
因为在变更业务B表时,需要发送MQ消息( 同步业务A表的数据到ES),接受到MQ消息后,查询业务A表相关连的数据,然后同步数据到Elasticsearch。
但是变更业务B表时,没有传业务A表需要的必要条件,同时我也没有校验必要条件,从而导致了对业务A的大表的全表扫描。因为:
某些同事说,“这个条件肯定会传、肯定有值、肯定不为空...”,结果我真信了他!!!由于业务B表当时变更频繁,发出和消费的MQ消息较多,触发了更多的业务A的大表全表扫描,进而导致了更多的Mysql元数据锁时间过长,最终连接数消耗过多。
同时每次都是把业务A的大表查询的结果返回到用户中心的内存中,从而触发了JVM垃圾回收,但是又回收不了,最终内存和CPU都被干爆了。
至于Redis拿不到连接的异常也只是个烟雾弹,因为发送和消费的MQ事件太多,瞬时间有少部分线程确实拿不到Redis连接。
最终我在消费MQ事件处的代码里增加了条件校验,同时也在查询业务A表处也增加了的必要条件校验,重新部署上线,问题解决。
三、总结教训
经过此事,我也总结了一些教训,与君共勉:
(1) 时刻警惕线上问题,一旦出现问题,千万不能放过,赶紧排查。不要再去怀疑网络抖动问题,大部分的问题,都跟网络无关。
(2) 业务大表自身要做好保护意识,查询处一定要增加必须条件校验。
(3) 消费MQ消息时,一定要做必要条件校验,不要相信任何信息来源。
(4) 千万别信某些同事说,“这个条件肯定会传、肯定有值、肯定不为空”等等。为了保障系统的高可用和稳定,咱们只认代码不认人。
(5) 一般出现问题时的排查顺序:
- 数据库的CPU、死锁、慢SQL。
- 应用的网关和核心部件的CPU、内存、日志。
(6) 业务的可观测性和告警必不可少,而且必须要全面,这样才能更快的发现问题和解决问题。