LLaVA(大型语言和视觉助理)(链接::https://llava-vl.github.io/)是一个很有前途的开源生成式人工智能模型,它复制了OpenAI GPT-4在图像转换方面的一些功能。用户可以将图像添加到LLaVA聊天对话中,允许讨论这些图像的内容,也可以将其用作以视觉方式描述想法、上下文或情况的一种方式。
LLaVA最引人注目的特点是它能够改进其他开源的解决方案,同时使用更简单的模型架构和数量级更少的训练数据。这些特性使LLaVA不仅训练更快、更便宜,而且更适合在消费类硬件上进行推理。
这篇文章旨在概述LLaVA的主要功能,更具体地说:
- 展示如何从Web界面进行实验,以及如何将其安装在您的计算机或笔记本电脑上。
- 解释其主要技术特征。
- 举例说明如何使用它进行编程,将使用Google Colab上的HuggingFace库(Transformers和Gradio)构建一个简单的聊天机器人应用程序。
在线使用LLaVA
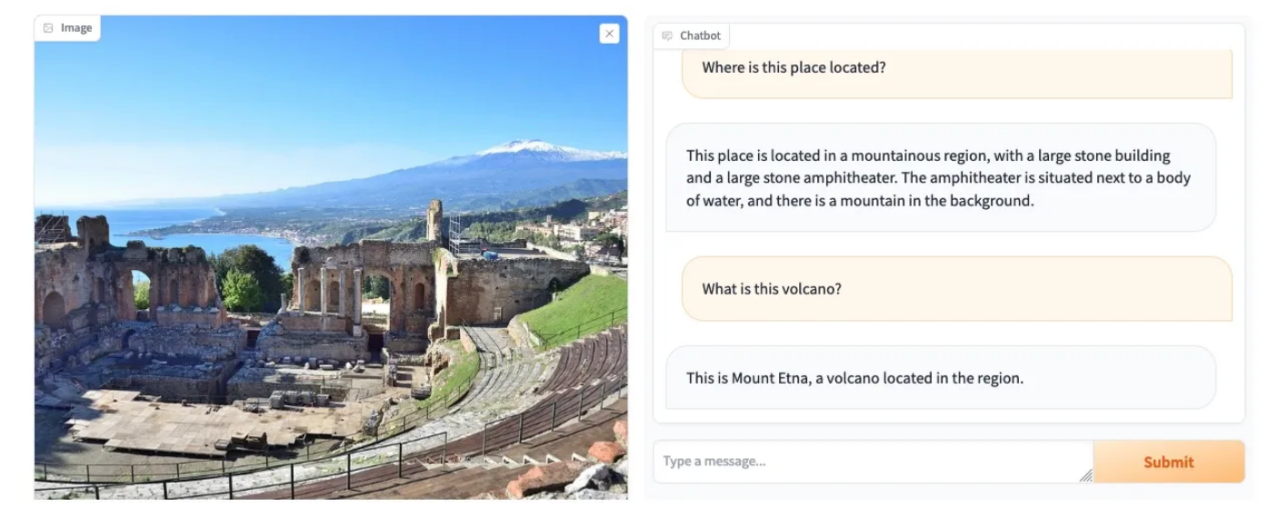
如果您还没有尝试过,那么使用LLaVA最简单的方法是转到其作者提供的Web界面(https://llava.hliu.cc/)。下面的屏幕截图展示了该界面的操作方式,用户在给出冰箱内容图片的情况下,询问该怎么吃。你可以使用界面中左侧的小部件加载图像,聊天界面允许以文本的形式提问和获得答案。
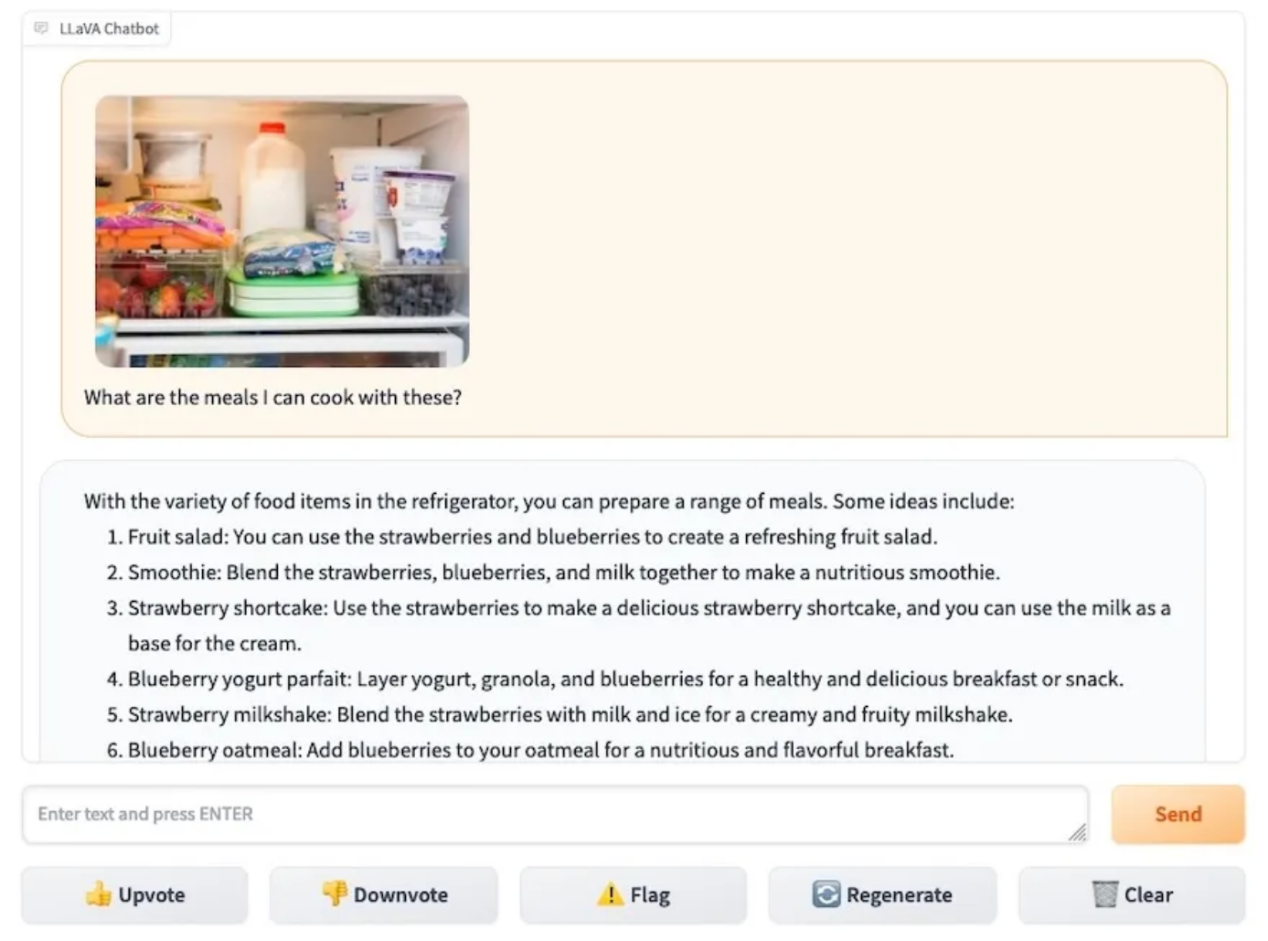
LLaVA Web界面
在这个例子中,LLaVA能够正确地识别冰箱中存在的成分,如蓝莓、草莓、胡萝卜、酸奶或牛奶,并提出了相关的想法,如水果沙拉、奶昔或蛋糕。
项目网站(https://llava-vl.github.io/)上还提供了与LLaVA对话的其他例子,这些例子表明LLaVA不仅能够描述图像,而且能够根据图像中的元素进行推断和推理(使用图片中的线索识别电影或人物,根据绘图对网站进行编码,解释幽默的情况,等等)。
本地运行LLaVA
LLaVA也可以借助于Ollama(https://ollama.ai/)或Mozilla的“llamafile”(https://github.com/Mozilla-Ocho/llamafile)安装在本地机器上。这些工具可以在大多数仅使用CPU的消费级机器上运行,因为该模型只需要8GB的RAM和4GB的可用磁盘空间,甚至可以在Raspberry PI上成功运行。在围绕Ollama项目开发的工具和界面中,一个值得注意的办法是Ollama WebUI(https://github.com/ollama-webui/ollama-webui,如下图所示),它再现了OpenAI ChatGPT用户界面的外观。
Ollama Web用户界面——灵感来自OpenAI ChatGPT
LLaVA主要功能概述
LLaVA由威斯康星大学麦迪逊分校、微软研究所和哥伦比亚大学的研究人员共同设计而成,最近在NeurIPS 2023上展出。该项目的代码和技术规范可以在其Github存储库(https://github.com/haotian-liu/LLaVA)中访问,该存储库还提供了与助理交互的各种接口。
正如作者在论文摘要(https://arxiv.org/pdf/2310.03744.pdf)中总结的那样:
“LLaVA在11个基准测试中达到了最先进的水平。我们的最终13B检查点仅使用了120万个公开可用的数据,并在单个8-A100级节点上在约1天内完成了完整的训练。我们希望这能使最先进的LMM研究更容易访问。有关研究代码和模型都将以开源方式发布。”
此论文中以雷达图的形式报告的基准结果说明了它与其他最先进的模型相比的改进情况。
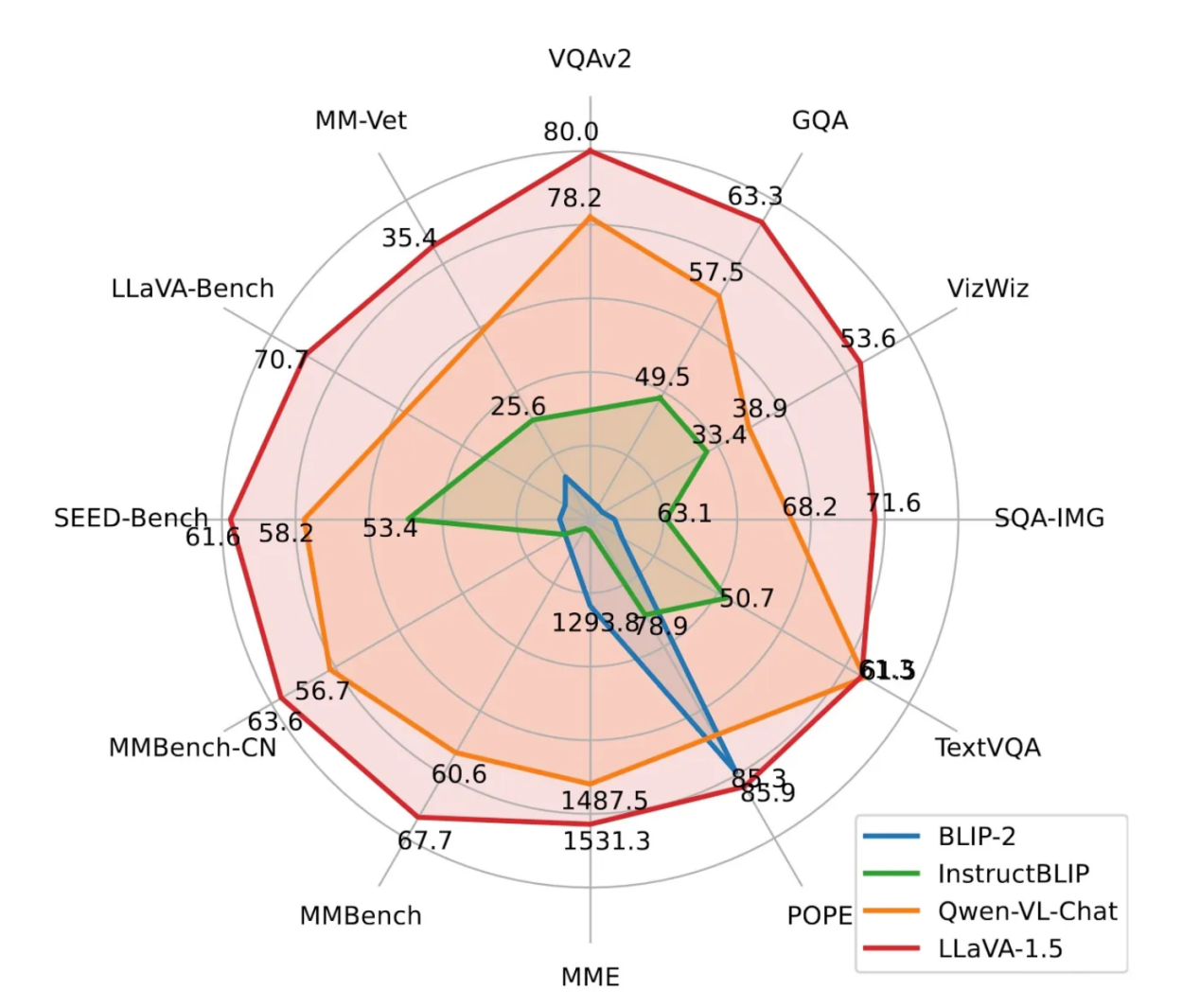
LLaVA基准结果雷达图(图片来自论文https://arxiv.org/pdf/2304.08485.pdf)
内部工作原理
LLaVA的数据处理工作流程在概念上很简单。该模型本质上是一个标准的因果语言模型,以语言指令(用户文本提示)为输入,并返回语言响应。语言模型处理图像的能力是由一个单独的视觉编码器模型所支持的,该模型将图像转换为语言标记,这些标记被“悄悄地”添加到用户文本提示中(充当一种软提示)。LLaVA的整体实现流程如下图所示:
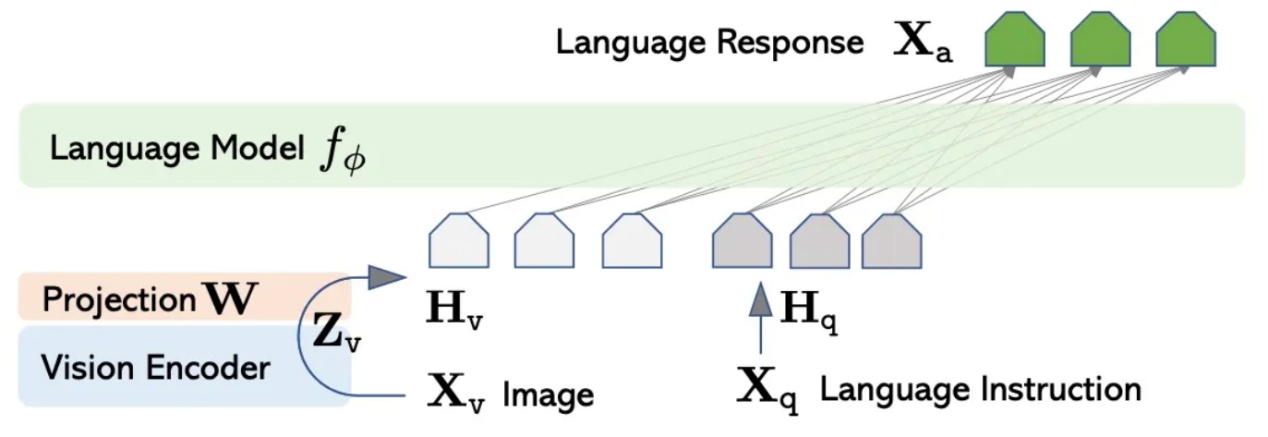
LLaVA网络架构(图片来自论文https://arxiv.org/pdf/2304.08485.pdf)
LLaVA的语言模型和视觉编码器分别依赖于两个参考模型,即Vicuna和CLIP。其中,Vicuna(https://lmsys.org/blog/2023-03-30-vicuna/)是一个基于LLaMA-2(由Meta设计)的预训练大型语言模型,具有与中等规模LLM竞争的性能(请参阅HuggingFace上的7B和13B版本的模型卡)。CLIP(https://openai.com/research/clip)是由OpenAI设计的图像编码器,使用对比语言图像预训练(因此称为“CLIP”)技术进行预训练,从而能够在类似的嵌入空间中对图像和文本进行编码。LLaVA中使用的模型是视觉转换器变体CLIP-ViT-L/14(请参阅HuggingFace上的模型卡:https://huggingface.co/openai/clip-vit-large-patch14)。
为了使视觉编码器的尺寸与语言模型的尺寸相匹配,应用了投影模块(上图中的W)。它实际上是原始LLaVA中的简单线性投影,以及LLaVA 1.5中的两层感知器。
训练过程
LLaVA的训练过程由两个相对简单的阶段组成。
第一阶段仅为了实现微调投影模块W,此阶段中视觉编码器和LLM的权重保持冻结。这个阶段使用来自CC3M概念字幕数据集(https://ai.google.com/research/ConceptualCaptions/)的约600k个图像/字幕对的子集进行训练,有关内容可在HuggingFace的存储库(https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K)上免费获得。
在第二阶段中,使用158K语言图像指令的数据集,将投影模块权重W与LLM权重一起微调(同时保持视觉编码器的权重冻结)。数据是使用GPT4生成的,具有对话示例、详细描述和复杂推理的功能,可在HuggingFace的存储库(https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K)上免费获得有关内容。
整个训练大约需要一天的时间,使用八个A100 GPU。
LLaVA基础编程
本部分相关代码可通过Colab相关笔记本文件(https://colab.research.google.com/drive/1L28bJX14-Y5lJvswYwydsletYFMIxVH5)获取。
LLaVA模型集成在Transformers库中,可以使用标准管道对象加载。模型的7B和13B变体均可免费从LLaVA存储库空间上获取,并且可以以4位和8位方式加载以节省GPU内存。接下来,我们将说明如何使用可在带有T4 TPU(15GB RAM GPU)的Colab上执行的代码加载和运行模型。
以下是用4位方式加载LLaVA 1.5的7B变体的代码片段:
然后,让我们加载此图片:

我们使用了标准的PIL库来加载图片:
最后,让我们用图像来查询LLaVA模型,并提示要求描述图片。
注意,提示的格式(https://huggingface.co/docs/transformers/model_doc/llava)如下:
相关代码如下:
返回了以下答案:
创建LLaVA聊天机器人
最后,让我们创建一个简单的依赖于LLaVA模型的聊天机器人。我们将使用Gradio库(https://www.gradio.app/),它提供了一种快速简便的方法来创建机器学习Web界面。
接口的核心由一行代码组成,该行包含一个图像上传组件(Gradio image对象)和一个聊天接口(Gradio ChatInterface对象:https://www.gradio.app/docs/chatinterface)。
聊天界面连接到函数update_conversation,该函数负责保存对话历史记录,并在用户发送消息时调用LLaVA模型进行响应。
下面的代码通过调用launch方法启动接口。
几秒钟后,聊天机器人Web界面即将出现:
祝贺您,您的LLaVA聊天机器人现已启动并成功运行!
注:除非另有说明;否则,文中所有图片均由作者本人提供。
参考文献
- HuggingFace LLaVA model documentation(HuggingFace LLaVA参考文档),https://huggingface.co/docs/transformers/model_doc/llava。
- Llava Hugging Face organization(Llava Hugging Face组织架构),https://huggingface.co/llava-hf。
- Loading and running LLaVA with AutoPrecessor and LLaVAForConditionalGeneration: Colab notebook(使用AutoPrecessor和LLaVAForConditionalGeneration加载和运行LLaVA),https://colab.research.google.com/drive/1_q7cOB-jCu3RExrkhrgewBR0qKjZr-Sx。
- GPT-4V(ision) system card(GPT-4V(vision)系统卡),https://cdn.openai.com/papers/GPTV_System_Card.pdf。
- Understanding Visual Instruction Tuning(了解可视化指令微调),https://newsletter.artofsaience.com/p/understanding-visual-instruction。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:LLaVA: An open-source alternative to GPT-4V(ision),作者:Yann-Aël Le Borgne
链接:https://towardsdatascience.com/llava-an-open-source-alternative-to-gpt-4v-ision-b06f88ce8efa。