2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。MoE 的广泛应用,使得在计算成本相对不变的条件下,模型容量能够得到显著扩展。此特性无疑使得 MoE 成为推动 LLM 发展的关键技术。
MoE 设计的初衷,是使模型的学习更加 “术业有专攻”,其有效性已得到业界肯定。然而现有 MoE 架构训练中的弊端也逐渐凸显,主要包括:专家负载失衡、专家内样本混杂而专家间同质化现象严重、额外的通信开销等等。
为了缓解现有 MoE 普遍存在的训练效率与性能瓶颈,专精于高性能计算、LLM 训练加速的华为 GTS AI 计算 Lab的研究团队提出了名为 LocMoE 的全新 MoE 架构,从路由机制角度出发,以期降低稀疏 LLM 训练成本的同时,提升其性能。

论文链接:https://arxiv.org/abs/2401.13920
论文简介
在这项工作中,作者发现之前的 MoE 路由机制往往会导致路由至同一专家网络的 token 差异较大,干扰专家网络的收敛;而路由至不同专家的 token 相似性较高,造成专家间同质化现象严重,最终影响模型语义理解与生成的能力。作者通过理论阐明了专家路由与输入数据特征之间的关联,并在 NLP 领域首次证明专家网络存在容量下限。在此理论基础上,专家路由的门控权重经正交化处理后,明显增强了专家网络间的区分度,处理远小于原先规模的 token,能够在领域评测中达到相近的效果。同时该研究针对 MoE 架构中固有的 All-To-All 通信瓶颈,结合负载 / 通信优化,提出高效高能的 MoE 架构。
具体来说,作者提出了一种名为 LocMoE 的新颖 MoE 架构,将其嵌入到盘古大模型的骨干中以增强其能力。LocMoE 旨在增强路由机制的可解释性,同时降低额外通信与计算开销。首先,作者发现 token 总倾向于路由至与该 token 夹角最小的专家,当专家间门控权重向量满足正交时,专家网络间处理的 token 能尽可能避免同质化。
因此,本文采用 GAP 层提取 token 特征,将其作为路由的依据。GAP 层特性上满足门控权重正交的条件,计算量相比 Dense 层也得到大幅下降。基于上述结构,作者通过理论求解出在不影响模型 loss 前提下,专家处理的 token 规模的下限,以降低专家网络的负载。此外,作者结合 auxiliary loss,提出了 locality loss 对路由进行软约束,降低跨机 All-To-All 通信开销。最后,采用通信遮掩等工程优化,进一步提升稀疏大模型整体的训练性能。
作者将 LocMoE 架构嵌入到盘古-Σ 38B 模型中,采用语义相似度较高的 ICT 领域数据进行训练,检验其领域知识的学习能力。在十项下游任务中,LocMoE 的准确性普遍高于原生盘古-Σ,训练性能每步提升 10%~20%。该 MoE 架构还具有较强的通用性和易于移植性,能够低成本嵌入到其他硬件规格和其他 MoE 架构的 LLM 骨干中。
当前,LocMoE 已部署至华为 ICT 服务领域专业知识问答应用 AskO3 上,AskO3 已上线华为 O3 知识社区,获得数万工程师用户群体广泛好评。
创新点剖析
路由与数据特征的关系
针对现有 MoE 路由机制普遍缺乏可解释性的问题,作者分析了 token 路由的本质,并设计了能够将 token 有效区分的结构。对于某个 token,学习性的路由策略普遍选择门控权重与该 token 乘积更大的专家进行分配:

那么,如果专家的门控权重满足正交,能够使得专家具备更高的判别性。同时,能够得出 token 倾向于被路由至与其夹角更小的专家:

作者最终选取 GAP 作为提取 token 特征的结构,其门控权重能够满足正交的条件:

上述路由机制的实质描述了路由判别能力与专家 token 间最小夹角之间的关联,如图所示。

图:LocMoE 路由机制示意图
专家容量下界
在上述理论的基础上,作者发现,专家容量存在下界,即,在输入数据确定的情况下,专家处理远小于经验值规模的 token,也能达到相当的性能。该问题可以转化为,求解使得至少一个具有类别判别性 token 被路由至某个专家的最小 token 规模,作为所有专家容量拉齐时的下界。同时能够得出,合理的专家容量与 token 和门控权重间的最小夹角呈负相关,并随着夹角的减小呈指数级增长。经实验证实,专家容量设为该下界时,未对模型收敛性和 loss 曲线产生影响。

本地性约束
LocMoE 在 MoE 层的 loss 包含两部分:auxiliary loss 和 locality loss。auxiliary loss 首次在 sparsely-gated MoE 中提出,同时应用于 SwitchTransformer,用以提升专家负载均衡性:

然而,跨机 All-To-All 带来的额外通信开销仍无法避免。因此,作者添加了本地性约束,使得在专家负载均衡的前提下,token 更倾向于被分派给本地设备的专家,最终达到约束平衡。locality loss 采用当前 token 分布与完全本地化分布之间的差异即 KL 散度来量化,从而将部分机间通信转为机内通信,充分利用机内互联高带宽。

实验结果
作者分别在包含 64 张、128 张和 256 张昇腾 910A NPU 的集群上进行了实验,主要与两款经典的 MoE 结构:Hash (来自 Facebook) 和 Switch (来自 Google) 进行比较。
训练效率
作者记录了各实验组训练过程中计算、通信、遮掩以及闲置的耗时。其中,在 64N 和 128N 的情况下,LocMoE 的计算开销和通信开销都是最低的。尽管 256N 时 LocMoE 的计算开销仍然最低,但部分设备不包含专家使得本地性通信转换失效,说明了 LocMoE 在计算及通信方面同时存在显著增益的适用条件是专家数至少大于等于节点数。

图:多种 MoE 结构在不同集群配置下的训练效率
专家负载
为了验证约束项对于专家负载的影响,作者分析了路由至每个专家的 token 分布情况。为了达到负载均衡,通过 RRE 模块实现的 Hash 路由采用静态路由表的硬约束确保分配的均衡性,LocMoE 和 Switch 则考虑到 token 的具体特征而进行路由。作为学习型路由,在 auxiliary 和本地性约束项的作用下,LocMoE 专家的均衡性明显优于 Switch,表现出稳定且较高的资源利用率。

图:多种 MoE 结构下专家负载情况
分配给专家的样本相似性
对于支撑 LocMoE 提出的关键理论,作者采用实验对其进行了验证。左图表明路由到同一专家的 token 相似性更高,接近于 1。右图则表明 token 与其路由至的专家对应的门控权重相似度分布相较其他专家更靠右,从而证实了 token 倾向于路由至与其夹角最小的专家的理论前提,并标记出专家容量下限求解的关键参数 δ。
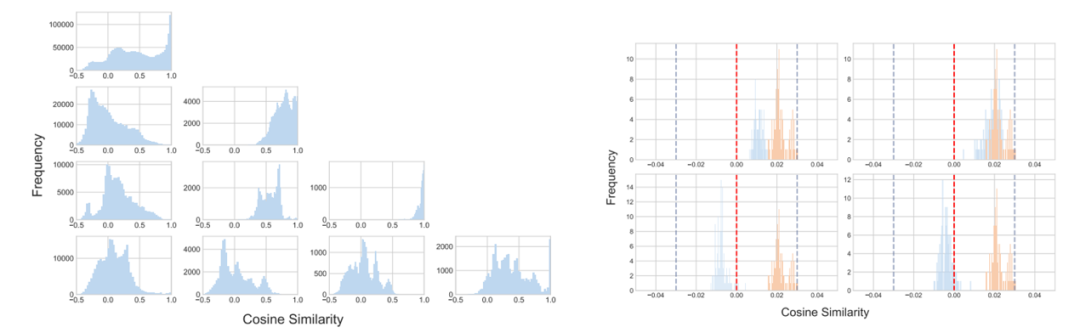
图:路由至同一 / 不同专家 token 相似性(左);token 与其路由至的专家的相似性(右)
NLP 领域下游任务
盘古-Σ 已经使用了来自金融、健康等超过 40 个领域的语料进行预训练,证明其从多领域文本数据中学习知识的能力。在本项工作中,作者使用 ICT 服务的领域数据,包含无线网络、光、运营商 IT 等产品线的技术报告和工具手册等,评估 LocMoE 在专业领域知识的学习表现。根据概念间逻辑复杂程度分为 L1 至 L3,梳理出十类 NLP 领域任务的评测数据集。与原生盘古-Σ 相比,LocMoE 使得模型语义理解和表达能力都有一定程度的提高。

图:与原生盘古-Σ 相比,NLP 领域下游任务表现