












近期,多模态大模型(LMMs)在视觉语言任务方面展示了令人印象深刻的能力。然而,由于多模态大模型的回答具有开放性,如何准确评估多模态大模型各个方面的性能成为一个迫切需要解决的问题。
目前,一些方法采用GPT对答案进行评分,但存在着不准确和主观性的问题。另外一些方法则通过判断题和多项选择题来评估多模态大模型的能力。
然而,判断题和选择题只是在一系列参考答案中选择最佳答案,不能准确反映多模态大模型完整识别图像中文本的能力,目前还缺乏针对多模态大模型光学字符识别(OCR)能力的专门评测基准。
近期,华中科技大学白翔团队联合华南理工大学、北京科技大学、中科院和微软研究院的研究人员对多模态大模型的OCR能力进行了深入的研究。
并在27个公有数据集和2个生成的无语义和对比的有语义的数据集上对文字识别、场景文本VQA、文档VQA、关键信息抽取和手写数学表达式识别这五个任务上进行了广泛的实验。

论文链接:https://arxiv.org/abs/2305.07895
代码地址:https://github.com/Yuliang-Liu/MultimodalOCR
为了方便而准确地评估多模态大模型的OCR能力,本文还进一步构建了用于验证多模态大模型零样本泛化能力的文字领域最全面的评估基准OCRBench,评测了谷歌Gemini,OpenAI GPT4V以及目前开源的多个类GPT4V多模态大模型,揭示了多模态大模型直接应用在OCR领域的局限。
评测模型概述
本文对谷歌Gemini,OpenAI GPT4V在内的14个多模态大模型进行了评估。
其中BLIP2引入了Q-Former连接视觉和语言模型;Flamingo和OpenFlamingo通过引入新颖的门控交叉注意力层,使得大语言模型具备理解视觉输入的能力;LLaVA开创性地使用GPT-4生成多模态指令跟随数据,其续作LLaVA1.5通过改进对齐层和prompt设计,进一步提升LLaVA的性能。
此外,mPLUG-Owl和mPLUG-Owl2强调了图像和文本的模态协作;LLaVAR收集了富文本的训练数据,并使用更高分辨率的CLIP作为视觉编码器,以增强LLaVA的OCR能力。
BLIVA结合指令感知特征和全局视觉特征来捕捉更丰富的图像信息;MiniGPT4V2在训练模型时为不同任务使用唯一的标识符,以便轻松区分每个任务的指令;UniDoc在大规模的指令跟踪数据集上进行统一的多模态指令微调,并利用任务之间的有益交互来提高单独任务的性能。
Docpedia直接在频域而不是像素空间中处理视觉输入。Monkey通过生成的详细描述数据和高分辨率的模型架构,低成本地提高了LMM的细节感知能力。
评测指标及评测数据集
LMM生成的回复通常包含许多解释性的话语,因此完全精确的匹配或平均归一化Levenshtein相似度(ANLS)在评估LMM在Zero-Shot场景中的表现时并不适用。
本文为所有数据集定义了一个统一而简单的评估标准,即判断LMM的输出是否包含了GT;为了减少假阳性,本文进一步过滤掉所有答案少于4个字符的问答对。
文本识别(Text Recognition)
本文使用广泛采用的OCR文本识别数据集评估LMM。这些数据集包括:
(1)常规文本识别:IIIT5K、SVT、IC13;
(2)不规则文本识别:IC15、SVTP、CT80、COCOText(COCO)、SCUT-CTW1500(CTW)、Total-Text(TT);
(3)遮挡场景下的文本识别,WOST和HOST;
(4)艺术字识别:WordArt;
(5)手写文本识别:IAM;
(6)中文识别:ReCTS;
(7)手写数字串识别:ORAND-CAR-2014(CAR-A);
(8)无语义文本(NST)和语义文本(ST):ST数据集包含3000张来自IIIT5K字典的单词图像,NST数据集与ST数据集的不同之处在于单词中字符的顺序被打乱而不具备语义。
对于英文单词识别,本文使用统一的prompt:「what is written in the image?」。对于ReCTS数据集中的中文文本则使用「What are the Chinese characters in the image?」作为prompt。对于手写数字串,则使用prompt:「what is the number in the image?」。
场景文本问答(Scene Text-Centric VQA)
本文在STVQA、TextVQA、OCRVQA和ESTVQA上进行了实验。其中ESTVQA数据集被分为ESTVQA(CN)和ESTVQA(EN),分别包含中文和英文问答对。
文档问答(Document-Oriented VQA)
本文在DocVQA、InfographicVQA和ChartQA数据集上进行评估,包括了扫描文档、复杂海报以及图表。
关键信息抽取(KIE)
本文在SROIE、FUNSD和POIE数据集上进行了实验,这些数据集包括收据、表单和产品营养成分标签。KIE要求从图像中提取key-value对。
为了使LMM能够准确提取KIE数据集中给定key的正确的value,本文针对不同数据集设计了不同prompt。
对于SROIE数据集,本文使用以下prompt帮助LMM为「company」,「date」,「address」和「total」生成相应的value:「what is the name of the company that issued this receipt?」、「when was this receipt issued?」、「where was this receipt issued?」和「what is the total amount of this receipt?」。
此外,为了获取FUNSD和POIE中给定key对应的value,本文使用prompt:「What is the value for '{key}'?」。
手写数学公式识别(HMER)
评估了 HME100K数据集,在评估过程中,本文使用「Please write out the expression of the formula in the image using LaTeX format.」作为prompt。
评测结果
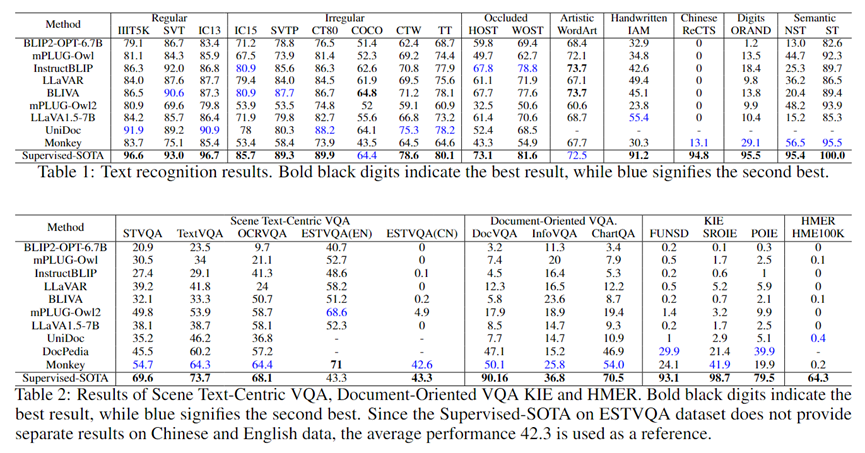
LMM在识别常规文本、不规则文本、遮挡场景下的文本和艺术字方面取得了与Supervised-SOTA相媲美的性能。
InstructBLIP2和BLIVA在WordArt数据集中的性能甚至超过了Supervised-SOTA,但LMM仍然存在较大局限。
语义依赖
LMMs在识别缺乏语义的字符组合时表现出较差的识别性能。
具体而言,LMMs在NST数据集上的准确率相比于ST数据集平均下降了57.0%,而Supervised-SOTA只下降了约4.6%。
这是因为场景文本识别的Supervised-SOTA直接识别每个字符,语义信息仅用于辅助识别过程,而LMMs主要依赖语义理解来识别单词。
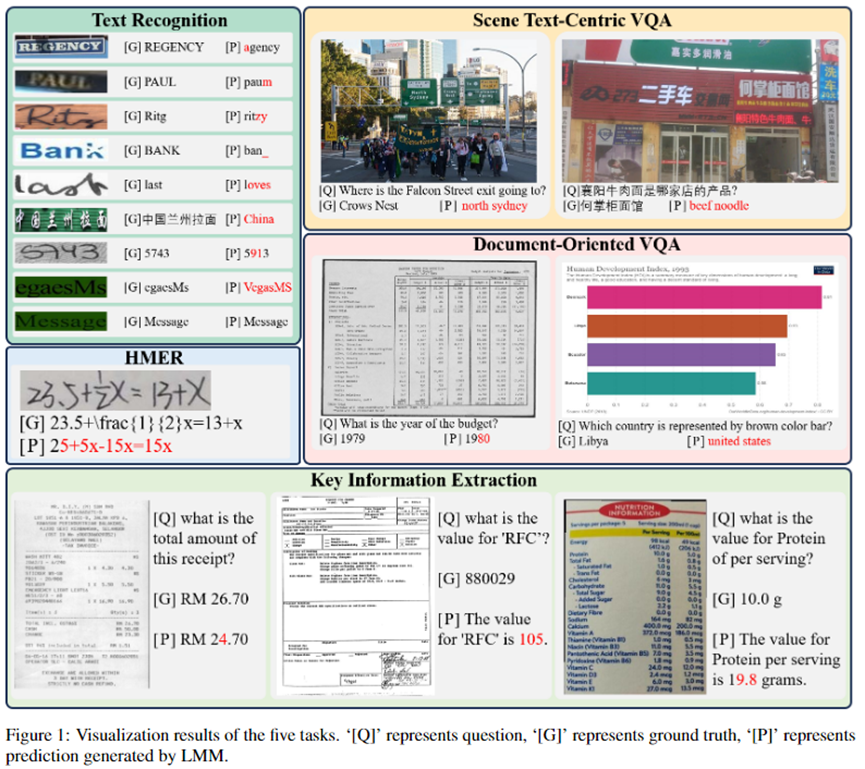
例如Figure1中,LMM成功识别了单词「Message」,但错误地识别了「egaesMs」,这只是单词「Message」的重新排序。
- 手写文本
LMMs在准确识别手写文本方面存在挑战。手写文本通常因快速书写、不规则手写或低质量纸张等因素而显得不完整或模糊。平均而言,LMMs在这项任务中的性能比Supervised-SOTA差了51.9%。
- 多语言文本
在ReCTS、ESTVQA(En)和ESTVQA(Ch)上观察到的显著性能差距展示了LMMs在中文文本识别和问答方面的不足。这可能是由于中文训练数据的缺少导致的。而Monkey的语言模型和视觉编码器都经过大量中文数据的训练,因此它在中文场景中表现优于其他多模态大模型。
- 细粒度感知
目前,大多数LMMs的输入图像分辨率受限于224 x 224,与它们架构中使用的视觉编码器的输入尺寸一致。然而,高分辨率的输入图像可以捕捉到更多的图像细节,从而提供更细粒度的信息。由于BLIP2等LMMs的输入分辨率受限,它们在场景文本问答、文档问答和关键信息抽取等任务中提取细粒度信息的能力较弱。相比之下,Monkey和 DocPedia等具有更高输入分辨率的多模态大模型在这些任务中具有更好的表现。
- HMER
LMMs在识别手写数学表达式方面存在极大的挑战。这主要是由于杂乱的手写字符、复杂的空间结构、间接的LaTeX表示以及训练数据的缺乏所导致的。
OCRBench
完整地评估所有数据集可能非常耗时,而且一些数据集中的不准确标注使得基于准确率的评估不够精确。
鉴于这些限制,本文进一步构建了OCRBench,以方便而准确地评估LMMs的OCR能力。

OCRBench包含了来自文本识别、场景文本问答、文档问答、关键信息抽取和手写数学表达式识别这五个任务的1000个问题-答案对。
对于KIE任务,本文还在提示中进一步添加了「Answer this question using the text in the image directly.」来限制模型的回答格式。
为了确保更准确的评估,本文对OCRBench中的1000个问答对进行了人工校验,修正了错误选项,并提供了正确答案的其他候选。
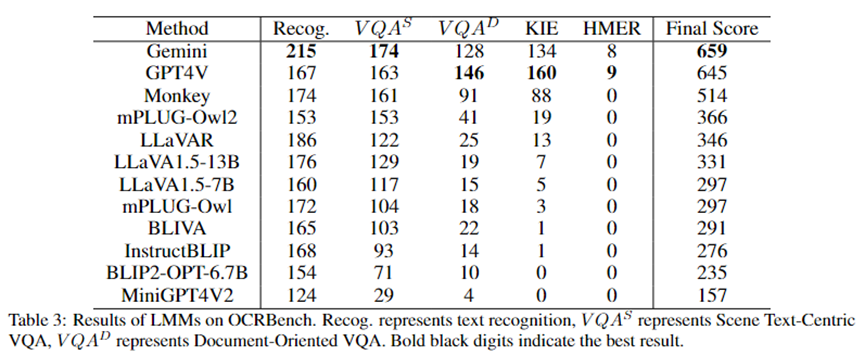
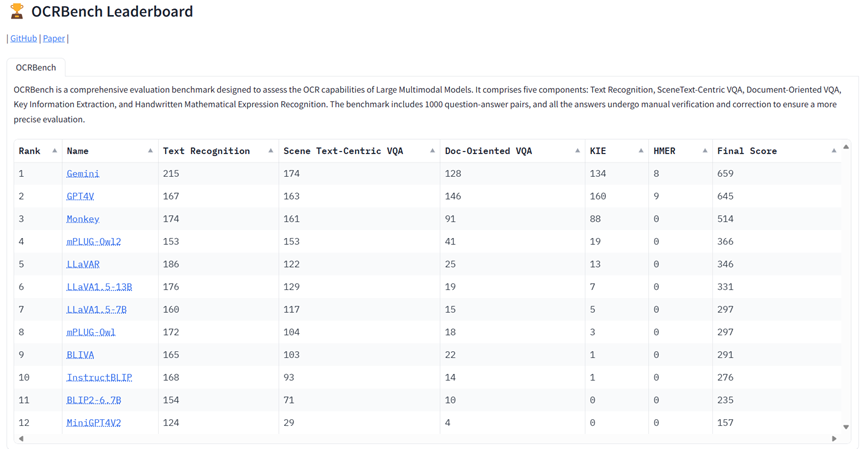
其结果如Table 3所示,Gemini获得了最高分,GPT4V获得了第二名。需要注意的是,由于OpenAI进行了严格的安全审查,GPT4V拒绝为OCRBench中的84张图像提供结果。
Monkey展示了仅次于GPT4V和Gemini的OCR能力。从测试结果中,我们可以观察到,即便是GPT4V和Gemini这样最先进的多模态大模型在HMER任务上也面临困难。
此外,它们在处理模糊图像、手写文本、无语义文本和遵循任务指令方面也存在挑战。
正如图2(g)所示,即使明确要求使用图像中的文本回答,Gemini仍将「02/02/2018」解释为「2 February 2018」。
总结
本文对LMMs在OCR任务中的性能进行了广泛的研究,包括文本识别、场景文本问答、文档问答、KIE和HMER。
本文的定量评估显示,LMM可以取得有希望的结果,特别是在文本识别方面,在某些数据集上甚至达到了SOTA。
然而,与针对特定领域的监督方法相比,仍然存在显著差距,这表明针对每个任务定制的专门技术仍然是必不可少的,因为后者使用的计算资源和数据要少得多。
本文所提出的OCRBench为评估多模态大模型的OCR能力提供了基准,揭示了多模态大模型直接运用于OCR领域的局限。
本文还为OCRBench构建了一个在线排行榜,用于展示和比较不同多模态大模型的OCR能力(加入排行榜的方式参考Github)。





























