












无注意力大模型Eagle7B:基于RWKV,推理成本降低10-100 倍
在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。
与大模型相比,小模型具有很多优点,比如对算力的要求低、可在端侧运行等。
近日,又有一个新的语言模型出现了,即 7.52B 参数 Eagle 7B,来自开源非盈利组织 RWKV,其具有以下特点:

- 基于 RWKV-v5 架构构建,该架构的推理成本较低(RWKV 是一个线性 transformer,推理成本降低 10-100 倍以上);
- 在 100 多种语言、1.1 万亿 token 上训练而成;
- 在多语言基准测试中优于所有的 7B 类模型;
- 在英语评测中,Eagle 7B 性能接近 Falcon (1.5T)、LLaMA2 (2T)、Mistral;
- 英语评测中与 MPT-7B (1T) 相当;
- 没有注意力的 Transformer。

前面我们已经了解到 Eagle 7B 是基于 RWKV-v5 架构构建而成,RWKV(Receptance Weighted Key Value)是一种新颖的架构,有效地结合了 RNN 和 Transformer 的优点,同时规避了两者的缺点。该架构设计精良,能够缓解 Transformer 所带来的内存瓶颈和二次方扩展问题,实现更有效的线性扩展,同时保留了使 Transformer 在这个领域占主导的一些性质。
目前 RWKV 已经迭代到第六代 RWKV-6,由于 RWKV 的性能与大小相似的 Transformer 相当,未来研究者可以利用这种架构创建更高效的模型。
关于 RWKV 更多信息,大家可以参考「Transformer 时代重塑 RNN,RWKV 将非 Transformer 架构扩展到数百亿参数」。
值得一提的是,RWKV-v5 Eagle 7B 可以不受限制地供个人或商业使用。
在 23 种语言上的测试结果
不同模型在多语言上的性能如下所示,测试基准包括 xLAMBDA、xStoryCloze、xWinograd、xCopa。


共 23 种语言
这些基准测试包含了大部分常识推理,显示出 RWKV 架构从 v4 到 v5 在多语言性能上的巨大飞跃。不过由于缺乏多语言基准,该研究只能测试其在 23 种较常用语言上的能力,其余 75 种以上语言的能力目前仍无法得知。
在英语上的性能
不同模型在英语上的性能通过 12 个基准来判别,包括常识性推理和世界知识。

从结果可以再次看出 RWKV 从 v4 到 v5 架构的巨大飞跃。v4 之前输给了 1T token 的 MPT-7b,但 v5 却在基准测试中开始追上来,在某些情况下(甚至在某些基准测试 LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq 上)它可以超过 Falcon,甚至 llama2。
此外,根据给定的近似 token 训练统计,v5 性能开始与预期的 Transformer 性能水平保持一致。
此前,Mistral-7B 利用 2-7 万亿 Token 的训练方法在 7B 规模的模型上保持领先。该研究希望缩小这一差距,使得 RWKV-v5 Eagle 7B 超越 llama2 性能并达到 Mistral 的水平。
下图表明,RWKV-v5 Eagle 7B 在 3000 亿 token 点附近的 checkpoints 显示出与 pythia-6.9b 类似的性能:
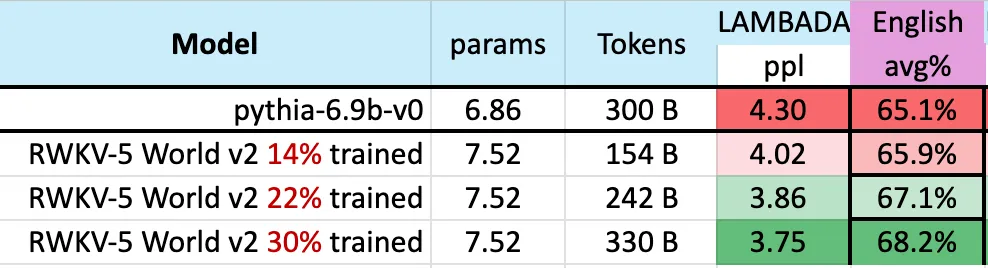
这与之前在 RWKV-v4 架构上进行的实验(pile-based)一致,像 RWKV 这样的线性 transformers 在性能水平上与 transformers 相似,并且具有相同的 token 数训练。
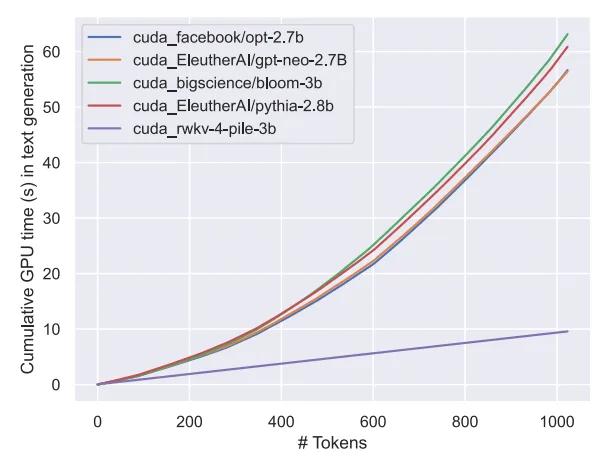
可以预见,该模型的出现标志着迄今为止最强的线性 transformer(就评估基准而言)已经来了。





























