你可以将本文作为开发者快速了解 Kubernetes 的指南。从基础知识到更高级的主题,如 Helm Chart,以及所有这些如何影响你作为开发者。
译自Kubernetes for Lazy Developers。作者 marcobehler 。
介绍
如果你是一位开发者,要么从未使用过 Kubernetes,要么想要复习 Kubernetes 知识,以便让你的 DevOps 同事对你刮目相看,那么这份指南适合你。
快速问题:为什么将 Kubernetes 缩写为 K8s?
答案:它将在本指南末尾神奇地揭示,但仅在你完全阅读完之后。所以,让我们不再浪费时间。
我们是如何到达这里的?
我在整个职业生涯中遇到的许多开发者,对于他们应用程序生命周期的“现在我已经编写了代码,它还需要在某个地方运行”的部分并不一定关心。(根据你的公司对 DevOps 这个词的定义和认知程度,这可能有所不同)。
但让我们慢慢开始。运行一个应用程序实际上意味着什么?
这在一定程度上取决于你所使用的编程语言生态系统。例如,在Java和现代Web应用程序方面,你可以将所有源代码编译成一个单一的可执行 .jar 文件,然后通过简单的命令运行它。
对于生产部署,通常你也会希望有一些属性,用于设置数据库凭据或其他秘密。在上述的Java Spring Boot情况下,最简单的方式是拥有一个application.properties文件,但你也可以使用外部的秘密管理服务。
无论如何,上述的命令实际上是你需要运行的所有内容,用于部署你的应用程序 - 无论你是在裸金属上、虚拟机上、Docker容器中、有或没有Kubernetes,甚至是你的Java驱动的烤面包机。
仅运行一个命令肯定不够。哪里是问题的瓶颈?
关于部署应用程序时可能出现的问题已经在网络上写了很多:
- 如果我的DEV环境和PRD环境之间存在库/操作系统/基础设施/某些版本不兼容怎么办?
- 如果某些必需的操作系统软件包丢失了怎么办?
- 如果我们不想将应用程序部署到云服务,而是部署到潜水艇上怎么办?
对于这些问题,根据你使用的编程语言生态系统,解决方法可能会有很大的不同 - 这是在线讨论中经常被忽视的一个主题。
对于纯粹的Java Web应用程序,上述提到的问题(不包括潜水艇或更明智的基础设施部分,比如你的数据库),在很大程度上并不是问题。你在服务器/虚拟机/容器/潜水艇上安装JDK,运行java -jar,然后幸福地生活在一起。
对于PHP、Python、咳咳,Node,情况就不同了,你很容易在开发、测试或生产环境之间遇到版本不兼容的问题。因此,人们渴望一种解决方案来摆脱这些烦恼:容器。
Docker、Docker Compose和Swarm:回顾
向Docker致敬!
很有可能你已经知道Docker是什么,以及如何使用它。(如果不知道,并且想看一个特定于Docker的指南,请在下面评论!需求越多 → 发布越快)。简短的总结是:
- 你将源代码构建为可部署的文件,例如jar文件。
- 你另外构建一个新的Docker镜像,其中包含你的jar文件。
- 该Docker镜像还包含运行成功所需的所有附加软件和配置选项。
→ 你不再部署你的.jar文件,而是部署你的Docker镜像并运行Docker容器。
这样做的美妙之处在于:只要在目标机器上安装了Docker(并且你的主机操作系统与Docker容器兼容内核),你就可以运行任何Docker镜像。
什么是 'deploying' Docker 镜像?
你或者你的 CI/CD 服务器设法将你的应用程序制作成了一个 Docker 镜像。但是这个 Docker 镜像最终是如何在目标部署服务器上运行的呢?
你理论上可以将 Docker 镜像保存为 .tar 文件,复制到最终服务器上并在那里加载它。但更现实的情况是,你会将 Docker 镜像推送到一个 Docker Registry,无论是dockerhub、Amazon ECR还是其他像GitLab的数不胜数的自托管容器 Registry 之一。
一旦你的镜像成功上传到 Registry,你可以在目标服务器上登录到该注册表。
一旦你在 Registry 上登录成功,你的 docker run 就能找到你的自定义镜像了。
Docker Compose:同时运行多个容器
如果你的应用程序不仅仅包含一个单独的 Docker 容器,比如说,因为你需要运行98354 个微服务?
Docker Compose 来拯救。你将在一个传统而又经典的 YAML 文件,即compose.yaml文件中定义所有服务及其之间的依赖关系(运行这个或那个先)。以下是一个定义两个服务的示例,一个是 Web 服务,另一个是 Redis 服务。
然后只需运行docker compose up,整个环境(由所有独立服务在单独的 Docker 容器中运行组成)将被启动。请注意,这意味着所有容器将在同一台机器上运行。如果要将其扩展到多台机器上,您将需要使用Docker Swarm。
虽然Docker Compose可能主要用于快速启动开发或测试环境,但它实际上也适用于(单主机)生产部署。如果你的应用程序…
- 没有特定的高可用性要求
- 你不介意一些手动操作(ssh 登录,docker compose up/down)或使用辅助工具如Ansible
- 或者你只是不想在 DevOps 团队上投入巨额资金
…使用 Docker Compose 进行生产部署将大有裨益。
Kubernetes 101: 基础和概念
那么我为什么需要 Kubernetes 呢?
当你想要开始运行数百、数千(或是它们的倍数)的容器时,事情变得有趣起来。如果你不关心或者不想知道这些容器将在哪台具体的硬件/主机上运行,但仍然希望能够合理地管理所有这些,那么 Kubernetes 就派上用场了!
(注:相当长时间以前,我读过一本关于 Kubernetes 的书,在介绍中他们规定了运行 Kubernetes 开始变得有意义的下限数字,我记得它从数百到数千开始,尽管我无法找到那本确切的书了。)
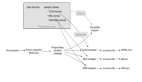
让我们快速了解一下 Kubernetes 的基础概念。
 图片
图片
(工作,Worker)节点
你的软件(或者在 Kubernetes 术语中称为工作负载)必须在某个地方运行,无论是虚拟机还是物理机器。在 Kubernetes 中,这个地方被称为节点(Node)。
此外,Kubernetes 部署和运行容器:你好,Docker,我的老朋友!(注:Kubernetes 支持许多容器运行时,包括containerd、CRI-O、Docker Engine等,尽管 Docker 是最常用的)
实际上,这并不完全正确。在 Kubernetes 的术语中,你部署(调度)Pods,一个 Pod 包含一个或多个容器。
好吧,我们在节点上运行Pods,但是谁控制这些节点,以及你在这些节点上如何决定运行什么呢?
(小贴士:一个小映射表)
非 Kubernetes | Kubernetes 术语 |
软件/应用 | 工作负载 |
机器 | 节点 |
(1-多个)容器 | Pod |
部署 | 调度 |
控制平面
认识控制平面。为简单起见,我们可以将其视为控制节点的一个组件(与其包含的大约 9472 个组件相对)。控制平面,除了其他许多功能…
- 让你运行调度你的应用程序,即让你将一个 Pod 放到一个节点上。
- 检查所有的 Pod 是否处于期望的状态,例如它们是否响应,或者其中一个是否需要重新启动?
- 实现每个工程师的幻想:“我们终于需要扩展 10 倍了,让我们快速启动 n 个更多的 Pod!”
Pods 与 Nodes
如果Pods和Nodes之间的区别还有点不清楚。Kubernetes 有一个所谓的调度器。每当调度器发现新的 Pod(== 容器(们))需要调度时(耶!),它会尝试找到 Pod 的最佳节点。这意味着很有可能多个 Pod 在同一节点上运行,或者在不同节点上运行。如果你想深入了解这个主题,你可能需要阅读有关 "节点选择" 以及如何影响它的官方文档。
集群 & 云
取多个节点和你的控制平面,你就有了一个集群。
取多个集群,你可以分隔你的开发、测试和生产环境,或者团队、项目或不同类型的应用程序 - 这取决于你。
再进一步,尝试进行多云 Kubernetes,跨越不同的私有和/或公有云平台运行多个集群(祝贺!你所取得的成就绝非易事。)
扩展
还有许多Kubernetes 扩展。
最重要的是,对于开发人员来说,有一个Web UI/Dashboard,你可以使用它来基本管理你的集群。
如果你没有自托管你的 Kubernetes 设置,你可以简单地使用云供应商提供的任何 UI,比如Google Cloud、AWS或其他众多云供应商提供的 UI。
请,让我们停止 Kubernetes 101
上面的那四个 101 部分将(希望)为你提供足够的心智模型,让你开始使用 Kubernetes,我们将在概念上结束。
说实话,如果你在https://learning.oreilly.com上搜索 "Kubernetes",你会感到震惊。你将获得成千上万的学习资源结果,其中许多书籍都超过 500 页长。这对于一个下雨天的冬天是很好的阅读!好消息是:作为开发人员,你不必关心这些书中大多数内容,这些书教你如何设置、维护和管理你的集群,尽管了解所有这些的复杂性是有帮助的。
我需要做什么才能看到所有这些在运行中的情况?
- Kubernetes 安装(我们稍后会更详细地讨论)
- YAML,YAML,YAML!
- 与你的 Kubernetes 集群交互的工具:kubectl
我从哪里获取 kubectl?
你可以下载kubectl,这本质上是用于与你的 Kubernetes 集群做任何你想做的事情的 CLI工具。该页面列出了为你的特定操作系统安装 kubectl 的各种方法。
我如何读 kubectl?†
参见https://www.youtube.com/watch?v=9oCVGs2oz28。它的发音是 "Kube Control"。
kubectl 要如何工作?
你需要一个配置文件,一个名为 kubeconfig 的文件,它允许你访问你的 Kubernetes 集群。
默认情况下,该文件位于~/.kube/config。值得注意的是,这个配置文件也被你喜爱的集成开发环境(如IntelliJ IDEA)读取,以正确设置其 Kubernetes 功能。
我从哪里获取 kubeconfig 文件?
选项 1如果你正在使用托管的 Kubernetes 安装(EKS、GKE、AKS),请查看相应的文档页面。是的,只需点击链接,我已经为你链接到正确的页面。简而言之,你将使用它们的 CLI 工具为你生成/下载该文件。
选项 2如果你本地安装了Minikube,它将自动为你创建一个 kubeconfig 文件。
选项 3如果你碰巧知道你的 Kubernetes 主节点并可以通过 SSH 登录,运行:cat /etc/kubernetes/admin.conf或cat ~/.kube/config
kubeconfig 文件还有其他需要知道的吗?
一个 kubeconfig 文件由传统的 YAML 组成,它可以包含许多内容(clusters、users、contexts)。对于有兴趣的人,请查阅官方文档。
目前,我们可以忽略 users 和 contexts,并且简化为 kubeconfig 文件包含你可以连接的集群,例如development或test。
以下是一个示例 kubeconfig 文件,摘自官方 Kubernetes 文档。
(别担心,你不必逐行理解这个文件,它只是为了让你感受一下这些文件的样子)
Kubectl 101
你现在可以用 Kubectl 做什么呢?记住,一开始我们说你的目标是拥有一个 Pod(n+ 个容器),并在节点(服务器)上调度它(运行它们)。
方法是将 yaml 文件(耶)带有集群期望状态的文件输入到 kubectl 中,它将愉快地将你的集群设置为期望的状态。
Pod 清单
例如,你可以创建一个名为marcocodes-pod.yaml的文件,内容如下…
…并使用以下 kubectl 命令将其输入到你的 Kubernetes 集群中:
应用这个 yaml 文件会做什么呢?嗯,让我们逐步了解:
Kubernetes 知道各种所谓的对象,Pod 是其中之一,你稍后会遇到其他对象。简单来说,这个 .yaml 文件描述了我们要部署的 Pod。
Kubernetes 中的每个对象,因此每个 .yaml 文件都充满了metadata标签。在这种情况下,我们为我们的 pod 指定了名称,值为marcocodes_web。这个 metadata 有什么用呢?简单来说,Kubernetes 需要以某种方式唯一标识集群中的资源:我是否已经运行了一个名称为marcocodes_web的 pod,还是我需要启动一个新的 pod?这就是 metadata 的作用。
你需要告诉 Kubernetes 你的 pod 应该是什么样的。记住,它可以是 n+ 个容器,因此你可以在 YAML 文件中指定容器的列表,尽管通常你只指定一个。
你将指定一个特定的 Docker 镜像,包括其版本,并通过 http 在该容器上暴露端口 8080。就是这样。
这个 yaml 文件到底发生了什么?
长话短说,当你运行 kubectl apply 时,你的 yaml 文件将被提交到 Kubernetes API 服务器,最终我们的 Kubernetes 系统将安排一个 pod(带有 marcocodes 1.4 容器)在我们集群中的一台健康、可行的节点上运行。
更技术性地说,Kubernetes 有一个协调循环的概念,一个调度器能够说的花哨点的术语:
"这是我的当前 Kubernetes 集群状态,这是用户的 yaml 文件,让我协调这两者。用户想要一个新的 pod 吗?我会创建它。用户想要存储吗?我会将其附加到容器上,等等。
说到存储...
资源和卷
仅指定容器镜像并不是你所能做的全部。首先,你可能想要处理容器的资源消耗:
这确保你的容器至少获得 500m(即 0.5)的 CPU 和 128 MB 的内存(你还可以指定永远不可突破的上限)。
此外,当一个 pod 被删除或容器重新启动时,容器文件系统中的数据也将被删除。为了避免这种情况,你可能想要将数据存储在持久卷上。
我们将拥有一个名为marcocodes-data的卷,它将被挂载到容器上的/data目录下,并存在于主机机器上的/var/lib/marcocodes下。
有什么要注意的吗?
你刚学到有 pod,它们由一个或多个 Docker 镜像组成,以及资源消耗规则和卷定义。
有了所有这些 YAML,我们成功地安排了一个单一的、静态的、一次性的 pod。问题来了:与仅运行docker run -d --publish 8080:8080 gcr.io/marco/marcocodes:1.4相比,有何优势?
嗯,实际上目前并没有。
这就是为什么我们需要更深入地了解ReplicaSet和Deployment概念的原因。
ReplicaSet
我们要谦卑一点。一开始我们不需要自动缩放,但拥有应用程序的冗余实例和一些负载平衡会很不错,这样我们的部署会显得更专业,不是吗?
Kubernetes 的ReplicaSet来拯救我们!
让我们看一个定义了这样一个最小 ReplicaSet 的marcocodes-replica.yaml文件。
我省略了这个 YAML 文件中的很多行(和复杂性),但现在最有趣的是这两个变化:
这个 .yaml 现在描述的是一个 ReplicaSet,而不再是一个 Pod。
这是重点:我们希望始终有 2 个副本 == pod 在任何给定的时间运行。如果我们在这里填入 10,Kubernetes 将确保同时运行 10 个 pod。
当我们现在应用这个 .yaml 文件...
Kubernetes 将从 Kubernetes API 获取一个 Pod 清单(并根据metadata过滤结果),根据返回的 pod 数量,Kubernetes 将启动或停止额外的副本。就是这么简单。
ReplicaSet:总结
ReplicaSet几乎是你想要的,但它们存在一个问题:它们与特定版本的容器镜像绑定(在我们的例子中为 3.85),而这些实际上不应该更改。而且 ReplicaSets 也不能帮助你完成软件的滚动发布过程(考虑零停机时间)。
因此,我们需要一个新的概念来帮助我们管理新版本的发布。见识一下:Deployment(部署)。
你还需要学习 Deployments 的其他 92387 个 YAML 键值对,而我们已经在本文中进行了相当长时间的探讨。其要点是:Kubernetes 允许你使用不同的软件发布策略(rollingUpdate或recreate)。
- Recreate(重新创建)将终止所有旧版本的 pod,并使用新版本重新创建它们:这会导致用户经历停机时间。
- RollingUpdate(滚动更新)将在仍然通过旧 pod 提供流量的情况下执行更新,因此通常更受青睐。
K8s 的静态本质
请注意,到目前为止,你所看到的一切基本上是静态的。你有 YAML 文件,即使使用上面的 Deployment 对象,如果你有一个新版本的容器,你需要编辑 .yaml 文件,保存并应用它 - 这涉及相当多的手动工作。
如果你希望事情变得更加动态,你将需要使用额外的工具,比如https://helm.sh/,我们将在下面讨论。
滚动更新:过于美好而不真实
虽然我们正在谈论部署容器的新版本...
一如既往,魔鬼在细节中。滚动更新在 Kubernetes 存在之前很久就已经完成了,即使只是批处理脚本触发 SSH 命令。
坦率地说,问题并不是能够关闭并启动应用程序的新实例,而是在短时间内(在部署期间)你的应用程序基本上需要优雅地支持两个应用程序版本 - 这总是一个有趣的问题,特别是涉及数据库或前后端 API 之间进行了重大重构的情况。
因此,请注意营销材料,它们向你推销简单的滚动更新 - 它们真正的挑战与 Kubernetes 无关。
附注:自愈能力
在类似的背景下,同样适用于“self-healing”(自愈)一词。Kubernetes 能够执行健康检查,然后终止无响应的 pod,安排启动一个新的。这也是某种形式上一直存在的功能。你喜欢的 Linux 发行版本质上一直能够通过各种方式监视并重新启动服务 - 尽管限于当前机器。
Kubernetes 不能自动处理错误的数据库迁移导致的应用程序错误,然后通过神奇的方式自愈集群,即修复损坏的数据库列。
我只是觉得关于自愈系统的讨论通常在某种程度上含有后者的意味(也许在管理层之间),而实际上它是更基本的功能。
服务发现、负载均衡和 Ingress
到目前为止,我们讨论了动态生成 pod,但从未讨论过网络流量如何实际到达你的应用程序。Kubernetes 本质上是动态的,这意味着你可以在任何时候生成新的 pod 或关闭它们。
Kubernetes 有一些概念可以帮助你解决这个问题,从 Service 对象(允许将集群的部分暴露给外部)到 Ingress 对象(允许进行 HTTP 负载均衡)。同样,这将涉及大量的 YAML 和相当多的阅读,但在一天结束时,Kubernetes 允许你将应用程序接收到的任何流量路由到你的集群,反之亦然。
(有趣的 Ingress 事实:您将需要安装 Ingress 控制器(Kubernetes 没有内置标准控制器),它将为您执行负载平衡。选择很多:在像 AWS 这样的平台上,您可以简单地使用 ELB,如果使用裸金属 Kubernetes,则可以使用Contour,等等。)
最后但同样重要的是:ConfigMap 和 Secret 管理
除了您已经看到 Kubernetes 执行的各种任务之外,您还可以使用它存储配置键值对,以及秘密(考虑数据库或 API 凭据)。
(默认情况下,Secrets 以未加密的形式存储,因此有必要遵循此页面上“安全使用 Secrets” 部分的建议,甚至可以完全插入外部 Secrets 存储,从 AWS、GCP 和 Azure 的解决方案到HashiCorp 的 Vault。)
够了!这些 YAML 文件难道不会变得混乱吗?
嗯...如果您考虑使用 Kubernetes 部署WordPress等应用,那么您将需要一个 Deployment,以及一个ConfigMap和可能还有Secret。然后还有一些其他服务和我们尚未涉及的对象。这意味着,您最终将得到成千上万行的 YAML。这并不是本质上的混乱,但在这个小阶段,已经涉及了大量的 DevOps 复杂性。
然而,您也是一名开发人员,希望不一定是那位在维护这些文件的人。
只要有需要,使用你的 IDE 的 Kubernetes 支持(在我这里是IntelliJ IDEA)对 Helm charts、Kustomize 文件等进行编码支持,会极大地帮助你。哦,我们还没有谈论过它们。让我们来谈谈。这里有一段视频,会让你迅速了解IntelliJ 的 Kubernetes 插件。
Kubernetes:附加主题
什么是 Helm?Helm Chart 又是什么?
你可以把 Helm 想象成 Kubernetes 的包管理器。让我们了解一些概念:
正如我们上面提到的,仅仅在 Kubernetes 集群中安装 WordPress 就会导致成千上万行的 YAML 代码。如果你不必亲自编写这些 YAML 代码,而是可以使用预先构建的软件包,途中只需替换一些变量,那将是非常好的。
这就是Helm Chart,一堆 YAML 文件和模板,按照特定的目录结构布局。当你开始安装一个特定的 chart 时,Helm 将下载它,解析它的模板,并与你的值一起生成经典的 Kubernetes YAML 文件/清单,然后将其发送到你的 Kubernetes。
以下是一个这种模板文件的小片段(用于 Deployment 清单),包括一些占位符:
你可以将这些 chart 分享到仓库中。并没有单一的默认 chart 仓库。一个查找流行 chart 仓库的好地方是https://artifacthub.io/。
简而言之,使用 Helm 的工作流程如下:
- 安装 Helm 客户端
- 安装你喜欢的 chart - 第一部分
这条命令会从流行的 bitnami chart 仓库安装 wordpress chart 到你的集群,最终结果是一个运行中的 WordPress 安装。如果你想知道 OCI 是什么:你可以将 Helm charts 托管在支持Open Containers Initiative标准的容器 Registry 中(比如 Amazon ECR、Docker Hub、Artifactory 等)。
- 安装你喜欢的 chart - 第二部分
由于几乎总是需要覆盖一些配置值(在 WordPress 的情况下,可以在这里查看参数的巨大列表),你会想要向安装命令提供你的具体值。你可以通过一个命名为 values.yaml 的 YAML 文件传递值,或者直接使用命令行标志。因此,安装命令可能会像这样:
- 注意:你还可以使用 helm 来升级你的安装。可以升级到 chart 的新版本(考虑新的发布),或者通过helm upgrade命令升级安装的配置。
如果你想深入了解 Helm,我强烈推荐你阅读《学习 Helm》一书。
什么是 Kustomize?
在前文中,你了解到 Helm 使用模板生成 Kubernetes 清单。这意味着有人需要将 Kubernetes 清单制作成 Helm 模板,进行维护,然后作为最终用户,你可以使用 helm 命令行客户端来应用它们。
Kustomize的开发人员选择了不同的路径:它允许你通过将额外的更改层叠在原始清单之上来创建清单的自定义版本。因此,与其创建模板并在其中放置 "占位符",你最终会得到一个文件结构,例如:
然后,你可以运行kustomize build,以便 Kustomize 应用你的覆盖层,并渲染最终的 YAML 结果,你可以直接输入kubectl命令(或直接运行kubectl apply -k)。
如果你想了解 kustomization.yaml 文件需要如何结构化,可以查看这里。
哪个更好:Helm 还是 Kustomize?
我们都喜欢 Reddit 上的意见,尽管有争议:https://www.reddit.com/r/kubernetes/comments/w9xug9/helm_vs_kustomize/。
什么是 Terraform 以及与 Kubernetes 的区别是什么?
感谢上帝,我们接近本指南的结束,我不必再在 Terraform 上花费另外一千字(提示:一如既往,你会在 Terraform 上找到很多书籍和学习资源),所以我会尽量简短:
Kubernetes 是关于容器编排的。"让我告诉你我在这个 YAML 文件中想要的:为我运行我的容器!"
Terraform 是关于基础设施的创建: "让我告诉你我在这些 HashiCorp 配置语言(HCL,.tf)文件中想要的!请为我创建五个服务器,几个负载均衡器,两个数据库,几个队列,以及例如我选择的云中的监控设施。" 或者:"请为我在 AWS 上设置这些 Kubernetes 集群(EKS)"。
我如何在本地使用 Kubernetes 进行开发?
对于本地开发,你基本上有两个选择。
你可以运行一个本地的 Kubernetes 集群,并将你的应用程序部署到其中。你可能会使用Minikube来实现这一点。由于整个 "我的应用程序发生了变化 - 现在让我们构建一个容器镜像 - 然后让我们将其部署到我的集群" 这个流程手动执行起来相当繁琐,因此你可能还想使用类似Skaffold的工具来帮助你。查看这个教程以了解如何开始使用这个工作流。尽管这种设置是有效的,但它伴随着相当多的复杂性和/或资源消耗。
这就是第二种选择,解决方案的地方。对于本地开发,你基本上会忽略 Kubernetes,将你需要的任何配置克隆到你自己的 docker-compose.yml 文件中,然后简单地运行它。这是一个更简单的设置,但它的缺点是必须维护两套配置(docker-compose.yml + 你的 K8s 清单文件)。
如果您已经在使用 Kubernetes,请在下面的评论部分告诉我您是如何处理本地开发的。
我真的需要所有这些吗?
这是一个很好的问题,现在是撒些真实的 Kubernetes 轶事的绝佳时机:系统管理员限制资源以至于 Pod 的启动时间变得非常长 - 长到它们被标记为不健康并被终止,导致无休止的 Pod 创建和终止循环,但我们将长篇的解释留到另一个时候。
作为开发者,通常您无法决定,但以下是大局观:
正如本文早些时候提到的,关于仅“托管” Kubernetes 集群的学习材料是无穷无尽的,我们不仅仅是在谈论在裸金属上进行“自托管”,还有使用任何托管 Kubernetes 变体的情况。如果您有内部专业知识:
- 处理所有这些额外的复杂性
- 您可以向所有开发人员更详细地解释本文中描述的所有概念
- 而且首先而且首要的是您确实有管理数百或数千个容器的合法需求(不,不算神奇的突然扩展需求) - 那就选择 Kubernetes 吧。但我相信很多公司通过采用更简单的方法而不是幻想拥有 Google 规模的基础架构挑战,可以节省大量的时间、金钱和压力。
常见的 Kubectl 命令
如果有任何对开发人员可能需要的kubectl命令感兴趣的话,请在下面留言,我会将最常用的命令添加到这里,作为一个整齐分组/排序的列表。
为什么 Kubernetes 被缩写为 K8s
我想你可能现在已经忘记了!这里是直接摘自 Kubernetes 文档的一段引用:
“Kubernetes 的名称源自希腊语,意为舵手或领航员。K8s 作为缩写是因为在“K”和“s”之间有八个字母。Google 在2014年开源了 Kubernetes 项目。”
结束语
到目前为止,您应该对 Kubernetes 有了相当好的概述。反馈、更正和随机的意见都是受欢迎的!只需在下面留下评论。
感谢阅读。
下一个版本的计划
在评论部分投票,如果您希望以下任何一项或所有这些都发生:
- 提供复制粘贴命令 * K8s 文件,以便读者可以跟随操作
- 可能的:kubectl 命令
- 可能的:Kubernetes vs Docker Compose 并排配置的示例
- 可能的:GitOps
- 建议:使用 Kubectl/K9s/Lens IDE 或 IntelliJ Kubernetes 插件连接到 Kubernetes
- 建议:使用 Istio 的服务网格 - 在处理微服务时的常见用例。
致谢与参考
感谢 Maarten Balliauw、Andreas Eisele、Andrei Efimov、Anton Aleksandrov、Garth Gilmour、Marit van Dijk、Paul Everitt、Mukul Mantosh 的评论、更正和讨论。特别感谢《Getting Started with Kubernetes》和《Learning Helm》的作者们。