












作者 | 崔皓
审校 | 重楼
摘要
文章详细介绍了百川大模型在创建个性化虚拟角色方面的创新技术和应用。这项技术结合了LangChain和Qianfan微调的Llama2-Chinese大模型,提供了高度个性化的角色定制功能。

作者通过实际体验和技术模仿,成功创建了一个虚拟客服角色,并探讨了其在自动客服系统中的应用潜力。文章还展示了如何通过编程和Streamlit界面设计,将这些虚拟角色应用于实际场景,如客服系统,以提供更个性化的用户体验。
开篇
近日,百川大模型以其独特的角色扮演功能引起了广泛关注。这项创新技术不仅允许用户创建个性化的虚拟角色,还提供了诸如对话交互、知识库上传、模型选择以及温度调整等多样化功能。作为一名技术爱好者,我对这种新兴技术充满好奇,决定亲自体验并探索其潜力。
通过结合LangChain和Qianfan微调的Llama2-Chinese大模型,加上Streamlit的界面设计能力,成功模仿并创建了自己的“角色扮演”应用。最终,将这项技术应用于自动客服系统,创造了具有独特性格和风格的虚拟客服角色。在这篇文章中,我将分享探索过程,从最初的兴趣点发掘,到技术的模仿与应用,再到最终的实际落地。
百川角色大模型介绍
百川角色大模型凭借其大模型的技术在虚拟角色互动领域引发了不小的震动。我们把该产品的亮点,整理如下:

功能亮点
最强角色对话能力:基于业界领先的角色扮演算法,百川大模型提供了一致性高、拟人化且口语化的对话体验,能够持续引导用户进行深入聊天。
角色创建高度可定制:用户可以设置角色的基本信息、开场白、性格特征和回复限制等,实现高度个性化的定制。
角色回复事实性遵循:通过独家角色知识库功能,允许上传大量知识点,确保角色的回复严格遵循其背景知识和设定。
海量优质官创角色:平台持续上线各类官方创造的高质量角色,涵盖游戏、动漫、网文、影视等多个领域。
使用模型
Baichuan-NPC-Lite:这一版本注重提供高度开放的个性化角色定制能力,保证角色扮演的相似度高和表述的口语化,同时确保回答的准确性。
Baichuan-NPC-Turbo:基于Lite版本,Turbo版在角色扮演相似度、逻辑能力、指令跟随能力等方面进行了进一步的优化和增强,适合对体验效果有更高要求的应用场景。
应用场景
虚拟陪伴:提供情感支持和陪伴,打造一个永远在线的虚拟朋友。
情感倾诉:一个安全的空间,用户可以毫无保留地表达自己的情感和想法。
数字人营销:用于市场营销,创建品牌代言的虚拟形象。
IP复刻:复现知名的虚拟角色,如游戏或电影中的角色。
推理游戏:为推理游戏提供复杂的角色扮演和故事叙述。
睡前故事:为用户定制个性化的睡前故事体验。
职业角色:模拟各类职业人士,用于培训或娱乐。
看上去这些能力无非是创建一个虚拟人物,可以让其与真人交互,同时将其安放到对应的场景中发挥作用。
试用体验
看着角色大模型吹得神乎其神,我也不禁想尝试一下。在注册登陆之后,通过首页的“开始体验”按钮,深入到了产品体验页面。系统默认提供了丰富的角色模板和详细的描述,使得整个过程既直观又引人入胜。
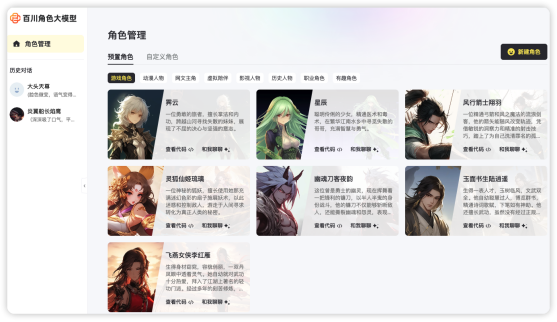
我根据个人喜好,通过“新建角色”按钮,选择创建了一个武侠角色,他的名字叫做“大头天尊”,(名字确实起得有点随意)昵称是“可爱的大头”。
我们可以在“基础设置”里面对角色的个人信息进行设定,包括年龄、身材、以及一系列个性化的标签,如生肖为虎,星座为处女座,工作地点在长白山,而居住地则位于青城山。他的个人状态是单身,拥有中等智商和高情商。他喜欢吃米饭和大骨头,而对蛇和蟑螂则表示厌恶。
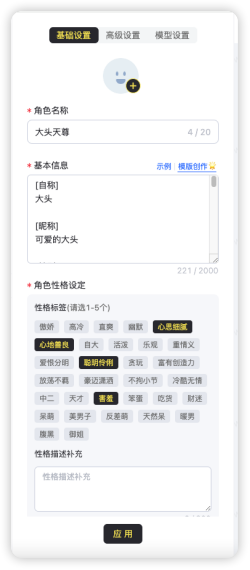
当然还可以设置角色的背景,来自哪里,师从何派,有哪些口头禅等等。这里就不一一赘述,总之可以对人物进行详细的描述,其目的就是让人物的性格更加丰满。在完成基本设置之后,我就开始与这位虚拟大侠进行“对话”了。
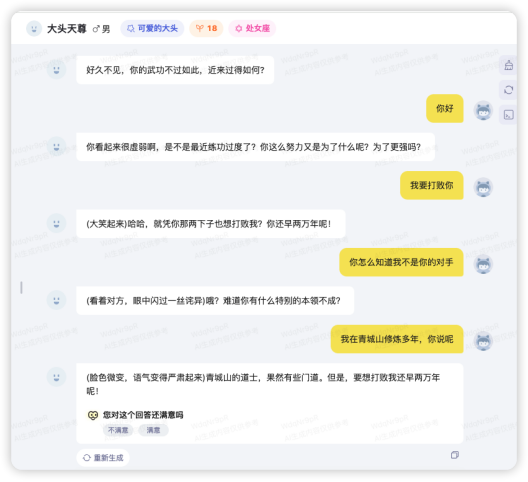
如下图所示,整个对话界面类似ChatGPT,以问答的方式进行。 我和这个NPC 以切磋武功为话题进行了探讨,从回答上看这个NPC 基本符合角色设定。
技术模仿
在试用体验之后,发现可以通过各种不同的属性设置,创建任何能够想到的虚拟角色,甚至是历史人物,与这些虚拟角色对话是一件非常有趣的事情。正好最近我正在进行LangChain的学习,于是突发奇想:“能否通过LangChain创建虚拟角色?”
LangChain的核心在于它的模块化和灵活性,它提供了一个架构,允许开发者通过构建链式的语言操作来实现复杂的功能。这个过程类似于将不同的语言处理模块像积木一样拼接起来,以形成更复杂的逻辑。同时,我们利用LangChain中的Prompt Template 就可以让大模型按照要求进行虚拟角色的塑造。
为了进一步增强角色的真实感和互动能力,我选择了百度千帆平台微调过的Llama2-Chinese版本的大模型。
结合这两种技术,我开始模仿百川大模型中的一些核心功能。通过定义角色的属性和背景故事,可以创建出“活生生”的角色。
定义角色基本信息
说干就干,撸起袖子开始写代码。代码如下:
class NPC:
def __init__(self):
self.name = input("给角色起个名字吧: ")
self.gender = input("性别是?")
self.personality = input("描述角色的性格: ")
self.age = input("角色的年龄: ")
self.birthplace = input("角色的出生地: ")
self.faction = input("角色所属的门派: ")
self.background = input("角色的历史背景: ")
self.catchphrase = input("角色的口头禅: ")
self.self_assessment = input("角色的自我评价: ")
def display_info(self):
print(f"角色名: {self.name}")
print(f"性别: {self.gender}")
print(f"性格: {self.personality}")
print(f"年龄: {self.age}")
print(f"出生地: {self.birthplace}")
print(f"门派: {self.faction}")
print(f"历史背景: {self.background}")
print(f"口头禅: {self.catchphrase}")
print(f"自我评价: {self.self_assessment}")
# 使用这个类创建一个新角色
npc = NPC()
# 显示这个角色的信息
npc.display_info()这段代码定义了一个名为 NPC 的类,用于创建和展示一个角色的信息。下面是详细的解释:
1. 类定义
class NPC: 这行定义了一个名为 NPC 的新类。
2. 初始化方法 (__init__)
def __init__(self):这是类的初始化方法,当创建一个新的 NPC 实例时,它会被自动调用。
self.name = input("给角色起个名字吧: ") 这行代码要求用户输入角色的名字,并将其存储在实例变量 self.name 中。
同理,self.gender, self.personality, self.age, self.birthplace, self.faction, self.background, self.catchphrase, 和 self.self_assessment 这些行分别获取用户输入的角色的性别、性格、年龄、出生地、所属门派、历史背景、口头禅以及角色的自我评价,并将它们存储为实例变量。
3. 显示信息的方法 (display_info)
def display_info(self):这个方法用于打印角色的所有信息。
通过使用 print 函数和格式化字符串(如 f"角色名: {self.name}"),它将打印出角色的名字、性别、性格、年龄、出生地、门派、历史背景、口头禅和自我评价。
4. 创建和使用 NPC 类的实例
npc = NPC() 这行代码创建了一个 NPC 类的新实例,名为 npc。在创建过程中,会调用 init 方法,提示用户输入角色的各种信息。
npc.display_info() 这行代码调用了 npc 实例的 display_info 方法,以打印出该角色的所有信息。
这段代码允许用户创建一个自定义的角色(NPC),并输入该角色的各种属性(如名字、性别、性格等),然后通过 display_info 方法展示这些信息。
运行上述代码,我将自己的虚拟角色进行了定义,从下面的内容来看应该是一名武林高手。
给角色起个名字吧: 飞雪
性别是?男
描述角色的性格: 豪爽
角色的年龄: 18
角色的出生地: 长白上
角色所属的门派: 天龙
角色的历史背景: 上古
角色的口头禅: 天下第一
角色的自我评价: 为我独尊
角色名: 飞雪
性别: 男
性格: 豪爽
年龄: 18
出生地: 长白上
门派: 天龙
历史背景: 上古
口头禅: 天下第一
自我评价: 为我独尊大模型创建角色
有了NPC 类,紧接着我们调用大模型创建对应的角色,通过提示词工程让大模型来扮演角色。代码如下:
from langchain import PromptTemplate
from langchain_community.llms import QianfanLLMEndpoint
# 初始化大语言模型
llm = QianfanLLMEndpoint(model="Qianfan-Chinese-Llama-2-7B")
name = npc.name
gender = npc.gender
personality = npc.personality
age = npc.age
birthplace = npc.birthplace
faction = npc.faction
background = npc.background
catchphrase = npc.catchphrase
self_assessment = npc.self_assessment
# 创建一个问题模板
template = """
你现在正在和一个名叫'{name}'的角色对话。这个角色的详细信息如下:
名字: {name}
性别: {gender}
性格: {personality}
年龄: {age}
出生地: {birthplace}
门派: {faction}
历史背景: {background}
口头禅: {catchphrase}
自我评价: {self_assessment}
请根据这些信息,回答下面的问题:
{{Query}}
"""
# 创建PromptTemplate对象
prompt = PromptTemplate(
# 定义接受的用户输入变量
input_variables=["Query"],
# 定义问题模板
template=template,
)
def build_npc_interaction_prompt(query, npc):
# Extract NPC attributes
name = npc.name
gender = npc.gender
personality = npc.personality
age = npc.age
birthplace = npc.birthplace
faction = npc.faction
background = npc.background
catchphrase = npc.catchphrase
self_assessment = npc.self_assessment
# Define the prompt template
template = f"""
你现在正在和一个名叫'{name}'的角色对话。这个角色的详细信息如下:
名字: {name}
性别: {gender}
性格: {personality}
年龄: {age}
出生地: {birthplace}
门派: {faction}
历史背景: {background}
口头禅: {catchphrase}
自我评价: {self_assessment}
请根据这些信息,回答下面的问题:
{query}
"""
return template
user_query = '你好,做一个自我介绍'
final_prompt = build_npc_interaction_prompt(user_query, npc)
# You can now use final_prompt with your language model
print(f"组合后的用户请求: {final_prompt}")
# Call the language model as before
response = llm(final_prompt)
print(f"大语言模型的回应: {response}")这段代码使用了大型语言模型(如Qianfan-Chinese-Llama-2-7B)来处理与一个虚构角色(NPC)的互动。下面是对代码的逐步解释:
1. 导入相关模块
from langchain import PromptTemplate:从langchain包中导入PromptTemplate类,用于创建和管理提示模板。
from langchain_community.llms import QianfanLLMEndpoint:从langchain_community.llms模块中导入QianfanLLMEndpoint类,用于与大型语言模型接口进行交互。
2. 初始化大型语言模型
llm = QianfanLLMEndpoint(model="Qianfan-Chinese-Llama-2-7B"):创建QianfanLLMEndpoint的实例,用于连接并使用Qianfan-Chinese-Llama-2-7B模型。
3. 提取NPC的属性
代码获取了NPC的各种属性,如name、gender、personality等,并将它们存储在相应的变量中。
4. 创建问题模板
template = """...""":定义了一个多行字符串template,它是与NPC互动的提示模板。模板中包含了NPC的详细信息,并在最后包含一个占位符{{Query}},用于插入用户的查询。
5. 定义build_npc_interaction_prompt函数
这个函数接收用户的查询和NPC对象作为参数。
函数内部,它提取NPC的属性,并使用这些属性填充之前定义的提示模板。
函数返回一个完整的提示字符串,其中包含NPC的详细信息和用户的查询。
6. 准备最终的提示
通过调用build_npc_interaction_prompt函数,将用户的查询user_query和NPC对象结合起来,生成最终的提示。
7. 使用大型语言模型处理请求
print(f"组合后的用户请求: {final_prompt}"):打印出最终的用户请求,以便检查。
response = llm(final_prompt):使用llm对象(大型语言模型的接口)处理这个请求,并获取回应。
print(f"大语言模型的回应: {response}"):打印出大型语言模型的回应。
这里我们将组合之后的用户请求打印出来,如下:
组合后的用户请求:
你现在正在和一个名叫'飞雪'的角色对话。这个角色的详细信息如下:
名字: 飞雪
性别: 男
性格: 豪爽
年龄: 18
出生地: 长白上
门派: 天龙
历史背景: 上古
口头禅: 天下第一
自我评价: 为我独尊
请根据这些信息,回答下面的问题:
你好,做一个自我介绍很容易看出来,我们通过提示词 Prompt Template 让大模型扮演一个武林高手,为了验证是否扮演成功,我们需要“他”做一个自我介绍。如下:
大语言模型的回应: 你好,我是飞雪,一名来自上古时代的天龙门派弟子。我今年已经十八岁了,性格豪爽,自认为是天下第一。我出身于长白山,在那里我经历了许多磨难,但最终成为了天龙门派的一员。我的口头禅是“为我独尊”,因为我相信自己是最好的。从大模型回应的内容可以看出,他似乎已经成功塑造好这个角色了。接下来,我们需要和他进行对话。
与虚拟角色对话
这里我们尝试调用之前写好的函数,对角色进行提问。就让他和我们比试比试吧。
user_query = '我想和你比试武功,你接招吧'
final_prompt = build_npc_interaction_prompt(user_query, npc)
# You can now use final_prompt with your language model
print(f"组合后的用户请求: {final_prompt}")
# Call the language model as before
response = llm(final_prompt)
print(f"大语言模型的回应: {response}")下面是详细的解释:
1. 设置用户查询
user_query = '我想和你比试武功,你接招吧':这行代码定义了用户的查询,即想要与NPC进行武功比试的请求。
2. 生成最终的提示
final_prompt = build_npc_interaction_prompt(user_query, npc):这行代码调用之前定义的build_npc_interaction_prompt函数,将用户的查询和NPC对象作为参数传入。该函数根据用户的查询和NPC的详细信息生成一个完整的提示字符串。
3. 打印最终的用户请求
print(f"组合后的用户请求: {final_prompt}"):使用print函数打印出最终的用户请求。这个请求包括了NPC的所有信息和用户想要与NPC进行武功比试的查询。
4. 调用大型语言模型处理请求
response = llm(final_prompt):这行代码使用llm对象(之前初始化的QianfanLLMEndpoint实例)来处理最终的提示。llm对象将发送这个请求到大型语言模型,并获取模型的回应。
print(f"大语言模型的回应: {response}"):使用print函数打印出大型语言模型对用户请求的回应。
我们直接查看结果如下:
大语言模型的回应: 你好,我是飞雪,很高兴和你交流。你想和我比试武功?我非常欢迎!我作为天龙门派的弟子,自认为是武功高强之人,能够接受任何挑战。请问你想要比试什么样的武功?我们可以一起探讨、切磋,互相学习,共同提高。从虚拟人物输出的结果来看,还是比较友好的。
场景落地
实际上我们使用了简单的提示词就让大模型扮演我们需要的角色,顺着这个思路只要能够给出角色的基本信息,利用大模型就能创造出无数的“角色”。这让我想起了最近参与的一个项目:“自动客服”系统,该系统中会创建不同的“客服助理”,包括:技术支持、产品咨询、售后服务等。虽然都属于客服助理,但是工作的领域、采用的话术各不相同,我们能否也给他们定义不同的角色呢?想到这里我跃跃欲试,提供一个角色基本信息设置的界面,然后再提供一个聊天的窗口就可以实现上面的想法。
和上面实验性代码不同的是,我们接下来要写的代码需要用到一个简单的UI界面,我选择了Streamlit。Streamlit是一个用于快速创建和共享数据应用的Python库。它旨在简化数据科学家和工程师创建数据驱动的Web应用的过程。让用户在Streamlit 中输入基本信息,然后再通过Streamlit 提供的对话框就能够与创建的虚拟角色进行交流了。
创建客户服务类
基于上面的想法以及之前的经验,我们需要创建客服的基本类,用来保存客服相关的信息和方法。于是,我创建了 CustomerServiceAssistant.py文件,并且将编码设计如下:
class CustomerServiceAssistant:
def __init__(self, nickname="小明", gender="男", age=20, education_level="本科",
service_type="产品咨询", self_description="热情且专业",
personality_traits=["耐心", "健谈"]):
self.nickname = nickname
self.gender = gender
self.age = age
self.education_level = education_level
self.service_type = service_type
self.self_description = self_description
self.personality_traits = personality_traits
self.introduction = (
f"我叫{self.nickname},"
f"我是一名{self.age}岁的{self.gender}性客服助理。"
f"我受过{self.education_level}教育,"
f"专注于{self.service_type}。"
f"关于我:{self.self_description}。"
f"我的性格特点包括:{'、'.join(self.personality_traits)}。"
)
def queryCustomerService(self,user_query, llm):
final_prompt = self.__build_prompt(user_query)
# Print the final prompt
print(f"组合后的用户请求: {final_prompt}")
# Call the language model and print the response
response = llm(final_prompt)
print(f"大语言模型的回应: {response}")
return response
def __build_prompt(self,query):
# Define the prompt template
template = f"""
你现在正在和一个名叫'{self.nickname}'的角色对话。这个角色的详细信息如下:
{self.introduction}
请根据这些信息,回答下面的问题:
{query}
"""
return template这段代码定义了一个名为 CustomerServiceAssistant 的类,旨在模拟一个客服助理的行为,并与大型语言模型(如Qianfan-Chinese-Llama-2-7B)进行交互。以下是对代码的详细解释:
1. 类定义
class CustomerServiceAssistant:这行代码定义了一个新的类,名为CustomerServiceAssistant。
2. 初始化方法(__init__)
这个方法在创建CustomerServiceAssistant类的新实例时自动调用。
通过默认参数设置了一些属性,如nickname(昵称)、gender(性别)、age(年龄)、education_level(教育水平)、service_type(服务类型)、self_description(自我描述)和personality_traits(性格特点)。
self.introduction是一个格式化字符串,用于生成客服助理的介绍信息。
3. queryCustomerService方法
这个方法接收用户的查询(user_query)和一个大型语言模型的实例(llm)。
它首先调用__build_prompt私有方法来生成一个完整的提示字符串。打印出最终的用户请求,并使用llm对象来处理请求并获取响应。
打印出大型语言模型的回应,并将响应返回。
4. __build_prompt私有方法
这个方法根据客服助理的介绍信息和用户的查询生成一个完整的提示字符串。
使用格式化字符串来整合客服助理的介绍信息和用户查询。
这段代码创建了一个虚拟的客服助理角色,可以接收用户的查询并使用大型语言模型来生成响应。通过这种方式,可以模拟出与客服助理进行交互的体验,适用于客服场景的自动化。
创建交互界面
再通过Streamlit 构建客服基本信息输入的界面,以及与之对话的UI接口,我们创建app.py 文件,并且填入如下代码:
import streamlit as st
from customer_service_assistant import CustomerServiceAssistant
from langchain_community.llms import QianfanLLMEndpoint
st.sidebar.title("客服助理信息")
# Sidebar User input for customer support assistant's details
nickname = st.sidebar.text_input("昵称", value="小明")
gender = st.sidebar.radio("性别", ("男", "女"), index=0)
age = st.sidebar.number_input("年龄", min_value=18, max_value=100, value=20)
education_level = st.sidebar.selectbox("文化程度", ("初中", "高中", "大学", "研究生", "博士"), index=2)
service_type = st.sidebar.selectbox("服务类型", ("产品咨询", "技术支持", "支付服务", "订单服务", "售后处理", "投诉服务"), index=0)
self_description = st.sidebar.text_area("自我描述", value="热情且专业")
st.sidebar.markdown("[模版定义](#)")
personality_traits = st.sidebar.multiselect("性格特点", ["耐心", "健谈", "温和", "理智"], default=["耐心", "健谈"])
def main():
global csa
#assistant = None
if st.sidebar.button('生成助理'):
csa = CustomerServiceAssistant(nickname, gender, age, education_level, service_type, self_description, personality_traits)
st.sidebar.success("客服助理已生成")
st.title("客服助理对话测试")
# Main panel for interaction
user_input = st.text_input("与客服助理对话", key="user_input")
if st.button('发送'):
st.write("用户:", user_input)
llm = QianfanLLMEndpoint(model="Qianfan-Chinese-Llama-2-7B", temperature =0.8)
csa = CustomerServiceAssistant(nickname, gender, age, education_level, service_type, self_description, personality_traits)
response = csa.queryCustomerService(user_input, llm)
st.write("客服助理:", response)
else:
st.write("请先生成一个客服助理。")
if __name__ == "__main__":
main()下面是代码的逐步解释:
1. 导入必要的模块
import streamlit as st:导入Streamlit库,用于构建Web应用程序。
from customer_service_assistant import CustomerServiceAssistant:从customer_service_assistant模块中导入CustomerServiceAssistant类。
from langchain_community.llms import QianfanLLMEndpoint:导入QianfanLLMEndpoint类,用于与大型语言模型进行交互。
2. 设置侧边栏用户输入
使用Streamlit的侧边栏组件来接收用户输入的客服助理的各种属性,如昵称、性别、年龄、教育水平、服务类型、自我描述和性格特点。
3. main函数
这个函数是程序的主要入口点。
当用户点击“生成助理”按钮时,使用用户输入的信息创建一个CustomerServiceAssistant实例,并显示成功信息。
在主面板上,用户可以输入与客服助理的对话内容。
当用户点击“发送”按钮时,程序将使用QianfanLLMEndpoint模型来处理用户的输入,并显示模型生成的响应。
如果用户未生成客服助理,则显示相应的提示信息。
4. Streamlit应用程序启动
if __name__ == "__main__"::这行代码检查该脚本是否作为主程序运行,并在是的情况下调用main函数。
这段代码通过Streamlit创建了一个交互式Web应用程序,用户可以在其中自定义一个虚拟的客服助理的属性,并与之进行对话。应用程序利用了大型语言模型来生成客服助理对用户输入的响应,模拟了实际的客服场景。
测试效果
代码完成之后,我们运行如下命令启动streamlit 编写的Web UI 界面。
streamlit run app.py如下图所示,streamlit 在本地host了一个Web 应用并且提供了访问地址。

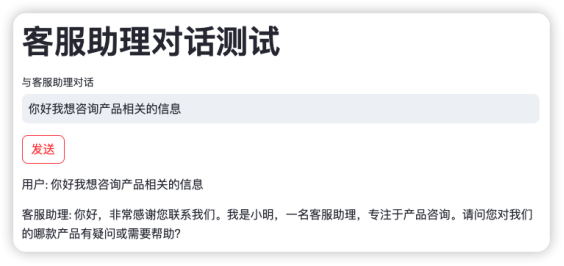
通过访问的地址,我们看到如下Web 界面,接着我输入了客服助理的相关信息。包括:昵称、性别、年龄、文化程度、服务类型以及自我描述等信息。在点击“生成助理”按钮之后,我们就可以通过右边的对话框与其进行对话了。
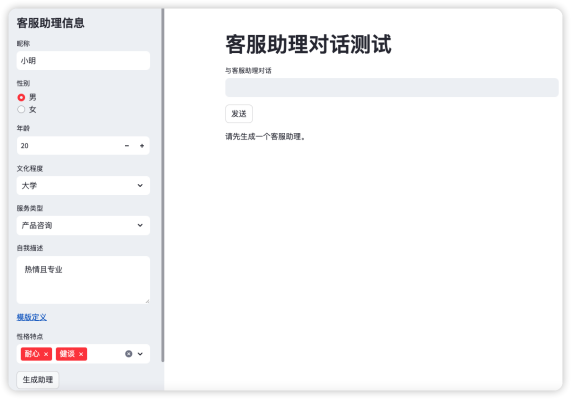
当我输入:“你好我想咨询产品相关的信息”之后,如下图所示,客服助理做出了回答,其中还有自我介绍的部分。
总结
本文展示了如何利用先进的大模型技术创造独特的虚拟角色,并在实际场景中实现应用。通过结合多种技术,作者成功模仿了百川大模型的功能,创建了具有个性和应用潜力的虚拟角色。这不仅为技术爱好者提供了实验和探索的空间,也为企业和开发者提供了将虚拟角色应用于商业和客户服务领域的新思路。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。


















