













当前 AI 领域的关注重心正从大型语言模型(LLM)向多模态转移,于是乎,让 LLM 具备多模态能力的多模态大型语言模型(MM-LLM)就成了一个备受关注的研究主题。
近日,腾讯 AI Lab、京都大学和穆罕默德・本・扎耶德人工智能大学的一个研究团队发布了一份综述报告,全面梳理了 MM-LLM 的近期进展。文中不仅总结了 MM-LLM 的模型架构和训练流程,而且还梳理了 26 个当前最佳的 MM-LLM。如果你正考虑研究或使用 MM-LLM,不妨考虑从这份报告开始研究,找到最符合你需求的模型。

- 论文标题:MM-LLMs: Recent Advances in MultiModal Large Language Models
- 论文地址:https://arxiv.org/abs/2401.13601
报告概览
近些年来,多模态(MM)预训练研究进展迅速,让许多下游任务的性能不断突破到新的边界。但是,随着模型和数据集规模不断扩大,传统多模态模型也遭遇了计算成本过高的问题,尤其是当从头开始训练时。考虑到多模态研究位于多种模态的交叉领域,一种合乎逻辑的方法是充分利用现成的预训练单模态基础模型,尤其是强大的大型语言模型(LLM)。
这一策略的目标是降低多模态预训练的计算成本并提升其效率,这样一来就催生出了一个全新领域:MM-LLM,即多模态大型语言模型。
MM-LLM 使用 LLM 提供认知功能,让其处理各种多模态任务。LLM 能提供多种所需能力,比如稳健的语言泛化能力、零样本迁移能力和上下文学习(ICL)。与此同时,其它模态的基础模型却能提供高质量的表征。考虑到不同模态的基础模型都是分开预训练的,因此 MM-LLM 面临的核心挑战是如何有效地将 LLM 与其它模态的模型连接起来以实现协作推理。
在这个领域内,人们关注的主要焦点是优化提升模态之间的对齐(alignment)以及让模型与人类意图对齐。这方面使用的主要工作流程是多模态预训练(MM PT)+ 多模态指令微调(MM IT)。
2023 年发布的 GPT-4 (Vision) 和 Gemini 展现出了出色的多模态理解和生成能力;由此激发了人们对 MM-LLM 的研究热情。
一开始,研究社区主要关注的是多模态内容理解和文本生成,此类模型包括 (Open) Flamingo、BLIP-2、Kosmos-1、LLaVA/LLaVA-1.5、MiniGPT-4、MultiModal-GPT、VideoChat、Video-LLaMA、IDEFICS、Fuyu-8B、Qwen-Audio。
为了创造出能同时支持多模态输入和输出的 MM-LLM,还有一些研究工作探索了特定模态的生成,比如 Kosmos-2 和 MiniGPT-5 研究的是图像生成,SpeechGPT 则聚焦于语音生成。
近期人们关注的重点是模仿类似人类的任意模态到任意模态的转换,而这或许是一条通往通用人工智能(AGI)之路。
一些研究的目标是将 LLM 与外部工具合并,以达到近似的任意到任意的多模态理解和生成;这类研究包括 Visual-ChatGPT、ViperGPT、MM-REACT、HuggingGPT、AudioGPT。
反过来,为了减少级联系统中传播的错误,也有一些研究团队想要打造出端到端式的任意模态 MM-LLM;这类研究包括 NExT-GPT 和 CoDi-2。
图 1 给出了 MM-LLM 的时间线。

为了促进 MM-LLM 的研究发展,腾讯 AI Lab、京都大学和穆罕默德・本・扎耶德人工智能大学的这个团队整理出了这份综述报告。机器之心整理了该报告的主干部分,尤其是其中对 26 个当前最佳(SOTA)MM-LLM 的介绍。
模型架构
这一节,该团队详细梳理了一般模型架构的五大组件,另外还会介绍每个组件的实现选择,如图 2 所示。
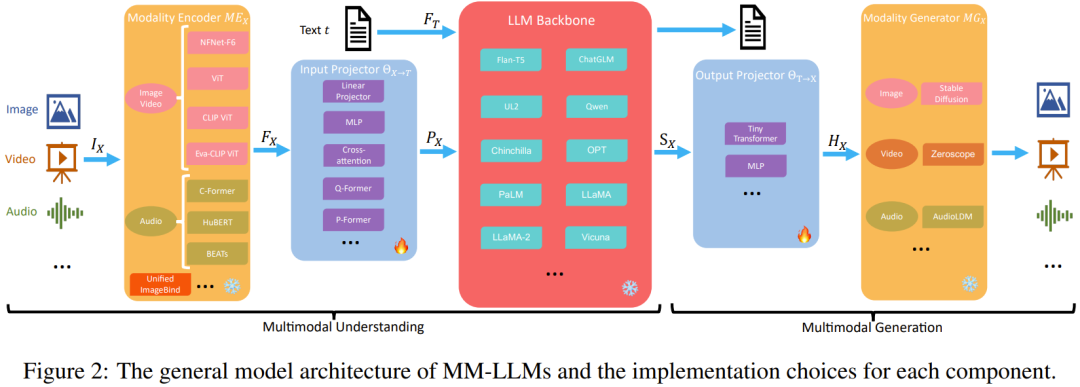
专注于多模态理解的 MM-LLM 仅包含前三个组件。
在训练阶段,模态编码器、LLM 骨干和模态生成器通常保持在冻结状态。其优化的要点是输入和输出投影器。由于投影器是轻量级的组件,因此相比于总参数量,MM-LLM 中可训练参数的占比非常小(通常约为 2%)。总参数量取决于 MM-LLM 中使用的核心 LLM 的规模。因此,在针对各种多模态任务训练 MM-LLM 时,可以取得很高的训练效率。
模态编码器(Modality Encoder/ME):编码不同模态的输入,以得到相应的特征。
输入投影器(Input Projector):将已编码的其它模态的特征与文本特征空间对齐。
LLM 骨干:MM-LLM 使用 LLM 作为核心智能体,因此也继承了 LLM 的一些重要特性,比如零样本泛化、少样本上下文学习、思维链(CoT)和指令遵从。LLM 骨干的任务是处理各种模态的表征,其中涉及到与输入相关的语义理解、推理和决策。它的输出包括 (1) 直接的文本输出,(2) 其它模态的信号 token(如果有的话)。这些信号 token 可用作引导生成器的指令 —— 是否生成多模态内容,如果是,则指定所要生成的内容。
MM-LLM 中常用的 LLM 包括 Flan-T5、ChatGLM、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2、Vicuna。
输出投影器:将来自 LLM 骨干的信号 token 表征映射成可被后续模态生成器理解的特征。
模态生成器:生成不同对应模态的输出。目前的研究工作通常是使用现有的隐扩散模型(LDM),即使用 Stable Diffusion 来合成图像、使用 Zeroscope 来合成视频、使用 AudioLDM-2 来合成音频。
训练流程
MM-LLM 的训练流程可以分为两个主要阶段:MM PT(多模态预训练)和 MM IT(多模态指令微调)。
MM PT
在预训练阶段(通常是利用 XText 数据集),通过优化预定义的目标来训练输入和输出投影器,使其对齐不同的模态。(有时候也会将参数高效型微调(PEFT)技术用于 LLM 骨干。)
MM IT
MM IT 这种方法需要使用一组指令格式的数据集对预训练的 MM-LLM 进行微调。通过这个微调过程,MM-LLM 可以泛化到未曾见过的任务,执行新指令,从而增强零样本性能。
MM IT 包含监督式微调(SFT)和根据人类反馈的强化学习(RLHF),目标是与人类意图或偏好对齐并提升 MM-LLM 的交互能力。
SFT 可将预训练阶段的部分数据转换成指令感知型的格式。
SFT 之后,RLHF 会对模型进行进一步的微调,这需要有关 MM-LLM 所给响应的反馈信息(比如由人类或 AI 标注的自然语言反馈(NLF))。这个过程采用了一种强化学习算法来有效整合不可微分的 NLF。模型的训练目标是根据 NLF 生成对应的响应。
现有的 MM-LLM 在 MM PT 和 MM IT 阶段使用的数据集有很多,但它们都是表 3 和表 4 中数据集的子集。
当前最佳的 MM-LLM
该团队比较了 26 个当前最佳(SOTA)MM-LLM 的架构和训练数据集规模,如表 1 所示。另外他们还简单总结了每种模型的核心贡献和发展趋势。

(1) Flamingo:一系列设计用于处理交织融合的视觉数据和文本的视觉语言(VL)模型,可输出自由形式的文本。
(2) BLIP-2:提出了一种能更高效利用资源的框架,其中使用了轻量级的 Q-Former 来连接不同模态,还使用了冻结的 LLM。使用 LLM,可通过自然语言 prompt 引导 BLIP-2 执行零样本图像到文本生成。
(3) LLaVA:率先将指令微调技术迁移到多模态领域。为了解决数据稀疏性问题,LLaVA 使用 ChatGPT/GPT-4 创建了一个全新的开源多模态指令遵从数据集和一个多模态指令遵从基准 LLaVA-Bench。
(4) MiniGPT-4:提出了一种经过精简的方法,其中仅训练一个线性层来对齐预训练视觉编码器与 LLM。这种高效方法展现出的能力能媲美 GPT-4。
(5) mPLUG-Owl:提出了一种全新的用于 MM-LLM 的模块化训练框架,并整合了视觉上下文。为了评估不同模型在多模态任务上的性能,该框架还包含一个指示性的评估数据集 OwlEval。
(6) X-LLM:扩展到了包括音频在内的多个模态,展现出了强大的可扩展性。利用了 QFormer 的语言可迁移能力,X-LLM 成功在汉藏语系汉语语境中得到了应用。
(7) VideoChat:开创了一种高效的以聊天为中心的 MM-LLM 可用于进行视频理解对话。这项研究为该领域的未来研究设定了标准,并为学术界和产业界提供了协议。
(8) InstructBLIP:该模型是基于 BLIP-2 模型训练得到的,在 MM IT 阶段仅更新了 Q-Former。通过引入指令感知型的视觉特征提取和对应的指令,该模型可以提取灵活且多样化的特征。
(9) PandaGPT 是一种开创性的通用模型,有能力理解 6 种不同模态的指令并遵照行事:文本、图像 / 视频、音频、热量、深度和惯性测量单位。
(10) PaLIX:其训练过程使用了混合的视觉语言目标和单模态目标,包括前缀补全和掩码 token 补全。研究表明,这种方法可以有效用于下游任务,并在微调设置中到达了帕累托边界。
(11) Video-LLaMA:提出了一种多分支跨模态预训练框架,让 LLM 可以在与人类对话的同时处理给定视频的视觉和音频内容。该框架对齐了视觉与语言以及音频与语言。
(12) Video-ChatGPT:该模型是专门针对视频对话任务设计的,可以通过整合时空视觉表征来生成有关视频的讨论。
(13) Shikra:提出了一种简单但统一的预训练 MM-LLM,并且专门针对参考对话(Referential Dialogue)任务进行了调整。参考对话任务涉及到讨论图像中的区域和目标。该模型表现出了值得称道的泛化能力,可有效处理未曾见过的情况。
(14) DLP:提出了用于预测理想 prompt 的 P-Former,并在一个单模态语句的数据集上完成了训练。这表明单模态训练可以用于增强多模态学习。
(15) BuboGPT:为了全面理解多模态内容,该模型在构建时学习了一个共享式语义空间。其探索了图像、文本和音频等不同模态之间的细粒度关系。
(16) ChatSpot:提出了一种简单却有效的方法,可为 MM-LLM 精细化调整精确引用指令,从而促进细粒度的交互。通过集成精确引用指令(由图像级和区域级指令构成),多粒度视觉语言任务描述得以增强。
(17) Qwen-VL:一种支持英语和汉语的多语言 MM-LLM。Qwen-VL 还允许在训练阶段输入多张图像,这能提高其理解视觉上下文的能力。
(18) NExT-GPT:这是一种端到端、通用且支持任意模态到任意模态的 MM-LLM,支持自由输入和输出图像、视频、音频和文本。其采用了一种轻量的对齐策略 —— 在编码阶段使用以 LLM 为中心的对齐,在解码阶段使用指令遵从对齐。
(19) MiniGPT-5:这种 MM-LLM 整合了转化成生成式 voken 的技术,并集成了 Stable Diffusion。它擅长执行交织融合了视觉语言输出的多模态生成任务。其在训练阶段加入了无分类器指导,以提升生成质量。
(20) LLaVA-1.5:该模型基于 LLaVA 框架并进行了简单的修改,包括使用一种 MLP 投影,引入针对学术任务调整过的 VQA 数据,以及使用响应格式简单的 prompt。这些调整让模型的多模态理解能力得到了提升。
(21) MiniGPT-v2:这种 MM-LLM 的设计目标是作为多样化视觉语言多任务学习的一个统一接口。为了打造出能熟练处理多种视觉语言任务的单一模型,每个任务的训练和推理阶段都整合了标识符(identifier)。这有助于明确的任务区分,并最终提升学习效率。
(22) CogVLM:一种开源 MM-LLM,其通过一种用在注意力和前馈层中的可训练视觉专家模块搭建了不同模态之间的桥梁。这能让多模态特征深度融合,同时不会损害在下游 NLP 任务上的性能。
(23) DRESS:提出了一种使用自然语言反馈提升与人类偏好的对齐效果的方法。DRESS 扩展了条件式强化学习算法以整合不可微分的自然语言反馈,并以此训练模型根据反馈生成适当的响应。
(24) X-InstructBLIP:提出了一种使用指令感知型表征的跨模态框架,足以扩展用于助力 LLM 处理跨多模态(包括图像 / 视频、音频和 3D)的多样化任务。值得注意的是,它不需要特定模态的预训练就能做到这一点。
(25) CoDi-2:这是一种多模态生成模型,可以出色地执行多模态融合的指令遵从、上下文生成以及多轮对话形式的用户 - 模型交互。它是对 CoDi 的增强,使其可以处理复杂的模态交织的输入和指令,以自回归的方式生成隐含特征。
(26) VILA:该模型在视觉任务上的性能出色,并能在保持纯文本能力的同时表现出卓越的推理能力。VILA 之所以性能优异,是因为其充分利用了 LLM 的学习能力,使用了图像 - 文本对的融合属性并实现了精细的文本数据重新混合。
当前 MM-LLM 的发展趋势:
(1) 从专注于多模态理解向特定模态生成发展,并进一步向任意模态到任意模态转换发展(比如 MiniGPT-4 → MiniGPT-5 → NExT-GPT)。
(2) 从 MM PT 到 SFT 再到 RLHF,训练流程持续不断优化,力求更好地与人类意图对齐并增强模型的对话互动能力(比如 BLIP-2 → InstructBLIP → DRESS)。
(3) 拥抱多样化的模态扩展(比如 BLIP-2 → X-LLM 和 InstructBLIP → X-InstructBLIP)。
(4) 整合质量更高的训练数据集(比如 LLaVA → LLaVA-1.5)。
(5) 采用更高效的模型架构,从 BLIP-2 和 DLP 中复杂的 Q-Former 和 P-Former 输入投射器模块到 VILA 中更简单却有效的线性投影器。
基准和性能
为了全面比较各模型的性能,该团队编制了一个表格,其中包含从多篇论文中收集的主要 MM-LLM 的数据,涉及 18 个视觉语言基准,见表 2。

未来方向
该团队最后讨论了 MM-LLM 领域比较有前景的一些未来研究方向:
- 更强大的模型:增强 MM-LLM 的能力,其中主要通过这四个关键途径:扩展模态、实现 LLM 多样化、提升多模态指令微调的数据集质量、增强多模态生成能力。
- 难度更大的基准
- 移动 / 轻量级部署
- 具身智能
- 持续指令微调
























