













只会「看书」的大语言模型,有现实世界的视觉感知力吗?通过对字符串之间的关系进行建模,关于视觉世界,语言模型到底能学会什么?
最近,麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)的研究人员对语言模型的视觉能力进行了系统的评估,从简单形状、物体到复杂场景,要求模型不断生成和识别出更复杂的视觉概念,并演示了如何利用纯文本模型训练出一个初步的视觉表征学习系统。

论文链接:https://arxiv.org/abs/2401.01862
由于语言模型无法以像素的形式输入或输出视觉信息,所以在研究中使用代码来渲染、表示图像。
虽然LLM生成的图像看起来不像自然图像,但从生成结果,以及模型可以自我纠正来看,对字符串/文本的精确建模可以教会语言模型关于视觉世界中的诸多概念。
此外,研究人员还探索了如何利用文本模型生成的图像来进行自监督视觉表征学习,结果也展现了其用作视觉模型训练的潜力,可以仅使用LLM对自然图像进行语义评估。
语言模型的视觉概念
先问一个问题:对于人来说,理解「青蛙」的视觉概念意味着什么?
知道它皮肤的颜色、有多少只脚、眼睛的位置、跳跃时的样子等细节就足够了吗?
人们普遍认为,要从视觉上理解青蛙的概念,需要看青蛙的图像,还需要从不同的角度和各种真实世界的场景中对青蛙进行观察。
如果只观察文本的话,可以多大程度上理解不同概念的视觉意义?
换到模型训练角度来看,大型语言模型(LLM)的训练输入就只有文本数据,但模型已经被证明可以理解有关形状、颜色等概念的信息,甚至还能通过线性转换到视觉模型的表征中。

也就是说,视觉模型和语言模型在世界表征方面是很相似的。
但现有的关于模型表征方法大多基于一组预先选择的属性集合来探索模型编码哪些信息,这种方法无法动态扩展属性,而且还需要访问模型的内部参数。
所以研究人员提出了两个问题:
1、关于视觉世界,语言模型到底了解多少?
2、能否「只用文本模型」训练出一个可用于自然图像的视觉系统?
为了找到答案,研究人员通过测试不同语言模型在渲染(render, 即draw)和识别(recognize, 即see)真实世界的视觉概念,来评估哪些信息包含在模型中,从而实现了测量任意属性的能力,而无需针对每个属性单独训练特征分类器。
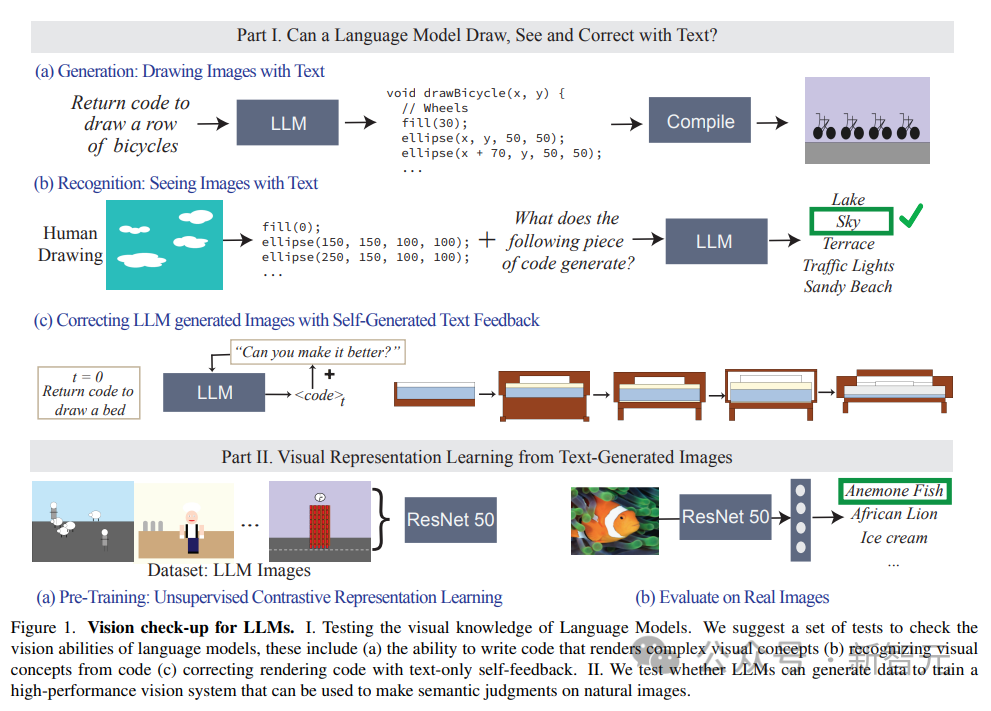
虽然语言模型无法生成图像,但像GPT-4等大模型可以生成出渲染物体的代码,文中通过textual prompt -> code -> image的过程,逐步增加渲染物体的难度来测量模型的能力。
研究人员发现LLM在生成由多个物体组成的复杂视觉场景方面出奇的好,可以高效地对空间关系进行建模,但无法很好地捕捉视觉世界,包括物体的属性,如纹理、精确的形状,以及与图像中其他物体的表面接触等。
文中还评估LLM识别感知概念的能力,输入以代码表示的绘画,代码中包括形状的序列、位置和颜色,然后要求语言模型回答代码中描述的视觉内容。

实验结果发现,LLM与人类正好相反:对于人来说,写代码的过程很难,但验证图像内容很容易;而模型则是很难解释/识别出代码的内容,但却可以生成复杂场景。
此外,研究结果还证明了语言模型的视觉生成能力可以通过文本纠错(text-based corrections)来进一步改善。
研究人员首先使用语言模型来生成说明概念的代码,然后不断输入提示「improve its generated code」(改善生成的代码)作为条件来修改代码,最终模型可以通过这种迭代的方式来改善视觉效果。

视觉能力数据集:指向场景
研究人员构建了三个文本描述数据集来测量模型在创建、识别和修改图像渲染代码的能力,其复杂度从低到高分别为简单的形状及组合、物体和复杂的场景。

1. 图形及其组成(Shapes and their compositions)
包含来自不同类别的形状组成,如点、线、2D形状和3D形状,具有32种不同的属性,如颜色、纹理、位置和空间排列。
完整的数据集包含超过40万个示例,使用其中1500个样本进行实验测试。
2. 物体(Objects)
包含ADE 20K数据集的1000个最常见的物体,生成和识别的难度更高,因为包含更多形状的复杂的组合。
3. 场景(Scenes)
由复杂的场景描述组成,包括多个物体以及不同位置,从MS-COCO数据集中随机均匀抽样1000个场景描述得到。
数据集中的视觉概念都是用语言进行描述的,例如场景描述为「一个阳光明媚的夏日,在海滩上,有着蔚蓝的天空和平静的海洋」(a sunny summer day on a beach, with a blue sky and calm ocean)。
在测试过程中,要求LLM根据描绘的场景来生成代码并编译渲染图像。
实验结果
评估模型的任务主要由三个:
1. 生成/绘制文本:评估LLM在生成对应于特定概念的图像渲染代码方面的能力。
2. 识别/查看文本:测试LLM在识别以代码表示的视觉概念和场景方面的性能。我们测试每个模型上的人类绘画的代码表示。
3. 使用文本反馈纠正绘图:评估LLM使用自身生成的自然语言反馈迭代修改其生成代码的能力。
测试中对模型输入的提示为:write code in the programming language [programming language name] that draws a [concept]
然后根据模型的输出代码进行编译并渲染,对生成图像的视觉质量和多样性进行评估:
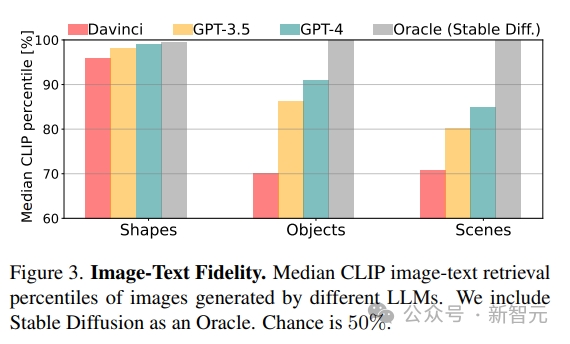
1. 忠实度(Fidelity)
通过检索图像的最佳描述来计算生成的图像与真实描述之间的忠实度。首先使用CLIP得分计算每个图像与同一类别(形状/物体/场景)中所有潜在描述之间的一致性,然后以百分比报告真实描述的排序(例如,得分100%意味着真实概念排名第一)。
2. 多样性(Diversity)
为了评估模型渲染不同内容的能力,在代表相同视觉概念的图像对上使用LPIPS多样性得分。
3. 逼真度(realism)
对于从ImageNet的1K图像的采样集合,使用Fréchet Inception Distance(FID)来量化自然图像和LLM生成的图像的分布差异。
对比实验中,使用Stable Diffusion获得的模型作为基线。
LLM能可视化(visualize)什么?
研究结果发现,LLM可以从整个视觉层次可视化现实世界的概念,对两个不相关的概念进行组合(如汽车形状的蛋糕),生成视觉现象(如模糊图像),并设法正确解释空间关系(如水平排列「一排自行车」)。
意料之中的是,从CLIP分数结果来看,模型的能力会随着从形状到场景的概念复杂性的增加而下降。
对于更复杂的视觉概念,例如绘制包含多个对象的场景,GPT-3.5和GPT-4在使用processing和tikz绘制具有复杂描述的场景时比python-matplotlib和python-turtle更准确。
对于物体和场景,CLIP分数表明包含「人」,「车辆」和「户外场景」的概念最容易绘制,这种渲染复杂场景的能力来自于渲染代码的表现力,模型在每个场景中的编程能力,以及所涉及的不同概念的内部表征质量。
LLM不能可视化什么?
在某些情况下,即使是相对简单的概念,模型也很难绘制,研究人员总结了三种常见的故障模式:
1. 语言模型无法处理一组形状和特定空间组织(space organization)的概念;
2. 绘画粗糙,缺乏细节,最常出现在Davinci中,尤其是在使用matplotlib和turtle编码时;
3. 描述是不完整的、损坏的,或只表示某个概念的子集(典型的场景类别)。
4. 所有模型都无法绘制数字。
多样性和逼真度
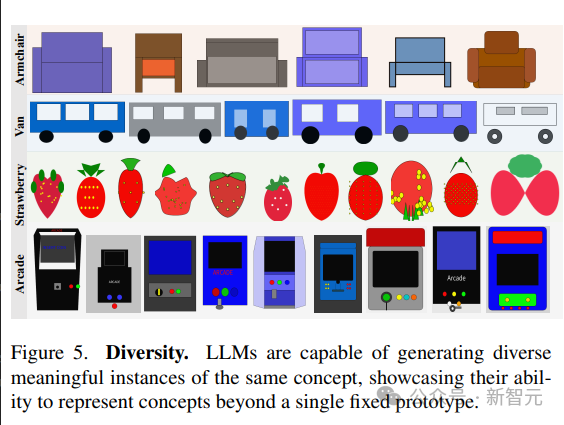
语言模型展示了生成相同概念的不同可视化的能力。
为了生成相同场景的不同样本,文中对比了两种策略:
1. 从模型中重复采样;
2. 对参数化函数进行采样,该参数化函数允许通过更改参数来创建概念的新绘图。
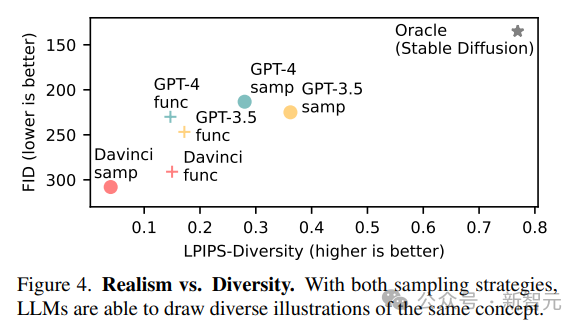
模型呈现视觉概念的多样化实现的能力反映在高LPIPS多样性分数中;生成不同图像的能力表明,LLM能够以多种方式表示视觉概念,而不局限于一组有限的原型。
LLM生成的图像远不如自然图像真实,与Stable Diffusion相比,模型在FID指标上得分很低,但现代模型的性能要比旧模型更好。
从文本中学习视觉系统
训练和评估
研究人员使用无监督学习得到的预训练视觉模型作为网络骨干,使用MoCo-v2方法在LLM生成的130万384×384图像数据集上训练ResNet-50模型,总共200个epoch;训练后,使用两种方法评估在每个数据集上训练的模型的性能:
1. 在ImageNet-1 k分类的冻结主干上训练线性层100 epoch,
2. 在ImageNet-100上使用5-最近邻(kNN)检索。

从结果中可以看到,仅使用LLM生成的数据训练得到的模型,就可以为自然图像提供强大的表征能力,而无需再训练线性层。
结果分析
研究人员将LLM生成的图像与现有程序生成的图像进行对比,包括简单的生成程序,如dead-levaves,fractals和StyleGAN,以生成高度多样化的图像。
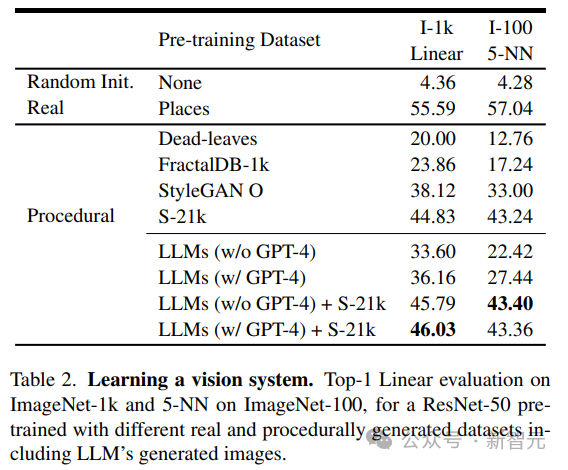
从结果中来看,LLM方法要优于dead-levaves和fractals,但还不是sota;在对数据进行人工检查后,研究人员将这种劣效性(inferiority)归因于大多数LLM生成的图像中缺乏纹理。
为了解决这一问题,研究人员将机Shaders-21k数据集与从LLM获得的样本相结合以生成纹理丰富的图像。
从结果中可以看到,该方案可以大幅提升性能,并优于其他基于程序生成的方案。




























