













数据环境在 2023 年发生了重大变化,为数据工程团队带来了新的机遇(和潜在挑战)。今年,我们将在分析、OLAP、数据工程和服务层领域看到以下内容,这将为团队提供更好的协议和更多工具选择。

(MeSSrro/Shutterstock)
数据湖预测
从 Hadoop 继续前进: 2023 年,DuckDB (C++)、Polars (Rust) 和 Apache Arrow (Go、Rust、Javascript 等)等工具变得非常流行,将 JVM 和 C/Python 在分析领域的完全主导地位出现裂缝。
我们预测,JVM之外的创新步伐将会加快,这将现有的基于Hadoop的架构送入传统抽屉当中。
虽然大多数公司已经没有直接使用Hadoop,但目前的大部分技术仍然建立在Hadoop的脚本之上:Apache Spark完全依赖Hadoop的I/O实现来访问其底层数据。许多湖仓一体架构要么基于 Apache Hive 样式,要么更直接地基于 Hive 元存储及其接口,以在其存储层之上创建表格抽象。
虽然Hadoop和Hive本身并没有问题,但它们已经不再代表最先进的技术。这次,它们完全基于JVM。JVM现在的性能令人难以置信,当然如果想从没有变得更快的CPU中获得绝对最好的选择,这仍然不太可能。
此外,Apache Hive通过抽象出Hadoop的底层分布式特性,并在分布式文件系统之上暴露熟悉的SQL(-ish)表抽象,这标志着大数据处理向前迈出了一大步。由此可以看到,它已经开始显示年龄和局限性:缺乏事务性和并发性控制,缺乏元数据和数据之间的分离。 以及我们在 15+ 年中学到的其他经验教训。
今年,我们将看到 Apache Spark 从根源上继续前进:Databricks 已经有一个无 JVM 的 Apache Spark (Photon) 实现,而新的表格式(如 Apache Iceberg)也通过实现表目录的开放规范,以及为 I/O 层提供更现代的方法,并从集体 Hive 根源中走出来。
元商店之战
随着 Hive 即成为过去,以及 Delta Lake 和 Iceberg 等 Open Table 格式变得无处不在,任何数据架构中的核心组件也正在被取代——“元存储”。对象存储或文件系统上的文件与它们所表示的表格和实体之间的间接层。虽然表格格式是开放的,但它们的元存储似乎越来越专有和锁定。
Databricks 正在积极推动用户使用其 Unity Catalog,AWS 拥有 Glue,Snowflake 也有自己的目录实现。这些是不可互操作的,并且在许多方面成为希望利用新表格格式提供开放性的用户锁定供应商的一种手段。我们预测,在某个时候,钟摆会摆回去——因为用户将朝着更高的标准化和灵活性方向发展。
大数据工程作为一种实践将走向成熟
随着分析和数据工程变得越来越普遍,大量的技术正在快速增长,最佳实践也开始出现。
2023 年,我们看到促进结构化开发-测试-发布数据工程方法的工具变得更加主流。DBT非常受欢迎和成熟。从Great Expectations、Monte Carlo和其他质量和可观测性平台等工具的成功来看,可观测性和监控现在也被视为不仅仅是锦上添花。lakeFS 提倡对数据本身进行版本控制,以允许类似 git 的分支和合并,从而构建健壮的、可重复的开发-测试-发布管道。
此外,我们现在还看到,从Snowflake和Databricks到初创公司,每个人都在推广数据网格和数据产品等模式,以填补围绕这些模式仍然存在的工具空白。
因此,我们将在 2024 年看到旨在帮助用户实现这些目标的工具激增。从以数据为中心的监控和日志记录到测试工具和更好的 CI/CD 选项,软件工程实践还有很多工作要做,现在是缩小这些差距的正确时机。
服务层预测
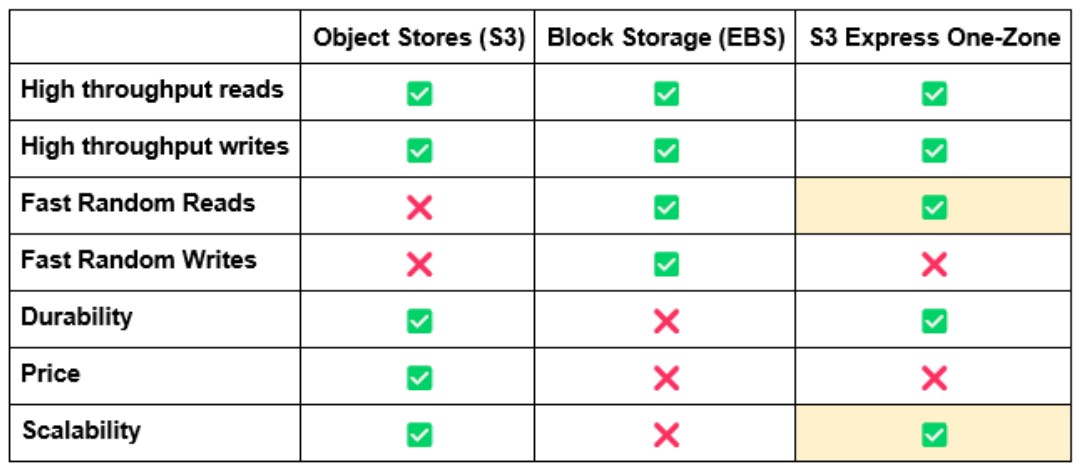
云原生应用程序将把更大份额的状态转移到对象存储中: 2023 年底,AWS 宣布了自 2006 年成立以来最大的功能之一,即其核心存储服务 S3。
该功能“S3 Express One-Zone”允许用户使用与 S3 提供的相同*标准对象存储 API,但访问数据的延迟始终如一的坚持个位数毫秒,成本大约是 API 调用的一半。
这标志着一个巨大的变化。到目前为止,对象存储的用例有些狭窄:虽然它们允许存储几乎无限量的数据,但即使您只想读取少量数据,您也必须接受更长的访问时间。
这种权衡显然使它们在分析和大数据处理中非常受欢迎。因为在这些领域,延迟通常不如整体吞吐量重要,但这意味着数据库、HPC 和面向用户的应用程序等低延迟系统不能真正依赖它们作为其关键路径的一部分。
如果他们使用了对象存储,则通常采用存档或备份存储层的形式。如果想要快速访问,则必须选择以某种形式附加到实例的块存储设备,并放弃对象存储提供的可扩展性和持久性优势。我们相信 S3 Express One-Zone 是改变这种状况的第一步。
S3 是新的磁盘驱动器,通过一致、低延迟的读取,现在理论上可以构建完全不依赖块存储的完全对象存储支持的数据库。
我们预测,在2024年,我们将看到更多的可操作数据库开始在实践中采用这一概念:允许数据库在完全短暂的计算环境中运行,完全依靠对象存储来实现持久性。
(图片来源:Oz Katz)
业务数据库将开始分解
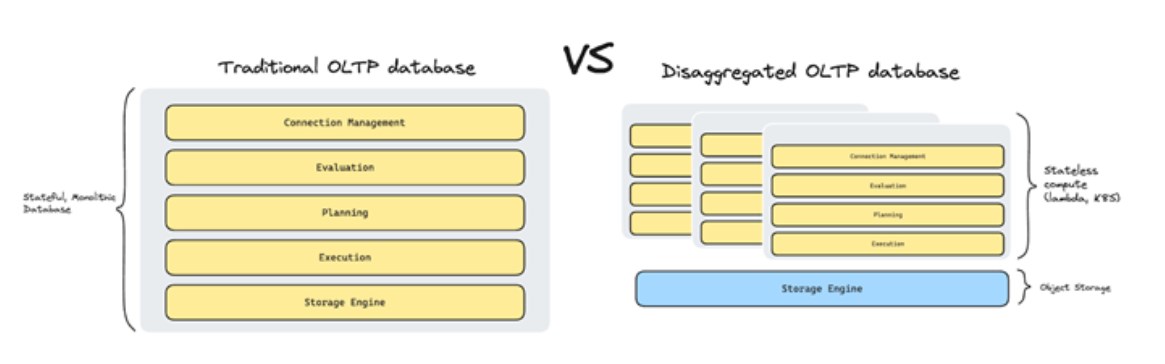
考虑到前面的预测,我们可以将这种方法更进一步:如果我们像标准化 OLAP 一样标准化 OLTP 的存储层会怎样?
数据湖的最大承诺之一是能够将存储和计算分开,以便一种技术写入的数据可以被另一种技术读取。这使开发人员可以自由选择最适合其用例的最佳堆栈。但是,有了 Apache Parquet、Delta Lake 和 Apache Iceberg 等技术,现在这是可行的。
如果我们设法将用于操作数据访问的格式标准化,会怎么样?让我们想象一个键/值抽象(可能类似于 LSM sstables?),它允许存储排序的键值对,为对象存储进行最佳布局。
我们可以部署一个无状态的RDBMS,在上面提供查询解析/规划/执行功能,甚至作为一个按需的lambda函数。另一个系统可能会使用相同的存储抽象来存储用于搜索的反排索引,或者用于存储酷炫的生成式 AI 应用程序的向量相似性索引。
虽然不相信一年后我们会将所有数据库作为 lambda 函数运行,但确实将看到从“对象存储作为存档层”到更多“对象存储作为记录系统”的转变,在操作数据库中也会发生。
(图片来源:Oz Katz)
最后的思考
乐观地认为,2024 年将继续朝着正确的方向发展数据格局:更好的抽象、改进堆栈不同部分之间的接口,以及技术发展的新功能。
虽然它们并不总是完美的,以牺牲易用性会以较低的灵活性为代价。但是,在过去二十年中,看到这个生态系统的发展,我认为我们的状况比以往任何时候都好。
我们比以往任何时候都有更多的选择、更好的协议和工具,以及更低的进入门槛。
文章标题:Data Engineering in 2024: Predictions For Data Lakes and The Serving Layer
文章作者:Oz Katz

















