比斯坦福炒虾机器人还厉害的机器人来了!
最近,CMU的研究者只花费2.5万美元,就打造出一个在开放世界中可以自适应移动操作铰接对象的机器人。
 论文地址:https://arxiv.org/abs/2401.14403
论文地址:https://arxiv.org/abs/2401.14403
厉害之处就在于,它是完全自主完成操作的。
看,这个机器人能自己打开各式各样的门。
无论是需要按一下把手才能打开的门。

需要推开的门。

透明的弹簧门。

甚至是昏暗环境中的门。

它还能自己打开橱柜。

打开抽屉。

自己打开冰箱。

甚至,它的技能推广到训练以外的场景。
结果发现,一个小时内,机器人学会打开20个从未见过的门,成功率从行为克隆预训练的50%,飙升到在线自适应的95%。
即使眼前是一个它从未见过的门,这个优秀的小机器人也顺利打开了!


英伟达高级科学家Jim Fan表示:
斯坦福的ALOHA虽然令人印象深刻,但很多动作都需要人类协同控制,但这个机器人,则是完全自主完成的一系列操作。
它背后的核心思想,就是在测试时进行RL,使用CLIP(或任何视觉语言模型)作为学习的奖励函数。
这样,就像ChatGPT用RLHF进行预训练一样,机器人可以对人类收集的轨迹进行预训练(通过远程控制),然后通过新场景进行RLHF,这样就掌握了训练以外的技能。

这项工作一经发布,立刻获得了同行们的肯定。
「恭喜!这是将机械臂带出实验室的好装置。」

「太令人激动了,让机器人在线学习技能前景巨大!」

「如此便宜的定制硬件,会让移动操作变得疯狂。」

「永远不要惹一个机器人,它已经学会开门了。」

让我们具体看看,这个机器人是如何完成未见过的开门任务。
机器人自适应学习,性能暴涨至90%
当前多数机器人移动操作,仅限于拾取-移动-放置的任务。
由于多种原因,在「开放世界」中开发和部署,能够处理看不见的物体机器人系统具有极大的挑战性。
针对学习「通用移动操作」的挑战,研究人员将研究重点放在一类有限的问题——涉及铰接式物体的操作,比如开放世界中的门、抽屉、冰箱或橱柜。
别看,开门、打开抽屉、冰箱这种日常生活中的操作对于每个人来说,甚至小孩子来说轻而易举,却是机器人的一大挑战。
对此,CMU研究人员提出了「全栈」的方法来解决以上问题。

为了有效地操纵开放世界中的物体,研究中采用了「自适应学习」的框架,机器人不断从交互中收集在线样本进行学习。
这样一来,即使机器人遇到了,不同铰接模式或不同物理参数(因重量或摩擦力不同)的新门,也可以通过交互学习实现自适应。

为了实现高效学习,研究人员使用一种结构化的分层动作空间。它使用固定的高级动作策略和可学习的低层控制参数。
使用这种动作空间,研究人员通过各种远程操作演示的数据集,初始化了策略(BC)。这为探索提供了一个强有力的先验,并降低了执行不安全动作的可能性。
成本仅2.5万美金
此前,斯坦福团队在打造Mobile ALOHA的所有成本用了3万美元。
而这次,CMU团队能够以更便宜的成本——2.5万美元(约18万元),打造了一台在通用世界使用的机器人。

如下图3所示,展示了机器人硬件系统的不同组件。
研究人员选用了AgileX的Ranger Mini 2底座,因其具有稳定性,全向速度控制,和高负载称为最佳选择。
为了使这样的系统有效,能够有效学习至关重要,因为收集现实世界样本的成本很高。
使用的移动机械手臂如图所示。

手臂采用了xArm进行操作,有效负载为5公斤,成本较低,可供研究实验室广泛使用。
CMU机器人系统使用了Jetson计算机来支持传感器、底座、手臂,以及托管LLM的服务器之间的实时通信。

对于实验数据的收集,是通过安装在框架上的D435 IntelRealsense摄像头来收集RGBD图像,并使用T265 Intel Realsense摄像头来提供视觉里程计,这对于在执行RL试验时重置机器人至关重要。
另外,机器人抓手还配备了3D打印抓手和防滑带,以确保安全稳定的抓握。
研究人员还将创建的模块化平台的关键方面,与其他移动操纵平台进行比较。
看得出,CMU的机器人系统不论是在手臂负载力,还是移动自由度、全向驱动的底座、成本等方面具有明显的优势。
 机器人成本
机器人成本
 机械臂成本
机械臂成本
原始实现
参数化原始动作空间的实现细节如下。
抓取
为了实现这个动作,对于从实感相机获得的场景RGBD图像,研究者使用现成的视觉模型,仅仅给出文本提示,就能获取门和把手的掩码。
此外,由于门是一个平面,因此可以使用相应的掩码和深度图像,来估计门的表面法线。
这就可以将底座移动到靠近门的地方,使其垂直,并设置抓握把手的方向角度。
使用相机校准,将把手的2D掩码中心投影到3D坐标,这就是标记的抓取位置。
原始抓取的低级控制参数,会指示要抓取位置的偏移量。
这是十分有益的,因为根据把手的类型,机器人可能需要到达稍微不同的位置,通过低级连续值参数,就可以来学习这一点。
约束移动操纵
对于机器人手臂末端执行器和机器人底座,研究者使用了速度控制。
通过在SE2平面中的6dof臂和3dof运动,他们创建了一个9维向量。
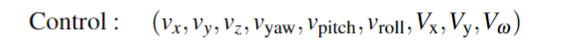
其中前6个维度对应手臂的控制,后三个维度对应底座。
研究者使用原始数据,对该空间施加了如下约束——

在控制机器人时,策略会输出与要执行的原始数据相对应的索引,以及运动的相应低级参数。
低级控制命令的值从-1到1连续,并且会在一段固定的持续时间内执行。
参数的符号决定了速度控制的方向,顺时针或逆时针用于解锁和旋转,向前或向后用于打开物体。
预训练数据集
在这个项目中考虑的铰接物体,由三个刚性部分组成:底座部分、框架部分和手柄部分。
其中包括门、橱柜、抽屉和冰箱等物体。
它们的底座和框架通过旋转接头(如在橱柜中)或棱柱接头(如在抽屉中)连接。框架通过旋转接头或固定接头连接到手柄。
因此,研究者确定了铰接物体的四种主要类型,分类取决于与手柄的类型和关节机构。
手柄关节通常包括杠杆(A型)和旋钮(B型)。
对于手柄没有铰接的情况,主体框架可以使用旋转接头(C型)绕铰链旋转,或者沿着柱接头(例如抽屉)前后滑动(D型)。
虽然并不详尽,但可以说这四种分类基本涵盖了机器人系统可能遇到的各种日常铰接物体。

然而,总还有机器人看不到的新型铰接物体,为了提供操作这些新型铰接物体的泛化优势,研究者首先收集了离线演示数据集。
在BC训练数据集中,包含了每个类别的3个对象,研究者为每个对象收集10个演示,总共生成120个轨迹。
此外,研究者还为每个类别保留了2个测试对象,用于泛化实验。
训练和测试对象在视觉外观(例如纹理、颜色)、物理动力学(例如弹簧加载)和驱动(例如手柄关节可能是顺时针或逆时针)方面存在显着差异。

在图4中,包含了训练和测试集中使用的所有对象的可视化,以及它们来自集合的哪个部分,如图5所示。

自主安全的在线自适应
在这项工作中,研究者们面临的最大挑战就在于,如何使用不属于BC训练集的新对象进行操作?
为了解决这个问题,他们开发了一个能够完全自主强化学习(RL)在线适应的系统。
安全意识探索
确保机器人所采取的探索动作对其硬件来说是安全的,这一点至关重要,特别是它是在关节约束下与物体交互的。
理想情况下,机器人应该可以解决动态任务,比如使用不同力量控制开门。
然而,研究者使用的xarm-6这种低成本手臂,不支持精确的力感应。

因此,为了部署系统,研究者使用了基于在线采样期间读取联合电流的安全机制。
如果机器人采样到导致关节电流达到阈值的动作,该事件就会终止,并重置机器人,以防止手臂可能会损害到自身,并且会提供负面奖励,来抑制此类行为。
奖励规范
在实验中,人类操作员会给机器人提供奖励。
如果机器人成功开门,则奖励+1,如果失败则奖励0,如果存在安全违规则奖励-1。
这种奖励机制是可行的,因为系统只需要很少的样本来学习。
然而,对于自主学习,研究者希望消除依赖人类出现在循环中的瓶颈。
在这种情况下,他们研究了使用大型视觉语言模型作为奖励来源的办法。
具体来说,他们使用CLIP来计算两个文本提示与机器人执行后观察到的图像之间的相似度得分。
研究者使用的两个提示是「门已关闭」和「门已打开」,他们会计算最终观察到的图像和每个提示的相似度得分。
如果图像更接近指示门打开的提示,则分配奖励+1,否则分配奖励0。如果触发安全保护,奖励为-1。

复位机制
在这个过程中,机器人会采用视觉里程计,利用安装在其底座上的T265跟踪摄像头,使其能够导航回初始位置。
每次行动结束时,机器人会放开抓手,并移回原来的SE2基地位置,并拍摄If的图像以用于计算奖励。
然后,研究者对SE2基地位置进行随机扰动,以便策略变得更加稳健。
此外,如果奖励为1,门被打开时,机器人就会有一个脚本例程,来把门关上。
实验结果
研究人员在CMU校园内四栋不同建筑中(12个训练对象和8个测试对象),对全新架构加持的机器人系统进行了广泛的研究。
具体回答了以下几个问题:
1)系统能否通过跨不同对象类别的在线自适应,来提高未见过对象的性能?
2)这与仅在提供的演示中,使用模仿学习相比如何?
3)可以使用现成的视觉语言模型自动提供奖励吗?
4)硬件设计与其他平台相比如何?(硬件部分已进行了比较)
在线自适应
a. 不同物体类别评估
研究人员在4个类别的固定衔接物体上,对最新的方法进行了评估。
如下图6所示,呈现了从行为克隆初始策略开始,利用在线交互进行5次迭代微调的持续适应性能。
每次改进迭代包括5次策略rollout,之后使用等式5中的损失对模型进行更新。

可以看到,最新方法将所有对象的平均成功率从50%提高到95%。因此,通过在线交互样本不断学习能够克服初始行为克隆策略的有限泛化能力。
自适应学习过程能够从获得高奖励的轨迹中学习,然后改变其行为,更频繁地获得更高的奖励。
在BC策略性能尚可的情况下,比如平均成功率约为70%的C类和D类对象,RL能够将策略完善到100%的性能。
此外,即使初始策略几乎无法执行任务,强化学习也能够学习如何操作对象。这从A类实验中可以看出,模仿学习策略的成功率非常低,只有10%,完全无法打开两扇门中的一扇。
通过不断的练习,RL的平均成功率可以达到90%。
这表明,RL可以从模仿数据集中探索出可能不在分布范围内的动作,并从中学习,让机器人学会如何操作未见过的新颖的铰接物体。
b. Action-replay基线
还有另一种非常简单的方法,可以利用演示数据集在新对象上执行任务。
研究团队针对2个特别难以进行行为克隆的对象(A类和B类各一个(按压杠杆和旋钮手柄)运行了这一基线。
这里,采取了开环和闭环两种方式对这一基线进行评估。
在前一种情况下,只使用第一张观察到的图像进行比较,并执行整个检索到的动作序列;而在后一种情况下,每一步执行后都会搜索最近的邻居,并执行相应的动作。
从表3中可以看出,这种方法非常无效,进一步凸显了实验中训练对象和测试对象之间的分布差距。

c. 通过VLM自主奖励
CMU团队还研究是否可以通过自动程序来提供奖励,从而取代人工操作。
正如Action-replay基线一样,研究人员在两个测试门上对此进行评估,每个门都从把手和旋钮类别进行评估。
从表2中,使用VLM奖励的在线自适应性能与使用人类标注的地面实况奖励相近,平均为80%,而使用人类标注的奖励则为90%。

另外,研究人员还在图7中报告了每次训练迭代后的性能。学习循环中不再需要人类操作员,这为自主训练和改进提供了可能性。

为了成功操作各种门,机器人需要足够坚固才能打开并穿过它们。
研究人员根据经验与另一种流行的移动操纵系统进行比较,即Stretch RE1(Hello Robot)。
他们测试机器人由人类专家远程操作,以打开不同类别的两扇门的能力,特别是杠杆门和旋钮门。每个物体都进行了5次试验。
如表IV所示,这些试验的结果揭示了Stretch RE1的一个重大局限性:即使由专家操作,其有效负载能力也不足以打开真正的门,而CMU提出的AI系统在所有试验中都取得了成功。

总而言之,CMU团队在这篇文章中提出了一个全栈系统,用于在开放世界中进行进行自适应学习,以操作各种铰接式物体,例如门、冰箱、橱柜和抽屉。
最新AI系统通过使用高度结构化的动作空间,能够从很少的在线样本中学习。通过一些训练对象的演示数据集进一步构建探索空间。
CMU提出的方法能够将来自4个不同对象类别中,8个不可见对象的性能提高约50%-95%。
值得一提的是,研究还发现这一系统还可以在无需人工干预的情况下通过VLM的奖励进行学习。
作者介绍
Haoyu Xiong

Haoyu Xiong是CMU计算机科学学院机器人研究所的研究生研究员,专注于人工智能和机器人技术。他的导师是Deepak Pathak。
Russell Mendonca

Russell Mendonca是CMU大学机器人研究所的三年级博士生,导师是Deepak Pathak。他本人对机器学习、机器人学和计算机视觉中的问题非常感兴趣。
之前,他曾毕业于加州大学伯克利分校电气工程和计算机科学专业,并在伯克利人工智能实验室(BAIR)与Sergey Levine教授一起研究强化学习。
Kenneth Shaw

Kenneth Shaw是卡内基梅隆大学机器人研究所的一年级博士生,导师同样是Deepak Pathak。他的研究重点是,实现与人类一样的机械手的灵巧操作。机械手应该如何设计成是何在我们的日常生活中应用?我们如何教机械手模仿人类?最后,我们如何使用模拟和大规模数据来解锁新的灵巧操作行为?
Deepak Pathak

Deepak Pathak是卡内基梅隆大学计算机科学学院的助理教授,还是机器人研究所的成员。他的工作是人工智能,是计算机视觉、机器学习和机器人学的交汇点。