













如今,大型语言模型(LLM)及其高级提示策略的出现,标志着对语言模型的研究取得了重大进展,尤其是在经典的 NLP 任务中。这其中一个关键的创新是思维链(CoT)提示技术,该技术因其在多步骤问题解决中的能力而闻名。这项技术遵循了人类的顺序推理,在各种挑战中表现出了优秀的性能,其中包括跨域、长泛化和跨语言的任务。CoT 及其富有逻辑的、循序渐进的推理方法,在复杂的问题解决场景中提供了至关重要的可解释性。
尽管 CoT 取得了长足的进展,但研究界尚未就 CoT 及其变体的具体机制和有效原因达成共识。这种知识差距意味着提高 CoT 性能仍是一个探索领域。而这种探索主要依赖于试错,因为目前还缺乏改进 CoT 效果的系统性方法论,研究人员只能依赖猜测和实验。但是这也同时表明该领域存在着重要的研究机遇:对 CoT 的内部运作形成更深入、更结构化的理解。如果实现这个目标,不仅能揭开当前 CoT 过程的神秘面纱,还能为在各种复杂的 NLP 任务中更可靠、更高效地应用这种技术铺平道路。
来自美国西北大学、利物浦大学和新泽西理工大学等的研究者们,进一步探讨了推理步骤的长度与结论准确性之间的关系,帮助人们加深关于如何有效解决 NLP 问题的理解。下面这篇文章探索了推理步骤是否是促使 CoT 发挥作用的 prompt 中最关键的部分(见图 1)。本文实验中严格的控制变量,特别是在加入新的推理步骤时,研究者会确保不会引入额外的知识。在零样本实验中,研究者将初始 prompt 从「请逐步思考」调整为「请逐步思考,并且尽可能思考出更多的步骤」。对于小样本问题,研究者设计了一个实验,在保持所有其他因素不变的情况下,扩展基础推理步骤。

- 论文标题:The Impact of Reasoning Step Length on Large Language Models
- 论文链接:https://arxiv.org/pdf/2401.04925.pdf

本文的第一组实验评估了在上述策略下,使用 Auto-CoT 技术,在零样本和小样本任务中推理性能的提高情况。随后,本文评估了不同方法在不同推理步数下的准确性。接着,研究者扩大了调研对象,比较了本文提出的策略在不同 LLM(如 GPT-3.5 和 GPT-4)上的有效性。研究结果表明,在一定范围内,推理链的长度与 LLM 的能力之间存在明显的相关性。但耐人寻味的是,当研究者在推理链中引入误导信息时,性能仍然有所提高。这推导出了一个重要结论:影响性能的关键因素似乎是思维链的长度,而不是其准确性。
本文的主要发现如下所示:
- 对于小样本 CoT,推理步数和精度之间存在直接的线性关系。这为优化复杂推理中的 CoT 提示提供了一种可量化的方法。具体来说,增加 prompt 中的推理步骤大大提高了 LLM 在多个数据集上的推理能力。反过来,即使在保留了关键信息的情况下,缩短推理步骤也会显著削弱模型的推理能力。
- 即使是不正确的推理,如果能保持必要的推理长度,也能产生有利的结果。例如,在数学问题等任务中,过程中产生的中间数字出错也不太会影响最终结果。
- 增加推理步骤所产生的收益大小受限于任务本身:更简单的任务需要更少的步骤,而更复杂的任务则从更长的推理序列中获得显著收益。
- 增加零样本 CoT 中的推理步骤也可以显著提高 LLM 的准确性。
研究方法
研究者通过分析来检验推理步骤与 CoT 提示性能之间的关系。方法的核心假设是,推理过程中的序列化步骤是 CoT 提示中最关键的组成部分,能够使语言模型在生成回复内容时应用更多的逻辑进行推理。为了测试这一观点,本文设计了一个实验,在 CoT 的推理过程中先后扩展和压缩基础推理步骤,同时保持所有其他因素不变。具体而言,研究者只系统地改变推理步骤的数量,不引入新的推理内容或删除已有的推理内容。研究者在下文中评估了零样本和少样本的 CoT 提示。整个实验过程如图 2 所示。通过这种控制变量分析的方法,研究者阐明了 CoT 如何影响 LLM 生成逻辑健全的应答能力。

零样本 CoT 分析
在零样本场景中,研究者将最初的 prompt 从「请逐步思考」修改为「请逐步思考,并且尽可能思考出更多的步骤」。之所以做出这一改变,是因为与少样本 CoT 环境不同,使用者不能在使用过程中引入额外的推理步骤。通过改变初始 prompt,研究者引导 LLM 进行了更广泛的思考。这种方法的重要性在于能够提高模型的准确性,而且不需要少样本场景中的典型方案:增量训练或额外的示例驱动优化方法。这种精细化策略确保了更全面、更详细的推理过程,显著提高了模型在零样本条件下的性能。
小样本 CoT 分析
本节将通过增加或压缩推理步骤来修改 CoT 中的推理链。其目的是研究推理结构的变化如何影响 LLM 决策。在推理步骤的扩展过程中,研究者需要避免引入任何新的任务相关信息。这样,推理步骤就成了唯一的研究变量。
为此,研究者设计了以下研究策略,以扩展不同 LLM 应用程序的推理步骤。人们思考问题的方式通常有固定的模式,例如,一遍又一遍地重复问题以获得更深入的理解、创建数学方程以减轻记忆负担、分析问题中单词的含义以帮助理解主题、总结当前状态以简化对主题的描述。基于零样本 CoT 和 Auto-CoT 的启发,研究者期望 CoT 的过程成为一种标准化的模式,并通过在 prompt 部分限制 CoT 思维的方向来获得正确的结果。本文方法的核心是模拟人类思维的过程,重塑思维链。表 6 中给出了五种通用的 prompt 策略。

- 单词思维:这种策略是要求模型解释单词并重建知识库。通常情况下,一个单词有多种不同的含义,这样做的效果是让模型跳出条条框框,根据生成的解释重新解释问题中的单词。这一过程不会引入新的信息。在 prompt 中,研究者给出了模型正在思考的单词的例子,模型会根据新问题自动挑选单词进行这一过程。
- 问题重载:反复阅读问题,减少其他文本对思维链的干扰。简而言之,让模型记住问题。
- 重复状态:与反复阅读类似,在一长串推理之后加入一个当前状态的小结,目的是帮助模型简化记忆,减少其他文本对 CoT 的干扰。
- 自我验证:人类在回答问题时会检查自己的答案是否正确。因此,在模型得到答案之前,研究者增加了一个自我验证过程,根据一些基本信息来判断答案是否合理。
- 方程制备:对于数学问题,制作公式可以帮助人类总结和简化记忆。对于一些需要假设未知数 x 的问题,建立方程是一个必不可少的过程。研究者模拟了这个过程,并让模型尝试在数学问题中建立方程。
总体而言,本文的即时策略都在模型有所体现。表 1 展示的内容是其中一个例子,其他四种策略的示例可以在原论文中查看。

实验及结果
推理步骤与准确性的关系
表 2 比较了使用 GPT-3.5-turbo-1106 在三类推理任务的八个数据集上的准确性。
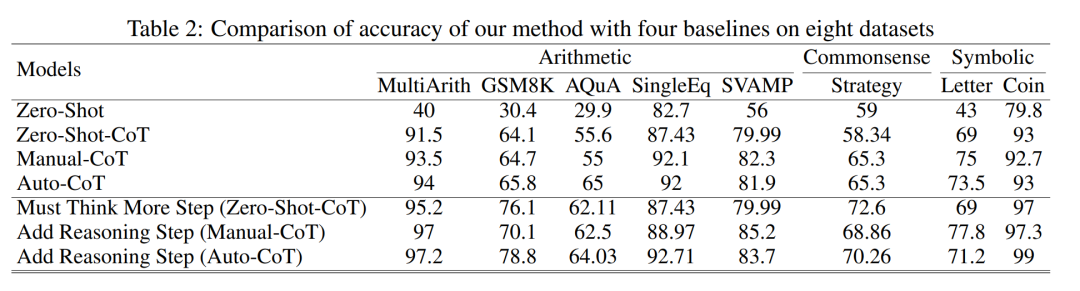
得益于研究者能够将思维链过程标准化,接下来就可以量化在 CoT 的基本流程中增加步骤而对准确性的提高程度。本实验的结果可以回答之前提出的问题:推理步骤与 CoT 性能之间的关系是什么?该实验基于 GPT-3.5-turbo-1106 模型。研究者发现,有效的 CoT 过程,例如在 CoT 过程中增加多达六个步骤的额外思维过程,会让大型语言模型推理能力都会得到提高,并且是在所有的数据集上都有体现。换句话说,研究者发现准确性和 CoT 复杂性之间存在一定的线性关系。

错误答案的影响
推理步骤是影响 LLM 性能的唯一因素吗?研究者做了以下尝试。将 prompt 中的一个步骤更改为不正确的描述,看看它是否会影响思维链。对于这个实验,本文研究者在所有 prompt 中添加一个错误。有关具体示例,请看表 3。

对于算术类型的问题,即使其中一个 prompt 结果出现偏差,对推理过程中思维链的影响也是微乎其微的,因此研究者认为在解决算术类型的问题时,大语言模型对提示中思维模式链的学习要多于单一计算。对于类似硬币数据的逻辑问题,prompt 结果中的一个偏差往往会带来整个思维链的支离破碎。研究者同样使用 GPT-3.5-turbo-1106 完成这项实验,并根据之前实验得出的每个数据集的最佳步数保证了性能。结果如图 4 所示。

压缩推理步骤
先前的实验已经证明了增加推理步骤可以提高 LLM 推理的准确性。那么在小样本问题中压缩基础推理步骤会损害 LLM 的性能吗?为此,研究者进行了推理步骤压缩实验,并采用实验设置中概述的技术,将推理过程浓缩成 Auto CoT 和 Few-Shot-CoT,减少推理步骤数。结果如图 5 所示。

结果显示,模型的性能显著下降,回归到与零样本方法基本相当的水平。这个结果进一步表明,增加 CoT 推理步骤可以提高 CoT 性能,反之亦然。
不同规格模型的性能对比
研究者还提出疑问,我们能否观察到缩放现象,即所需的推理步骤与 LLM 的大小有关?研究者研究了各种模型(包括 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4)中使用的平均推理步骤数。通过在 GSM8K 上的实验计算出了每个模型达到峰值性能所需的平均推理步骤。在 8 个数据集中,该数据集与 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4 的性能差异最大。可以看出,在初始性能最差的 text-davinci-002 模型中,本文提出的策略具有最高的提升效果。结果如图 6 所示。

协同工作实例中问题的影响
问题对 LLM 推理能力的影响是什么?研究者想探讨改变 CoT 的推理是否会影响 CoT 的性能。由于本文主要研究推理步骤对性能的影响,所以研究者需要确认问题本身对性能没有影响。因此,研究者选择了数据集 MultiArith 和 GSM8K 和两种 CoT 方法(auto-CoT 和 few-shot-CoT)在 GPT-3.5-turbo-1106 中进行实验。本文的实验方法包括对这些数学数据集中的样本问题进行有意的修改,例如改变表 4 中问题的内容。

值得注意的是,初步观察表明,这些对于问题本身的修改对性能的影响是几个要素里最小的,如表 5 所示。

这一初步发现表明,推理过程中步骤的长度是大模型的推理能力最主要的影响因素,问题本身的影响并不是最大的。
更多详细内容,请阅读原论文。















