译者 | 朱先忠
审校 | 重楼
异常值检测是一种无监督的机器学习任务,用于识别给定数据集中的异常(即“异常观测”)。在大量现实世界中,当我们的可用数据集已经被异常“污染”时,异常值检测任务对于整个机器学习环节来说是非常有帮助的。当前,开源框架Scikit learn已经实现了几种异常值检测算法,在我们持有未受污染的基准数据的情况下,我们也可以使用这些算法进行新颖检测。这是一项半监督任务,可以预测新的观测结果是否为异常值。

概述
本文中,我们将比较的四种异常值检测算法如下:
- 椭圆包络(Elliptic Envelope)适用于低维正态分布数据。顾名思义,它使用多元正态分布来创建一个距离度量指标,以便将异常值与内部值区分开来。
- 局部异常因子(Local Outlier Factor)是一种针对观测的局部密度与其邻居的局部密度的比较。密度比其邻居低得多的观测被视为异常值。
- 具有随机梯度下降的单类支持向量机(One-Class Support Vector Machine with Stochastic Gradient Descent)是一类SVM的O(n)近似解。请注意,O(n²)数量级的单类SVM在我们的小示例数据集上运行良好,但对于您的实际应用场景来说可能不切实际。
- 孤立森林(Isolation Forest)是一种基于树的方法,其中异常值通过随机拆分方法比使用内部值方法可实现更快的隔离。
由于我们的任务是无监督的;所以,我们没有基本事实来比较这些算法的准确性。相反,我们想看看他们的结果(尤其是球员排名方面)彼此之间的差异,并对他们的行为和局限性获得一些直觉,这样我们就可以知道什么时候更喜欢其中一名球员而不是另一名。
接下来,让我们使用2023年美国职业棒球大联盟(MLB)赛季击球手表现的两个指标来比较其中的一些技术吧:
- 上垒率(OBP),击球手每次上垒时(通过击球、保送或投球命中)上垒的速度
- Slugging(SLG),每次击球的平均总垒数
击球手表现还有许多更复杂的指标,例如OBP加SLG(OPS)、基本平均加权(wOBA)和调整后的加权跑动(WRC+)。然而,我们将看到,除了常用和易于理解之外,OBP和SLG具有适度的相关性和近似正态分布,使它们非常适合这种比较。
数据集准备
我们使用pybalball包来获取击球数据。该Python包接受MIT许可,能够取得来自于Fangraphs.com、Baseball-Reference.com和其他来源的数据;当然,这些来源反过来又是从美国职业棒球大联盟获得的官方记录数据。
我们使用pybalball的2023年击球统计数据,可以通过batting_stats(FanGraphs网站)或batting_stasts_bref(权威网站Baseball Reference)获得。事实证明,FanGraphs中的球员名称格式更正确,但Baseball Reference中的球员团队和联盟在交易球员的情况下格式更好。为了获得一个具有更高可读性的数据集,我们实际上需要合并三个表:FanGraphs、Baseball Reference和键查询。
from pybaseball import (cache, batting_stats_bref, batting_stats,
playerid_reverse_lookup)
import pandas as pd
cache.enable() # 重新运行时避免不必要的请求
MIN_PLATE_APPEARANCES = 200
# 为了可读性和合理的默认排序顺序
df_bref = batting_stats_bref(2023).query(f"PA >= {MIN_PLATE_APPEARANCES}"
).rename(columns={"Lev":"League",
"Tm":"Team"}
)
df_bref["League"] = \
df_bref["League"].str.replace("Maj-","").replace("AL,NL","NL/AL"
).astype('category')
df_fg = batting_stats(2023, qual=MIN_PLATE_APPEARANCES)
key_mapping = \
playerid_reverse_lookup(df_bref["mlbID"].to_list(), key_type='mlbam'
)[["key_mlbam","key_fangraphs"]
].rename(columns={"key_mlbam":"mlbID",
"key_fangraphs":"IDfg"}
)
df = df_fg.drop(columns="Team"
).merge(key_mapping, how="inner", on="IDfg"
).merge(df_bref[["mlbID","League","Team"]],
how="inner", on="mlbID"
).sort_values(["League","Team","Name"])数据探索
首先,我们注意到这些指标的均值和方差是不同的,并且它们之间具有适度的相关性。我们还注意到,每个指标都是相当对称的,中值接近平均值。
print(df[["OBP","SLG"]].describe().round(3))
print(f"\nCorrelation: {df[['OBP','SLG']].corr()['SLG']['OBP']:.3f}")
让我们使用以下方法来可视化上面的联合分布:
- 球员散点图,全国职业棒球联盟(NL)对美国联盟(AL)着色
- 球员的二元核密度估计器(KDE)图,用高斯核平滑散射图以估计密度
- 每个指标的边际KDE图
import matplotlib.pyplot as plt
import seaborn as sns
g = sns.JointGrid(data=df, x="OBP", y="SLG", height=5)
g = g.plot_joint(func=sns.scatterplot, data=df, hue="League",
palette={"AL":"blue","NL":"maroon","NL/AL":"green"},
alpha=0.6
)
g.fig.suptitle("On-base percentage vs. Slugging\n2023 season, min "
f"{MIN_PLATE_APPEARANCES} plate appearances"
)
g.figure.subplots_adjust(top=0.9)
sns.kdeplot(x=df["OBP"], color="orange", ax=g.ax_marg_x, alpha=0.5)
sns.kdeplot(y=df["SLG"], color="orange", ax=g.ax_marg_y, alpha=0.5)
sns.kdeplot(data=df, x="OBP", y="SLG",
ax=g.ax_joint, color="orange", alpha=0.5
)
df_extremes = df[ df["OBP"].isin([df["OBP"].min(),df["OBP"].max()])
| df["OPS"].isin([df["OPS"].min(),df["OPS"].max()])
]
for _,row in df_extremes.iterrows():
g.ax_joint.annotate(row["Name"], (row["OBP"], row["SLG"]),size=6,
xycoords='data', xytext=(-3, 0),
textcoords='offset points', ha="right",
alpha=0.7)
plt.show()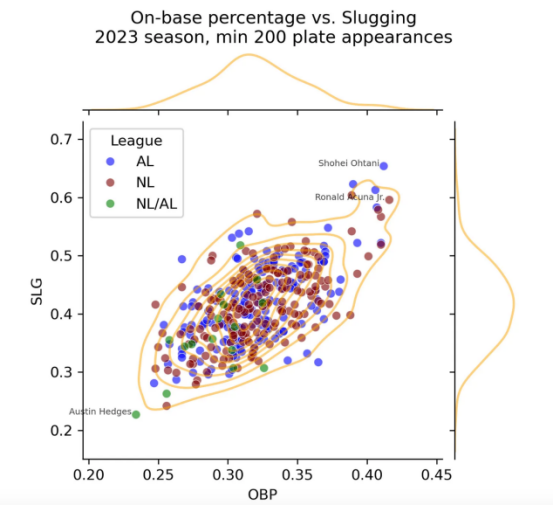
散点图的右上角显示了一组优秀的击球,对应于SLG和OBP分布的上部重尾。这个小团体擅长上垒和多垒击球。我们认为他们在多大程度上是异常值(因为他们与大多数球员群体的距离),而不是内部值(因为他们彼此接近),这取决于我们选择的算法所使用的定义。
应用异常值检测算法
Scikit-learn的异常值检测算法通常提供了fit()和predict()两种方法,但算法之间也有例外,也有不同之处。我们将单独考虑每个算法,但我们将每个算法拟合到每个球员(m=453)的属性矩阵(n=2)中。然后,我们不仅会为每个球员打分,还会为每个属性范围内的值网格打分,以帮助我们可视化预测函数。
为了可视化决策边界,我们需要采取以下步骤:
- 创建输入特征值的二维网格。
- 将decision_function应用于网格上的每个点,这需要拆开网格。
- 将预测重新成形为一个网格。
- 绘制预测。
在此,我们将使用200x200大小的网格来覆盖现有的观测结果和一些填充,但您可以将网格调整到所需的速度和分辨率。
import numpy as np
X = df[["OBP","SLG"]].to_numpy()
GRID_RESOLUTION = 200
disp_x_range, disp_y_range = ( (.6*X[:,i].min(), 1.2*X[:,i].max())
for i in [0,1]
)
xx, yy = np.meshgrid(np.linspace(*disp_x_range, GRID_RESOLUTION),
np.linspace(*disp_y_range, GRID_RESOLUTION)
)
grid_shape = xx.shape
grid_unstacked = np.c_[xx.ravel(), yy.ravel()]椭圆包络
椭圆包络的形状由数据的协方差矩阵确定,该协方差矩阵给出了特征i在主对角线[i,i]上的方差以及特征i和j在[i,j]位置上的协方差。由于协方差矩阵对异常值敏感,因此该算法使用最小协方差行列式(MCD)估计器,该估计器被推荐用于单峰和对称分布,通过随机混洗后的random_state输入参数以获得再现性。请注意,这个稳健的协方差矩阵稍后将再次派上用场。
因为我们想比较他们排名中的异常值分数,而不是二元异常值/内部分类,所以我们决定使用decision_function函数为球员打分。
from sklearn.covariance import EllipticEnvelope
ell = EllipticEnvelope(random_state=17).fit(X)
df["outlier_score_ell"] = ell.decision_function(X)
Z_ell = ell.decision_function(grid_unstacked).reshape(grid_shape)局部异常值因子
这种测量隔离度的方法基于k近邻(KNN)算法。我们计算每个观测到其最近邻居的总距离,以定义局部密度,然后将每个观测的局部密度与其邻近的局部密度进行比较。局部密度远小于其邻近的观测结果即被视为异常值。
选择要包括的邻近数量:在KNN中,经验法则是让K=sqrt(N),其中N是您的观察计数。根据这个规则,我们得到了一个接近20的K(这恰好是LOF的默认K)。您可以分别增加或减少K以减少过拟合或欠拟合。
K = int(np.sqrt(X.shape[0]))
print(f"Using K={K} nearest neighbors.")
选择一个距离指标:请注意,我们的特征是相关的,并且具有不同的方差,因此欧几里得距离不是很有意义。我们将使用Mahalanobis距离,这种距离更有助于体现特征比例和相关性。
在计算马氏距离时,我们将使用鲁棒性强的协方差矩阵。如果我们还没有通过椭圆包络计算它,那么我们可以直接计算它。
from scipy.spatial.distance import pdist, squareform
# 如果我们还没有椭圆包络,我们可以计算鲁棒性强的协方差:
# from sklearn.covariance import MinCovDet
# robust_cov = MinCovDet().fit(X).covariance_
# 但我们可以从椭圆包络中重复使用它:
robust_cov = ell.covariance_
print(f"Robust covariance matrix:\n{np.round(robust_cov,5)}\n")
inv_robust_cov = np.linalg.inv(robust_cov)
D_mahal = squareform(pdist(X, 'mahalanobis', VI=inv_robust_cov))
print(f"Mahalanobis distance matrix of size {D_mahal.shape}, "
f"e.g.:\n{np.round(D_mahal[:5,:5],3)}...\n...\n")
拟合局部异常因子:请注意,使用自定义距离矩阵需要将metric=“precomputed”传递给构造函数,然后将距离矩阵本身传递给fit方法。(有关更多详细信息,请参阅官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html#sklearn.neighbors.LocalOutlierFactor.fit)
还要注意,与其他算法不同,使用LOF时,我们被指示不要使用score_samples方法对现有观测值进行评分;该方法应仅用于新颖性检测。
from sklearn.neighbors import LocalOutlierFactor
lof = LocalOutlierFactor(n_neighbors=K, metric="precomputed", novelty=True
).fit(D_mahal)
df["outlier_score_lof"] = lof.negative_outlier_factor_创建决策边界:因为我们使用了自定义距离度量,所以我们还必须计算网格中每个点与原始观测值之间的自定义距离。以前,我们使用空间测度pdist来表示单个集合的每个成员之间的成对距离,但现在我们使用cdist来返回从第一组输入的每个成员到第二组输入的各个成员的距离。
from scipy.spatial.distance import cdist
D_mahal_grid = cdist(XA=grid_unstacked, XB=X,
metric='mahalanobis', VI=inv_robust_cov
)
Z_lof = lof.decision_function(D_mahal_grid).reshape(grid_shape)支持向量机(SGD-One-Class SVM)
SVM使用核技巧将特征转换到更高的维度,这样可以方便识别分离超平面。径向基函数(RBF)内核要求输入标准化,但正如StandardScaler的文档所指出的,该缩放器对异常值很敏感,所以我们将使用RobustScaler。正如SGDOneClassSVM的文档所建议的那样,我们将缩放后的输入管道传输到Nyström核近似中。
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import SGDOneClassSVM
suv = make_pipeline(
RobustScaler(),
Nystroem(random_state=17),
SGDOneClassSVM(random_state=17)
).fit(X)
df["outlier_score_svm"] = suv.decision_function(X)
Z_svm = suv.decision_function(grid_unstacked).reshape(grid_shape)孤立森林
这种基于树的隔离测量方法执行随机递归划分。如果隔离给定观测所需的平均分裂次数较低,则该观测被视为更强的候选异常值。与随机森林和其他基于树的模型一样,孤立森林并不假设特征是正态分布的,也不要求对其进行缩放。默认情况下,它构建100棵树。我们的示例仅使用两个特征,因此并没有启用特征采样。
from sklearn.ensemble import IsolationForest
iso = IsolationForest(random_state=17).fit(X)
df["outlier_score_iso"] = iso.score_samples(X)
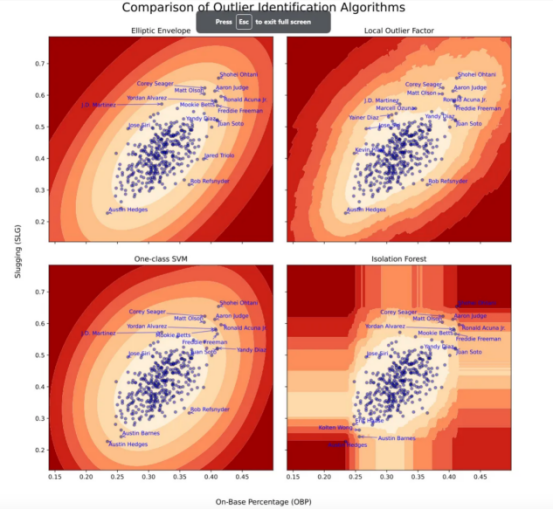
Z_iso = iso.decision_function(grid_unstacked).reshape(grid_shape)结果:检查决策边界
请注意,来自上述这些模型的预测生成了不同的分布结果。我们选择应用QuantileTransformer转换器,目的是使预测值在给定网格上更具视觉可比性。从官方文档中,请注意如下提示:
这种变换是非线性的。它可能会扭曲在同一测量标准下测量的变量之间的线性相关性,但会使在不同测量标准上测量的变量更直接地具有可比性。
from adjustText import adjust_text
from sklearn.preprocessing import QuantileTransformer
N_QUANTILES = 8 # 每个图表有这么多颜色断点
N_CALLOUTS=15 # 为每个图表标记这么多顶部异常值
fig, axs = plt.subplots(2, 2, figsize=(12, 12), sharex=True, sharey=True)
fig.suptitle("Comparison of Outlier Identification Algorithms",size=20)
fig.supxlabel("On-Base Percentage (OBP)")
fig.supylabel("Slugging (SLG)")
ax_ell = axs[0,0]
ax_lof = axs[0,1]
ax_svm = axs[1,0]
ax_iso = axs[1,1]
model_abbrs = ["ell","iso","lof","svm"]
qt = QuantileTransformer(n_quantiles=N_QUANTILES)
for ax, nm, abbr, zz in zip( [ax_ell,ax_iso,ax_lof,ax_svm],
["Elliptic Envelope","Isolation Forest",
"Local Outlier Factor","One-class SVM"],
model_abbrs,
[Z_ell,Z_iso,Z_lof,Z_svm]
):
ax.title.set_text(nm)
outlier_score_var_nm = f"outlier_score_{abbr}"
qt.fit(np.sort(zz.reshape(-1,1)))
zz_qtl = qt.transform(zz.reshape(-1,1)).reshape(zz.shape)
cs = ax.contourf(xx, yy, zz_qtl, cmap=plt.cm.OrRd.reversed(),
levels=np.linspace(0,1,N_QUANTILES)
)
ax.scatter(X[:, 0], X[:, 1], s=20, c="b", edgecolor="k", alpha=0.5)
df_callouts = df.sort_values(outlier_score_var_nm).head(N_CALLOUTS)
texts = [ ax.text(row["OBP"], row["SLG"], row["Name"], c="b",
size=9, alpha=1.0)
for _,row in df_callouts.iterrows()
]
adjust_text(texts,
df_callouts["OBP"].values, df_callouts["SLG"].values,
arrowprops=dict(arrowstyle='->', color="b", alpha=0.6),
ax=ax
)
plt.tight_layout(pad=2)
plt.show()
for var in ["OBP","SLG"]:
df[f"Pctl_{var}"] = 100*(df[var].rank()/df[var].size).round(3)
model_score_vars = [f"outlier_score_{nm}" for nm in model_abbrs]
model_rank_vars = [f"Rank_{nm.upper()}" for nm in model_abbrs]
df[model_rank_vars] = df[model_score_vars].rank(axis=0).astype(int)
# Averaging the ranks is arbitrary; we just need a countdown order
df["Rank_avg"] = df[model_rank_vars].mean(axis=1)
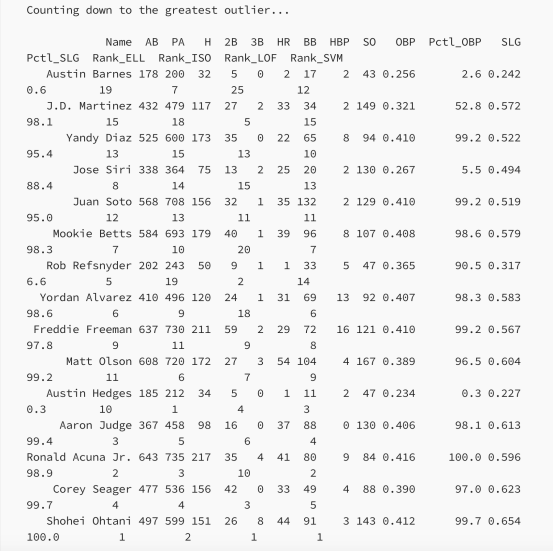
print("Counting down to the greatest outlier...\n")
print(
df.sort_values("Rank_avg",ascending=False
).tail(N_CALLOUTS)[["Name","AB","PA","H","2B","3B",
"HR","BB","HBP","SO","OBP",
"Pctl_OBP","SLG","Pctl_SLG"
] +
[f"Rank_{nm.upper()}" for nm in model_abbrs]
].to_string(index=False)
)
分析与结论
看起来上面四种实现方案在如何定义异常值方面基本保持一致,但在分值和易用性方面存在一些明显差异。
椭圆包络方法:在椭圆的短轴周围有更窄的轮廓,因此它倾向于突出那些与特征之间的整体相关性相反的有趣球员。例如,在这种算法下,光芒队的外野手JoséSiri更像是一个异类,因为他的SLG很高(第88百分位),而OBP很低(仅为第5百分位)。
椭圆包络在没有配置的情况下也很容易使用,并且它提供了具有鲁棒性的协方差矩阵。如果您有低维数据,并且合理地期望它是正态分布的(通常情况并非如此),那么您可能想先尝试这种简单的方法。
单分类算法:具有更均匀分布的轮廓,因此它倾向于比椭圆包络更强调沿整体相关方向的观测。全明星一垒手Freddie Freeman(道奇队)和Yandy Diaz(光芒队)在该算法下的排名比其他算法下的更靠前,因为他们的SLG和OBP都很出色(Freeman分别为第99和97百分位,Diaz分别为第98和95百分位)。
值得注意的是,RBF内核需要一个额外的步骤来进行标准化,但在这个简单的例子中,它似乎也能很好地工作,而无需进行微调。
局部异常因子:在前面提到的“优秀集群”上出现了一个小的双峰轮廓(在图表中几乎看不到)。由于道奇队的外野手/二垒手穆基·贝茨周围都是其他优秀的击球手,包括弗里曼、约丹·阿尔瓦雷斯和小罗纳德·阿库尼亚,他在LOF下仅排名第20,而在其他算法下排名第10或更强。相反,勇士队外野手Marcel Ozuna的SLG和OBP略低于Betts;但在LOF下,他更像是一个异类,因为他的邻近密度较小。
另外,值得注意的是,LOF实现是最耗时的,因为我们要创建的是用于拟合和评分的稳健的距离矩阵。当然,我们本可以花一些时间来调整K。
孤立森林:倾向于强调在特征空间的角落进行观察,因为分割分布在特征之间。替补捕手奥斯汀·赫奇斯于2023年效力于海盗队和流浪者队,并于2024年与守护者队签约。他具有很强的防守能力,但在SLG和OBP中都是最差的击球手(至少有200次板上击球)。赫奇斯可以在OBP或OPS上单独分离,使他成为最强的异类。隔离森林是唯一一种没有将大谷昭平列为最强异常值的算法:由于大谷昭平被小罗纳德·阿库尼亚在OBP中淘汰;因此,大谷昭和阿库尼亚只能在一个特征上进行单独分离。
与常见的基于监督树的学习器一样,隔离森林不进行外推分析,这使得它更适合于拟合受污染的数据集进行异常值检测,而不是拟合无异常的数据集用于新颖性检测(在这种情况下,它不会比现有观察更有力地对新的异常值进行评分)。
尽管“隔离森林”开箱即用效果很好,但它未能将大谷昭平列为棒球(可能是所有职业运动)中最大的异常值,这说明了任何异常值检测器的主要局限性:用于拟合它的数据。
需要说明的是,在我们的实验数据中,我们不仅省略了防守数据(对不起,奥斯汀·赫奇斯),也没有考虑投球数据。因为投手们甚至不再尝试击球了……除了Ohtani,他的赛季包括棒球史上第二好的打击率(BAA)和第11好的平均得分(ERA)(至少投了100局),一场完整的比赛被淘汰,以及一场他三振十名击球手并击出两支全垒打的比赛。
有人认为大谷昭平是一个模仿人类的高级外星人,但似乎更有可能有两个模仿同一个人的高级外星人。不幸的是,其中一人刚刚做了肘部手术,2024年不会投球了……但另一人刚刚签署了一份创纪录的10年7亿美元的合同。哈哈,得益于异常值检测,现在我们终于可以明白其中有关的原因了!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Comparing Outlier Detection Methods,作者:John Andrews