近日受邀参加首届《PolarDB 开发者大会》,这也国内数据库厂商越来越重视生态建设的表现,特别是数据库主要的受众-开发者,他们的声音对产品的发展至关重要。在本次会议上,阿里云重磅发布了中国首款自研云原生数据库 PolarDB 的“三层分离”全新版本,基于智能决策实现查询性能10倍提升、节省50%成本。同时面向开发者,阿里云全新推出数据库场景体验馆、训练营等系列新举措,广大开发者可率先免费体验 PolarDB 数据库核心特性及NL2BI等AI新功能。下文是个人对参与本次大会的一点感受。
一、主论坛:像“搭积木”一样简单
1、PolarDB 发展总览
作为国内最早定义的一款“云原生”数据库,PolarDB 发展已历经十五年,从早期基于开源数据库的深度优化,到结合云原生技术并形成独立品牌对外发布,到提供多种版本形成品牌矩阵,再到率先提出 Serverless 化并再次开源。PolarDB 一路走来,见证了国产数据库发展的不平凡之路。现在 PolarDB 正朝着更智能、更经济、更优化、更便捷的方向继续发展。

作为一个品牌族,PolarDB 其实是由多款产品组成,主要分为集中式、分布式两个系列;包括有高度兼容 MySQL 的 PolarDB-M、高度兼容 PostgreSQL 和 Oracle 的 PolarDB-PG及分布式版本 PolarDB-X。用户可以根据自身业务场景、生态兼容要求等进行选择。

此次发布会的一个重要观点,就是希望向开发者表达 PolarDB 的发展理念,并通过一个比喻-搭积木来形象描述。其通过产品四个方面的加强,来达到这一目标。一是云原生化,即加速数据业务上云,通过一种新的资源交付方式简化开发者使用数据库;二是平台化,即通过云平台的一站式功能帮助开发者使用和管理好数据库;三是一体化,即通过多场景打通,优化使用体验可实现如“单体”般的使用效果;四是智能化,即通过产品内置 AI 能力,可让数据库一方面变得更加智能简化管理,一方面提供更友好交互的可能。

2、PolarDB 集中式版本展示
❖ 云原生化
针对云原生化,PolarDB 推出了业内首创的三层分离形态,即对数据库资源层(CPU、MEM、DISK)实现了全部分离,即较以往提供更细粒度的资源管控能力,其带来的优势就是可实现根据不同工作负载搭配不同的资源配置,进而实现最优成本产出比。

在 CPU 方面,PolarDB 实现多角色转化及向上扩展能力,提供了非常灵活的组合使用方式。
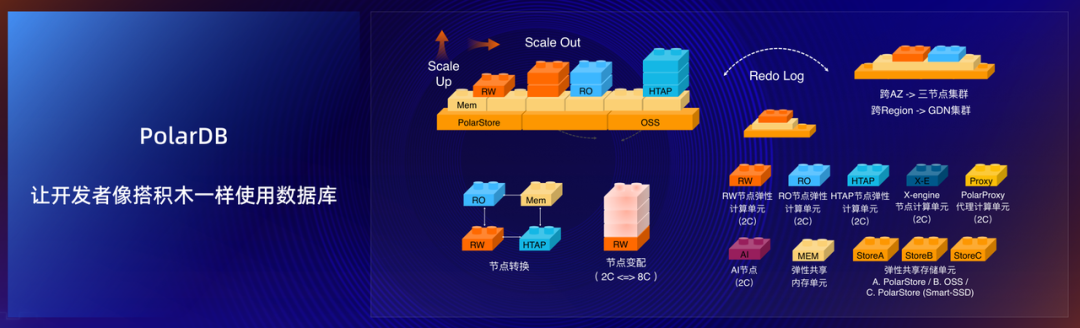
在 MEM 方面,PolarDB 实现了内存全局复制,这样是达到业务更加平滑的效果。能做到这点也是依赖于阿里云多年在底层硬件的优化功力。

在存储方面,PolarDB 内置的分布式存储系统 PolarStore,通过日志优化、RDMA 高速网络等措施实现低成本下的读写延迟优化。

❖ 一体化
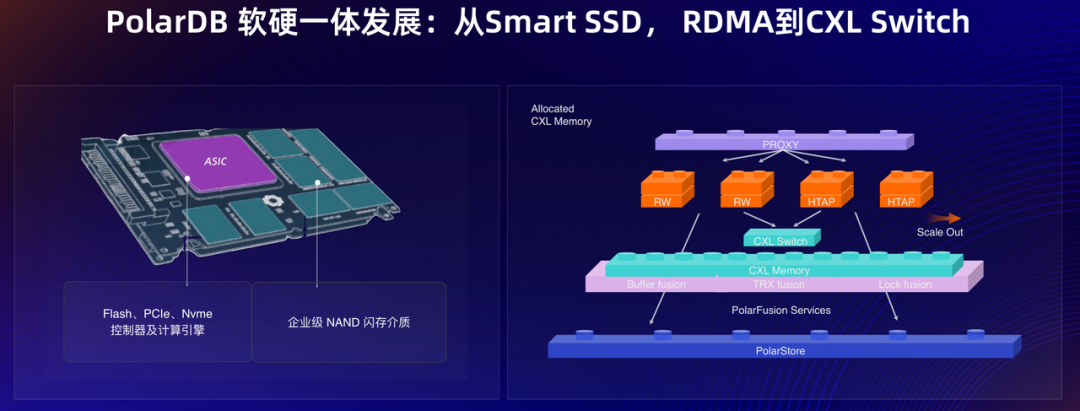
一体化方面,PolarDB 的软硬一体方案,通过在存储、网络、内存等多项硬件领域创新,实现最优费效比。
❖ 平台化
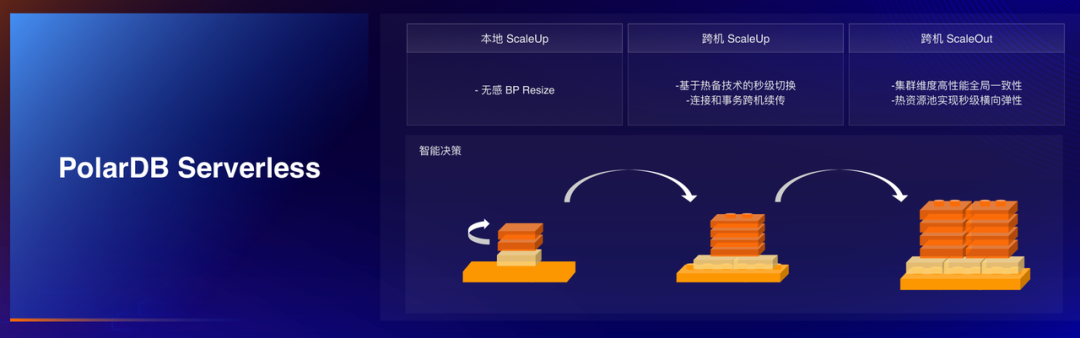
Serverless,作为近年大火的热点,已成为云厂商发力的重点,其对于用户的敏态业务具有非常好的实用价值。PolarDB 通过智能决策系统可实现基于负载感知的向上或向外扩展能力,进而满足用户突发业务压力。结合内核提供的热备、事务重连、全局内存等技术,实现弹性条件下的业务无感。
❖ 智能化
本次大会智能化上还有个小亮点,通过一个小朋友带来的联机互动,演示与数据库通过自然语言交互的使用体验。虽然来略显简单,但其未来发展潜力非常大。其核心正式利用了当今大火的大模型技术。
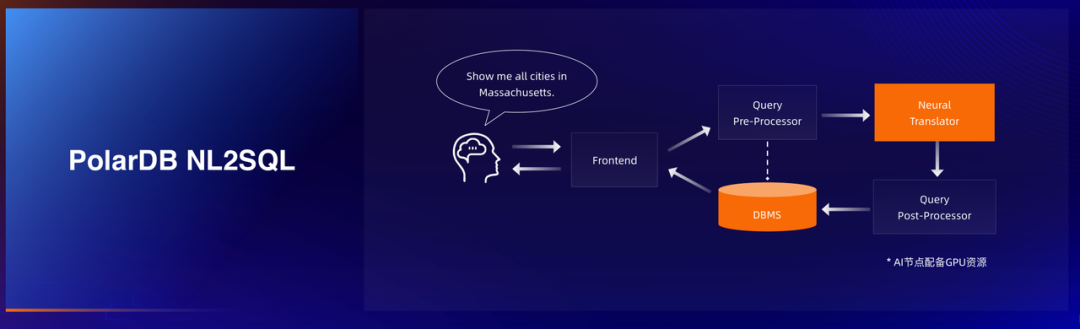
3、PolarDB 分布式版本展示
在谈到 PolarDB 分布式版本之前,会上先提出了使用分布式数据库的三个核心问题:必要性、兼容性和成本。一是必要性,即是否有必要使用分布式数据库。对于中小规模用户而言,分布式数据库还有些遥远,但当面临业务发展时又不得不经历从集中式到分布式的痛苦过程。PolarDB 给出的答案是“单机分布式一体化”,即两种架构一套内核,可实现平滑扩展升级,打消用户使用分布式的担心。
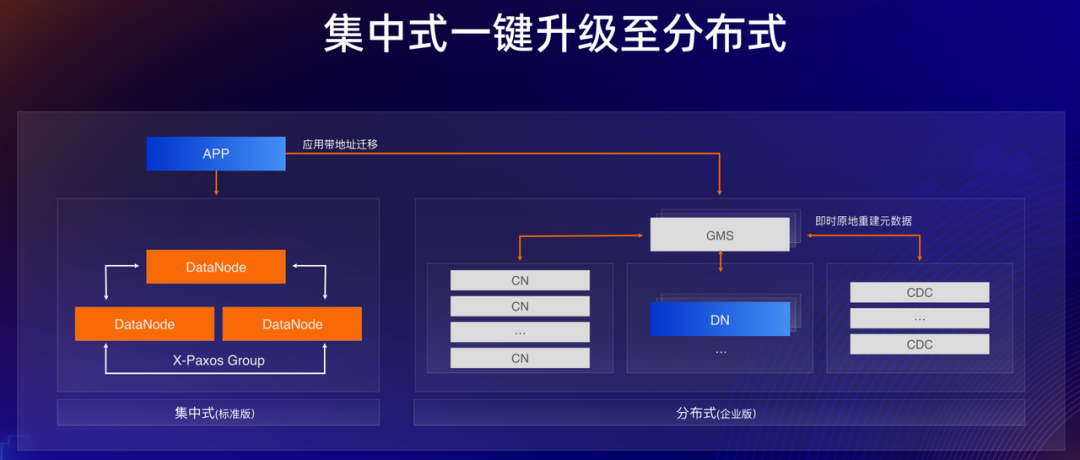
二是兼容性,即使用分布式是否能做到业务无感,这也是阻碍分布式数据库推广的核心问题,很多用户会担心分布式下很多使用难点。PolarDB 给出的答案是“自动分片与扩展资源平衡”,通过灵活分片调整方式打消用户对使用分片的恐惧心理。
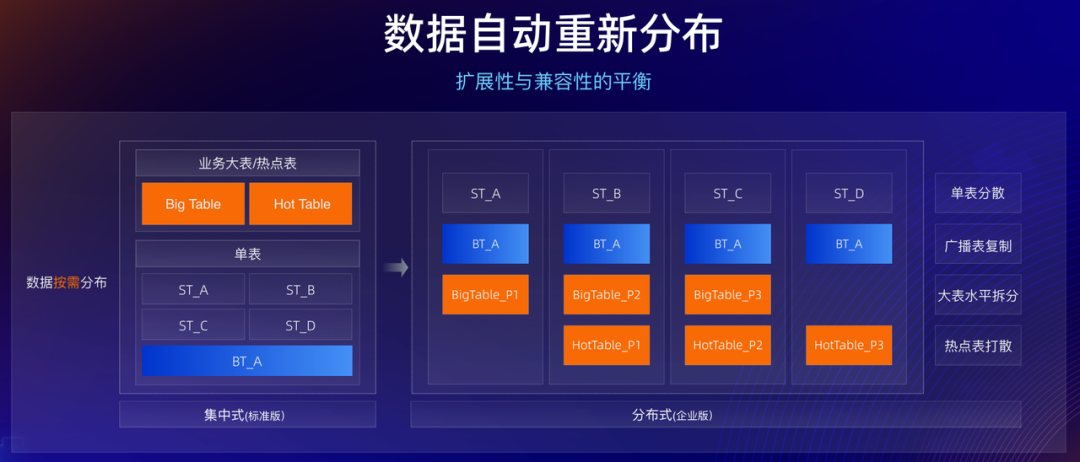
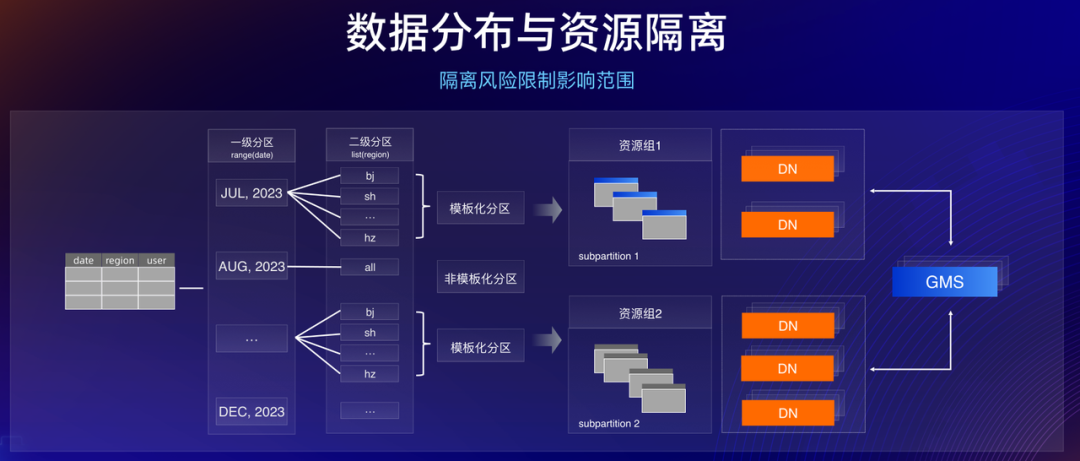
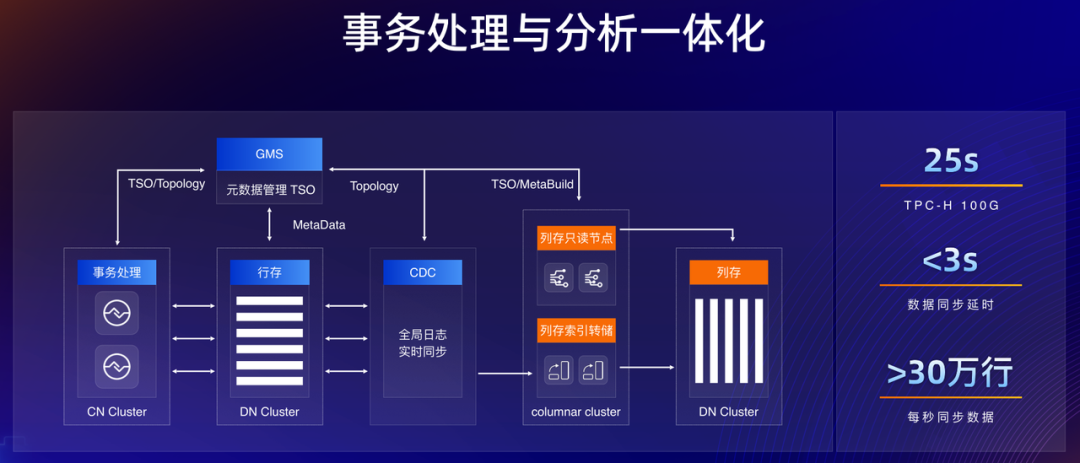
三是成本,即分布式下面临的海量数据管理与多工作负载可能带来的成本提高。PolarDB 给出的答案是“冷热分离与查询事务一体化”来解决。

二、分论坛:开发者需要怎样的数据库
此次大会还分设几个分论坛,就开发者关心的问题进行讨论。个人有幸受邀参与一场分论坛,内容是《面向未来,开发者需要什么样的数据库?》,与几位行业大咖进行了一次思想的碰撞。下面就几个论坛讨论有意思的问题分享下部分观点。

1、在数据库应用和开发中,开发者最常遇到的问题是什么?
- 数据库承担两个职责,一是数据存储,一是数据计算。从开发者角度来看,是希望在业务开发中不再拘泥于底层算力和存储的约束,可以完全依据业务需求进行开发,这也正是 Serverless 技术受到关注的原因。正希望后者提供灵活的存储与算力的扩展能力,而不需要在预定义。
- 长期以来,开发者与数据库的交互方式是以 SQL 为主,这也成为数据交互的统一标准。然而一直以来各数据库厂商纷纷在 SQL 标准上定义了很多方言,这也成为很多开发者面对不同数据库时不得不需要重新学习的问题,成为很多应用迁移库的一大障碍。这也是为什么很多国产数据库做兼容性的主要原因。此外,随着 AI 技术发展,通过自然语言直接与数据库交互,也成为一种可能,现在正有更多的数据库产品开始支持 NL2SQL。
- 数据库不是孤立存在的,在一个企业的数据生态中,存在着数据的上下游生态,存在数据产生、流转、存储、汇聚、分析、展示等多个环境。从开发者角度来看,是希望提供完整的生态支持,以数据库为核心的数据生态可以顺滑的流转起来。
2、云原生+Serverless 将会给开发者带来什么?数据库 Serverless 化⾯临的技术问题和挑战是什么?
- 云原生和 Serverless 作为一种新的资源交付方式,大大简化原有数据库交付难点,也简化了相关管理性工作。开发者可根据需要随时拉起数据库使用,无需考虑底层基础设施。Serverless 技术则可让开发者更专注业务开发,不再关系底层数据库资源消耗、业务负载变化情况,Serverless 的弹性能力可以很好解决上述问题。
- 数据库 Serverless 化是要面临诸多问题:一是多层资源解耦,提供更细粒度的资源调度方式及弹性;二是数据库负载感知及变化能力,能够在极短时间内感知变化并做出相应的资源调整;三是资源隔离和Qos,需要解决 Serverless 中不同用户共用资源下的隔离和质量保障。
3、企业客户/开发者在云数据库使用中存在什么困难?
- 首要问题就是云数据库产品的选择问题,云数据库往往存在很多数据库产品、每类产品下还有很多版本(如标准版、企业版)、每款下还有多种资源规格(如4C8G、8C16G等)。此外,云产品还是涉及到上下游生态,与TP库与AP库的配合、ETL工具的选择、数据展示等等。如此多的选择,让用户存在很大选择性障碍。
- 其次是对云数据库的可用性、一致性、安全性的担忧。之前上述问题都是企业自己解决,上云后需要通过云来保障。
4、预测下未来十年数据库发展的演进方向?
- 更加智能化。这主要是针对数据库管理者而言,通过智能化的管理,简化数据库的管理复杂度。当前以AI技术与数据库结合的一个重要的方向就是AI4DB,例如Oracle最早提出的自动驾驶的概念,正是为了解决管理问题。
- 全新交互方式。这主要是针对开发者而言,一方面在通过SQL实现与数据库的交互外,是否能提供更加友好的交互方式,大模型技术的出现为这方面提供一种可能。NL2SQL的出现将简化交互方式,随着这一技术的发展成熟,未来可能会出现完全颠覆的数据交互方式。
- 普惠标准化。作为企业的管理者来说,是希望数据库能解决普惠的资源供给,即低成本的使用。同时数据库标准化也很重要,可以实现切换的低风险,解决数据库绑定的问题。
- 业务场景化。随着数据在更多企业场景中的应用,如何选择和使用数据库成为业务方关注的问题。如果数据库提供提供场景化的解决方案,让选择不再困难,大大简化从选型、建模、研发成本,对于业务方具有很大意义。