












2024年1月19日,网络安全大模型评测平台SecBenc正式发布,该平台由腾讯朱雀实验室和腾讯安全科恩实验室,联合腾讯混元大模型、清华大学江勇教授/夏树涛教授团队、香港理工大学罗夏朴教授研究团队、上海人工智能实验室OpenCompass团队共同建设,主要解决开源大模型在网络安全应用中安全能力的评估难题,旨在为大模型在安全领域的落地应用选择基座模型提供参考,加速大模型落地进程。同时,通过建设安全大模型评测基准,为安全大模型研发提供公平、公正、客观、全面的评测能力,推动安全大模型建设。
行业首发,弥补大模型在网络安全垂类领域评测空白
自2022年11月ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮,大模型的落地进程也随之加速。然而,在网络安全应用中,大模型研发人员如何选择合适的基座模型,当前大模型的安全能力是否已经达到业务应用需求,都成为亟待解决的问题。
SecBench网络安全大模型评测平台,将重点从能力、语言、领域、安全证书考试四个维度对大模型在网络安全领域的各方面能力进行评估,为大模型研发人员、学术研究者提供高效、公正的基座模型选型工具和研究参考。
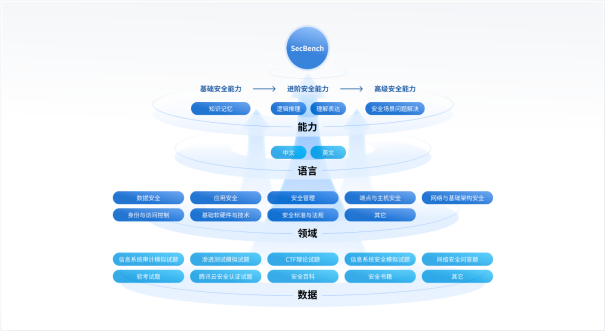
图 1. SecBench网络安全大模型评测整体设计架构
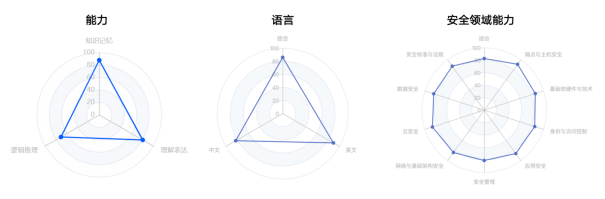
图 2. GPT-4在能力维度、语言维度以及安全领域能力的评估结果
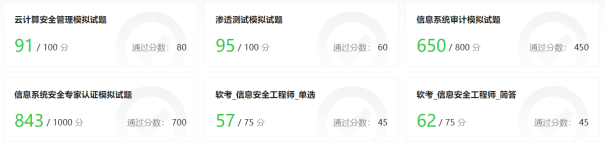
图 3. GPT-4在各类安全证书考试中的评估结果(绿色为通过考试)
SecBench设计架构
图1. 为SecBench网络安全大模型评测初期规划的架构,主要围绕三个维度进行构建:
一是积累行业独有的网络安全评测数据集。评测数据是评测基准建设的基础,也是大模型能力评测最关键的部分。目前行业内还没有专门针对大模型在网络安全垂类领域的评测基准/框架,主要原因也是由于评测收据缺失的问题。因此,构建网络安全大模型评测基准的首要目标是积累行业内独有的网络安全评测数据集,覆盖多语言、多题型、多能力、多领域,以全面地评测大模型安全能力。
二是搭建方便快捷的网络安全大模型评测框架。“百模大战”下,大模型的形态各异,有HuggingFace上不断涌现的开源大模型,有类似GPT-4、腾讯混元、文心一言等大模型API服务,以及自研本地部署的大模型。评测框架如何支持各类大模型的快速接入、快速评测也很关键。此外,评测数据的多样性也挑战着评测框架的灵活性,例如,选择题和问答题往往需要不同的prompt和评估指标,如何快速对比few shot和zero shot的差异。因此,需要搭建方便快捷的网络安全大模型评测框架,以支持不同模型、不同数据、不同评测指标的灵活接入、快速评测。
三是输出全面、清晰的评测结果。网络安全大模型研发的不同阶段其实对评测的需求不同。例如,在研发初期进行基座模型选型阶段,通常只需要了解各类基座模型的能力排名、对比不同模型能力差异;而在网络安全大模型研发阶段,就需要了解每次迭代模型能力的变化,仔细分析评估结果等。因此,网络大模型评测需要输出全面、清晰的评测结果,如评测榜单、能力对比、中间结果等,以支持不同研发阶段的需求。
SecBench除了围绕上述三个目标进行建设外,还设计了两个网络安全特色能力:安全领域评测和安全证书考试评估。安全领域评测从垂类安全视角,评测大模型在九个安全领域的能力;安全证书考试评估支持经典证书考试评估,评测大模型通过安全证书考试的能力。
SecBench评测框架
SecBench网络安全评测框架可以分为数据接入、模型接入、模型评测、结果输出四个部分,通过配置文件配置数据源、评测模型、评估指标,即可快速输出模型评测结果。
- 数据接入:在数据接入上,SecBench支持多类型数据接入,如选择题、判断题、问答题等,同时支持自定义数据接入及评测prompt模板定制化。
- 模型接入:在模型接入上,SecBench同时支持HuggingFace开源模型、大模型API服务、本地部署大模型自由接入,还支持用户自定义模型。
- 模型评测:在模型评测上,SecBench支持多任务并行,加快评测速度。此外,SecBench已内置多个评估指标以支持常规任务结果评估,也支持自定义评估指标满足特殊需求。
- 结果输出:在结果输出上,SecBench不仅可以将评测结果进行前端页面展示,还可以输出模型评测中间结果,如配置文件、输入输出、评测结果文件等,支持网络安全大模型研发人员数据分析需求。
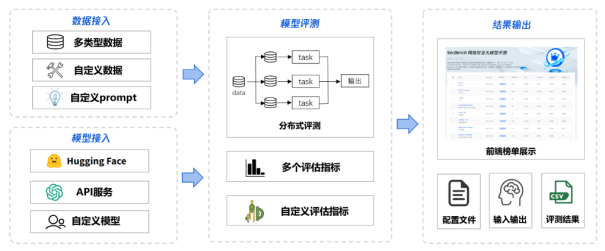
图 4. SecBench网络安全大模型评测框架
SecBench评测数据
网络安全大模型的能力难以评测,主要原因之一还是网络安全垂类数据的缺失。为了解决这一问题,SecBench目前已经收集整理了12个安全评测数据集,累计数据10000余条。
- 语言维度:覆盖中文、英文两类常见语言的评测。
- 能力维度:从安全视角,支持大模型对安全知识的知识记忆能力、逻辑推理能力、理解表达能力的评估。
- 领域维度:支持大模型在不同安全领域能力的评测,包括数据安全、应用安全、端点与主机安全、网络与基础架构安全、身份与访问控制、基础软硬件与技术、安全管理等。
- 证书考试:SecBench还积累了各类安全证书模拟试题,可支持大模型安全证书等级考试评估。
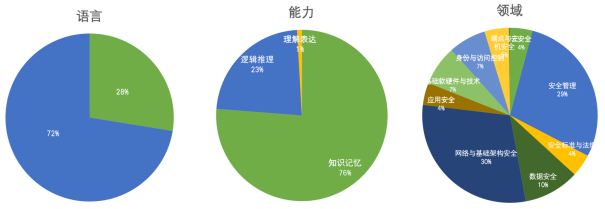
图 5. SecBench网络安全大模型评测数据分布
当前SecBench评测数据仍然存在多样性不足、分布不均匀等问题,当前正在持续补充建设多题型、多能力、多维度的评测数据。
SecBench评测结果
SecBench正在逐步接入大模型进行网络安全能力评测,目前主要针对经典GPT模型以及小规模开源模型进行评测榜单输出。展示模型在能力、语言、安全领域不同能力维度的结果,同时支持安全等级证书考试结果输出。后续将持续接入商用大模型、安全大模型,支持模型能力对比等能力。
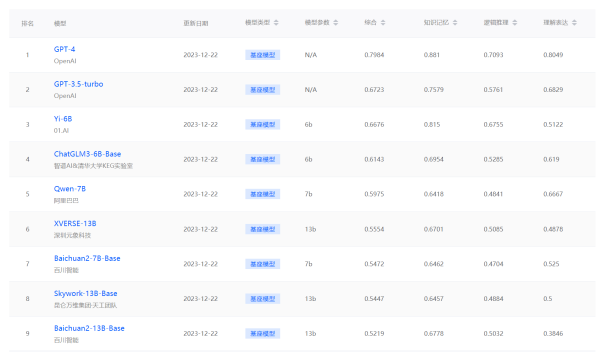
图 6. SecBench网络安全大模型评测榜单
随着大模型在网络安全领域的落地应用加速,网络安全大模型的评测变得尤为关键。SecBecnch已初步建立起围绕网络安全垂类领域的评测能力,以更好地支持网络安全大模型的研发及落地应用。此外为评估大模型在Prompt安全方面的表现,腾讯朱雀实验室已联合清华大学深圳国际研究生院,发布了《大语言模型(LLM) 安全性测评基准》。
未来展望
SecBecnch初步建立起围绕网络安全垂类领域的评测能力,然而还有许多需要优化迭代的地方:一是仍需持续补充构建高质量的网络安全评测数据,覆盖多领域、多题型,以更好地支持模型在网络安全领域的全面评测;二是快速跟进大模型评测,对于新发布的大模型,能够及时输出评测结果;三是丰富模型结果呈现方式,支持模型对比、结果分析等功能,以满足不同用户的使用需求。SecBench也希望能够引入更多的合作伙伴,包括学术界、工业界相关从业者,共创共赢,共同推动网络安全大模型的发展。




















