













译者 | 朱先忠
审校 | 重楼
引言
时空数据来自手机、气候传感器、金融市场交易以及车辆和集装箱中的传感器等多种来源,是规模最大、扩展最快的数据类别。IDC估计,到2025年,联网的物联网设备产生的数据总量将达到73.1 ZB,复合年增长率从2019年的18.3 ZB增长到26%。
根据《麻省理工科技评论》最近的一份报告显示,物联网数据(通常标有位置)的增长速度快于其他结构化和半结构化数据(见下文中的图示)。然而,由于物联网数据的复杂集成和有意义的利用带来的挑战,大多数组织至今在很大程度上仍未开发物联网数据。
当前,两项突破性技术进步的融合将为地理空间和时间序列数据分析领域带来前所未有的效率和可访问性。第一种是GPU加速的数据库,它为时间序列和空间工作负载带来了以前无法达到的性能和精度水平。第二种是生成式人工智能,这一技术有助于消除对同时拥有GIS专业知识和高级编程敏锐性的高端人才的需求。
上述这些发展成就都是开创性的,它们相互交织,使复杂的空间和时间序列分析越来越普及,使越来越广泛的数据专业人员比以往任何时候都能够使用这些技术。在这篇文章中,让我们来探讨这些进步将如何重塑时空数据库的格局,并开创一个数据驱动的见解和创新的新时代。
GPU如何加速时空分析
GPU最初设计用于加速计算机图形和渲染,最近在其他需要大规模并行计算的领域推动了有关创新,这包括为当今最强大的生成式人工智能模型提供动力的神经网络。同样,时空分析的复杂性和范围经常受到计算规模的限制。但是,能够利用GPU加速技术的现代数据库已经突破了新的性能瓶颈,从而推动新的技术见解。在这里,我将重点介绍基于GPU加速的时空分析方面的两个特定领域。
具有不同时间戳的时间序列流的不精确联接
在分析不同的时间序列数据流时,时间戳很少完全对齐。即使设备依赖精确的时钟或GPS(全球卫星定位系统),传感器也可能以不同的间隔生成读数,或提供具有不同延迟的指标。或者,在股票交易和股票报价的情况下,您可能会有交错的时间戳,而这些时间戳并不完全一致。
为了在任何给定时间获得机器数据状态的通用操作画面,您需要加入这些不同的数据集(例如,了解路线上任何点处的车辆的实际传感器值,或将金融交易与最新报价进行对账等)。与客户数据不同,在客户数据中,您可以使用固定的客户ID进行连接;在这里,您需要执行不精确的连接,以根据时间关联不同的数据流。
我们可以利用GPU的处理能力来完成繁重的任务,而不是试图构建复杂的数据工程管道来关联时间序列。例如,借助于Kinetica(一个分布式的、GPU加速的数据库),您可以利用GPU加速的ASOF联接,该联接允许您使用指定的间隔将一个时间序列数据集联接到另一个数据集,以及确定应返回该间隔内的最小值还是最大值。
例如,在下面的场景中,交易和报价以不同的时间间隔到达。
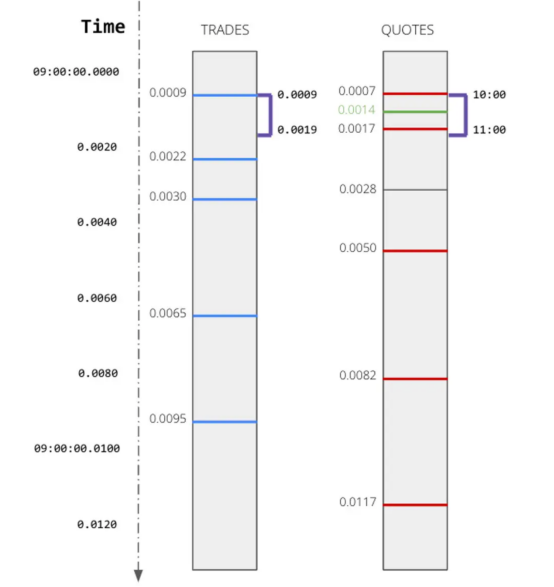
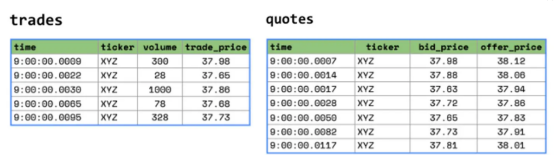
如果我想分析苹果公司的交易及其相应的报价,我可以使用Kinetica的ASOF联接来立即找到在每次苹果交易的特定间隔内发生的相应报价。相应的SQL脚本如下所示:
这里仅使用一行SQL脚本并结合GPU的强大功能,从而取代了时空数据的复杂数据工程管道的实现成本和处理延迟。此查询将在交易后五秒内为每个交易找到最接近该交易的报价。时间序列或空间数据集上的这些类型的不精确连接是帮助治理时空数据泛滥的关键工具。
数十亿点的交互式地理可视化
通常,探索或分析时空物联网数据的第一步是可视化。特别是对于地理空间数据,根据参考地图渲染数据将是对数据进行视觉检查、覆盖率问题检查、数据质量问题或其他异常情况检查的最简单方法。例如,与开发其他算法或流程来验证GPS信号质量相比,视觉扫描地图并确认车辆的GPS轨迹实际上比遵循道路网络的速度要快得多。或者,如果你在几内亚湾的空岛周围看到虚假数据,你可以快速识别和隔离发送0度纬度和0度经度的无效GPS数据源。
然而,使用传统技术大规模分析大型地理空间数据集往往需要妥协。传统的客户端渲染技术通常可以处理数万个点或地理空间特征,然后渲染会出现问题,良好的交互式探索体验根本不可能存在。探索数据的子集,例如在有限的时间窗口或非常有限的地理区域,有可能会将数据量减少到更易于管理的数量级。然而,一旦开始对数据进行采样,就有可能丢弃那些显示特定数据质量问题、趋势或异常的数据,而这些数据本可以通过可视化分析轻松发现。
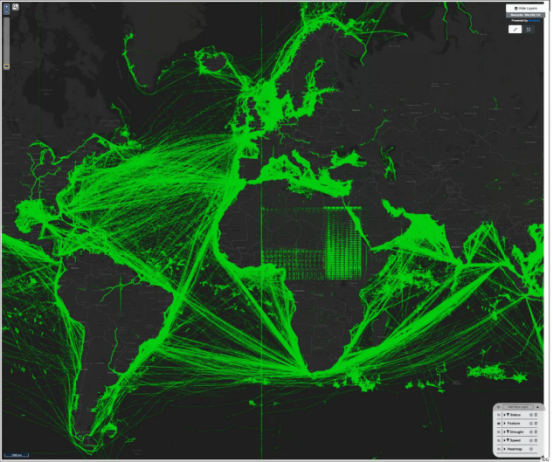
对航运交通中近3亿个数据点的目视检查可以快速发现数据质量问题,例如非洲的异常数据或本初子午线处的波段。
幸运的是,GPU恰好擅长可视化的加速。例如,具有服务器端GPU渲染功能的现代数据库平台,如Kinetica,可以实现数百万甚至数十亿个地理空间点和特征的实时探索和可视化。这种巨大的加速使您能够即时可视化所有地理空间数据,而不会进行下采样、聚合或降低数据保真度。即时渲染在平移和缩放操作时提供非常流畅的可视化体验,从而非常有利于这些数据领域的探索和发现。可以选择性地启用诸如热图或装箱之类的附加聚合,以便对完整的数据语料库执行进一步分析。
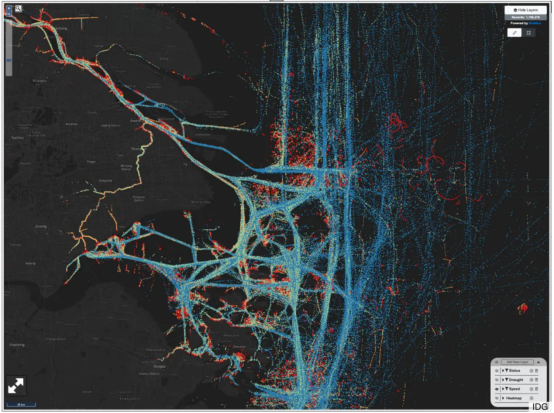
上图中使用放大方法来分析中国东海区域的航运交通模式和船只速度。
用LLM实现时空分析的普及化
时空问题涉及数据中空间和时间之间的关系,通常会引起外行的直觉共鸣,因为它们反映了现实世界的经验。人们可能会想知道一件商品从下单到成功交付的过程。然而,即使对于经验丰富的程序员来说,将这些看似简单的查询转换为函数代码也是一项艰巨的挑战。
例如,在考虑交通状况、道路封闭和送货窗口的同时,为送货卡车确定最大限度地缩短行程时间的最佳路线需要复杂的算法和实时数据集成。同样,考虑到各种影响因素,通过时间和地理信息来追踪疾病的传播,需要复杂的建模和分析,这甚至会让经验丰富的数据科学家都感到困惑。
这些例子强调了时空问题虽然在概念上是可访问的,但往往隐藏着使其编码成为一项艰巨任务的复杂性。即使是经验最丰富的SQL专家,也可能会对理解最佳数学运算以及相应的SQL函数语法提出挑战。
值得庆幸的是,最新一代的大型语言模型(LLM)能够熟练地生成正确高效的代码,包括SQL。经过时空分析细微差别训练的这些模型的微调版本,例如Kinetica的SQL-GPT原生LLM,现在可以为一类全新的用户来解释这些分析领域。
例如,假设我想分析典型的纽约市出租车数据集,并提出与空间和时间有关的问题。首先,我将为LLM提供一些关于我要分析的表的基本上下文。在Kinetica Cloud中,我可以使用UI或基本的SQL命令来定义我的分析上下文,包括对特定表的引用。这些表的列名和定义与LLM共享,但不共享这些表中的任何数据。或者,我可以在上下文中包含其他注释、规则或示例查询结果,以进一步提高SQL的准确性。
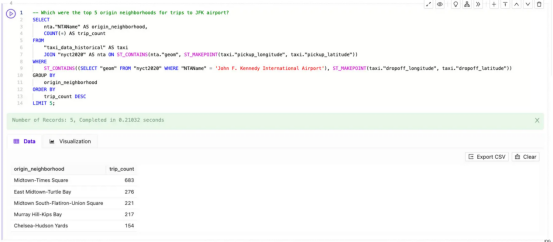
一旦我设置了初始上下文,我就可以在Kinetica Cloud中使用SQL-GPT来询问“Which were the top 5 origin neighborhoods for trips to JFK airport?(前往JFK机场的前5个始发社区是哪些?)”。经过微调的LLM会立即生成以下SQL:
--前往JFK机场的前5个始发社区是哪些?
几秒钟内,经过微调的LLM就帮助我实现了:
- 设置SELECT语句,引用正确的目标表和列,设置JOIN并使用COUNT(*)、GROUP BY、ORDER BY和LIMIT。对于那些不太精通SQL的人来说,即使是基本的查询构造也算是一个巨大的加速器。
- 使用正确的空间函数,如使用ST_MAKEPOINT()从纬度和经度创建点,使用ST_CONTAINS()查找包含指定点的地理区域。通过帮助我选择正确的函数和语法,LLM可以帮助那些新进入该领域的人开始进行空间分析。
- 将真实世界中的参考信息集成到位置和时间。我问过“JFK airport(肯尼迪机场)”,但LLM能够将这个参考翻译成名为“John F. Kennedy International Airport(约翰·F·肯尼迪国际机场)”的规划单元。这又一次节省了时间——太谢谢你了,LLM!
现在,我运行查询来回答我的初始问题:
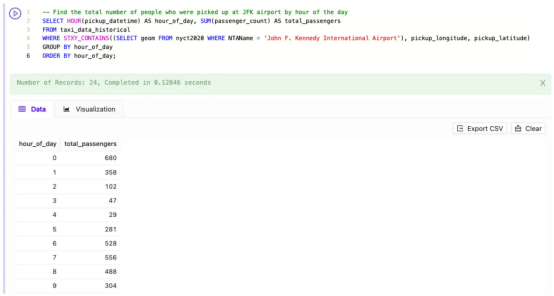
同样,如果我请求Kinetica SQL-GPT帮助我“Find the total number of people who were picked up at JFK airport by hour of the day(查找一天中在肯尼迪机场接载的总人数)”,它会生成以下SQL:
这个查询包含了额外的复杂性,即对每辆出租车的乘客人数进行求和,并按一天中的小时对数据进行统计。但是,LLM处理了这种复杂性,并立即生成了正确的SQL。
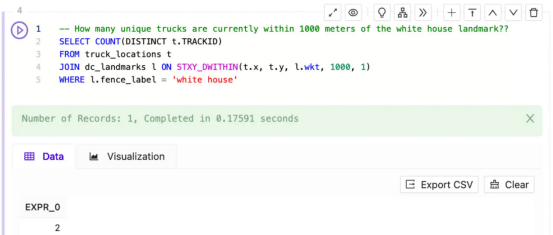
对于更复杂的用户,LLM还可以进行更高级的时空处理。例如,在下一个例子中,我想分析华盛顿特区的一队卡车,我想了解哪些卡车目前靠近一组地理围栏(在这种情况下,是华盛顿特区著名地标周围的缓冲区)。
我可以从一个关于特定地理围栏附近的基本问题开始,比如“How many unique trucks are currently within 1000 meters of the white house landmark?(白宫地标1000米范围内目前有多少辆独特的卡车?)”并使用Kinetica SQL-GPT生成以下SQL:
但是,如果我想不断刷新哪些卡车在我的地理围栏附近的视图,我可以让LLM帮助我创建一个物化视图。
Kinetica SQL-GPT和LLM能够生成SQL来创建和刷新物化视图,并从“在过去5分钟内,哪些卡车到达华盛顿特区地标200米以内?保留所有列并创建一个名为landmark_trucks的物化视图(每10秒刷新一次以存储结果)”这一提示开始:
为了利用不断增长的时空数据量,企业需要对其数据平台进行现代化改造,以处理分析的规模,并提供其业务所依赖的见解和优化。幸运的是,GPU和生成人工智能的最新进展已准备好改变时空分析的世界。
总结
GPU加速的数据库极大地简化了时空数据的大规模处理和探索。随着针对自然语言到SQL进行微调的大型语言模型的最新进展,时空分析技术可以在广大组织中进一步推广应用,这将有助于超越GIS分析师和SQL专家的传统领域。GPU和生成人工智能的快速创新必将使这类应用成为一个令人兴奋的领域。
本文作者Philip Darringer是Kinetica公司(http://www.kinetica.com/)的产品管理副总裁,负责指导公司时间序列和时空工作负载实时分析数据库的开发。他在企业产品管理方面拥有超过15年的经验,专注于数据分析、机器学习和位置情报领域。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Transforming spatiotemporal data analysis with GPUs and generative AI,作者:Philip Darringer






























