












Sam Altman在各种场合都提到,大语言模型的多模态能力,是未来AI技术能够造福人类的最亟待突破的领域。

那么现在在多模态大模型的视觉功能能否达到与语言功能匹配的水平?
当前多模态模型取得的进步很大程度上归功于大语言模型(LLM)的推理能力。但在视觉方面,模型往往只基于实例级别的对比语言-图像预训练(CLIP)。
最近,来自纽约大学和UC伯克利的团队研究表明,多模态大语言模型(MLLM)在视觉处理方面仍存在普遍性的缺陷。
其中,团队成员堪称「豪华」,除了领队谢赛宁外,共同参与还有马毅和LeCun两位大佬。

论文地址:https://arxiv.org/abs/2401.06209
开源项目:https://github.com/tsb0601/MMVP
在一些特殊场景之下,很多MLLM对于图像内容识别能力甚至不如随机瞎猜。

在很多人类能够轻易答对的图像识别问题上,多模态大模型表现却非常挣扎:

GPT-4V:老鹰只有一只眼。

GPT-4V:车门是关着的。

GPT-4V:蝴蝶的脚看不见。

GPT-4V:校车是背向镜头的。

GPT-4V:红心的边框是深色的。
研究人员提出了一种造成这种视觉缺陷最关键的原因:「对比语言-图像预训练盲对(CLIP-blind pairs)」——发现CLIP嵌入中的识别不准确,最主要是来源于那些视觉上不同,但由CLIP模型编码却很相似的图像。

进一步地,研究团队评估了SOTA开源模型(LLaVA-1.5、InstructBLIP、Mini-GPT4)和闭源模型(GPT-4V、Gemini、Bard)在这一类图像中的识别能力。
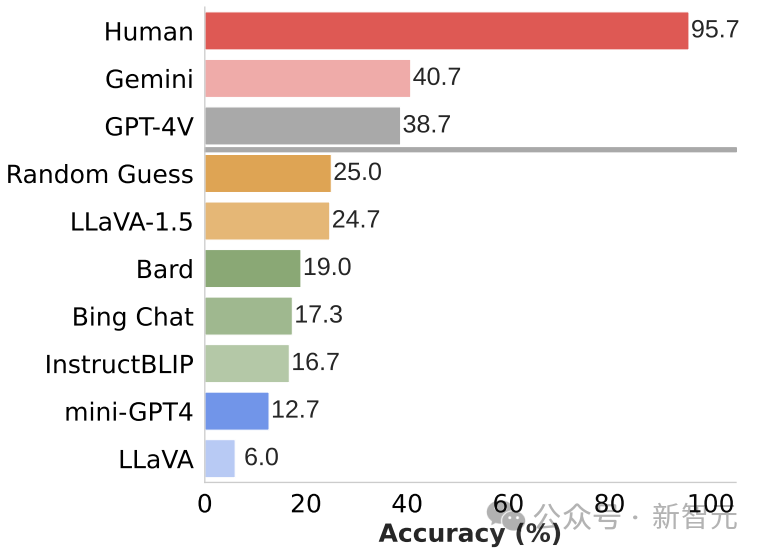
再结合与人类的视觉能力对比,发现多模态LLM和人类视觉能力之间存在显著的性能差距。
除GPT-4V和Gemini之外的模型得分都低于随机猜测水平(25%)。最先进的GPT-4V和Gemini在解决这类基本视觉基础问题上表现也很不理想。
在此基础之上,研究人员尝试解决这个问题。
他们最终提出了「交错特征混合(Interleaved-MoF)」方法来利用CLIP和DINOv2嵌入的优势来增强图像表征。
证明了将视觉自监督学习特征与MLLM集成起来可以显著增强LLM的视觉基础能力。
他们从CLIP和DINOv2中获取经过处理的特征,并在保持其原始空间顺序的同时对它们进行交错混合。
「交错特征混合(Interleaved-MoF)」显著增强了视觉基础能力,在MMVP基准中获得了10.7%的能力增强,同时还不影响模型遵循指令的能力。
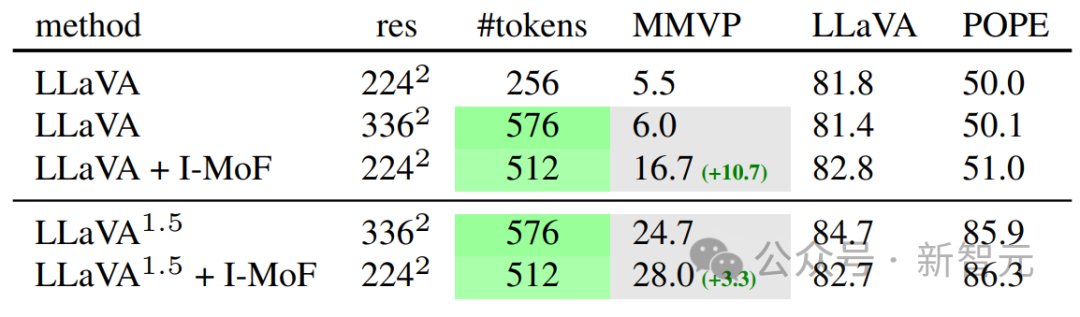
这个实验在LLaVA-1.5设置和各种图像分辨率设置下能够重复,也能获得相似的性能提升。
CLIP模型的视觉模式
具体来说,研究人员辨识出CLIP无法识别的图像对(CLIP-blind pairs)之后,他们梳理了一些系统性的视觉模式,这些模式往往会让CLIP视觉编码器产生误解。
他们参考了MMVP基准测试中的问题和选项。通过这些问题,把图像中难以捉摸的视觉模式转换成了更加清晰、易于归类的基于语言的描述。
研究人员总结出的9种视觉模式如下:
朝向和方向

某个特征是否出现

某种状态和条件

数量的问题

颜色和外观

位置和上下文

结构特征

文字

不同的视角

在此基础之上,研究人员引入了一个新的基准:MMVP-VLM,可以系统地研究CLIP模型是否能很好地处理这些视觉模式。
研究人员将MMVP基准测试中的问题子集提炼成更简单的语言描述,并将它们分类为视觉模式。为了保持每个视觉模式的问题数量平衡,他们会根据需要添加一些问题,以确保每个视觉模式由15个文本-图像对表示。
扩大CLIP规模无助于解决视觉模式问题
随着时间推移,CLIP模型经历了发展和规模扩大。研究人员在一系列不同的CLIP模型上进行了MMVP的评估。
这些模型在大小、训练数据和方法学等方面各有不同。
下表显示,尽管增加网络规模和训练数据对于识别「颜色和外观」以及「状态和条件」这两种视觉模式有所帮助,但其他的视觉模式仍然是对所有基于CLIP的模型的一大挑战。

提高模型处理的图像分辨率后,模型的改善程度十分有限,但当增加模型网络的规模时,可以看到一定程度的性能提升。
多模态大语言模型(MLLM)的缺陷
CLIP的表现不佳与MLLM的视觉缺陷之间有关系吗?
为了探索这一点,研究人员将MMVP中的问题分类为总结的这些视觉模式,并得到了每个MLLM在这些模式上的表现。
当CLIP视觉编码器在特定视觉模式上的表现不佳时,MLLM型通常也会显示出相似的不足。
例如,那些明确采用CLIP视觉编码器的开源模型,比如LLaVA 1.5和InstructBLIP,它们的表现之间有着密切的相关性。
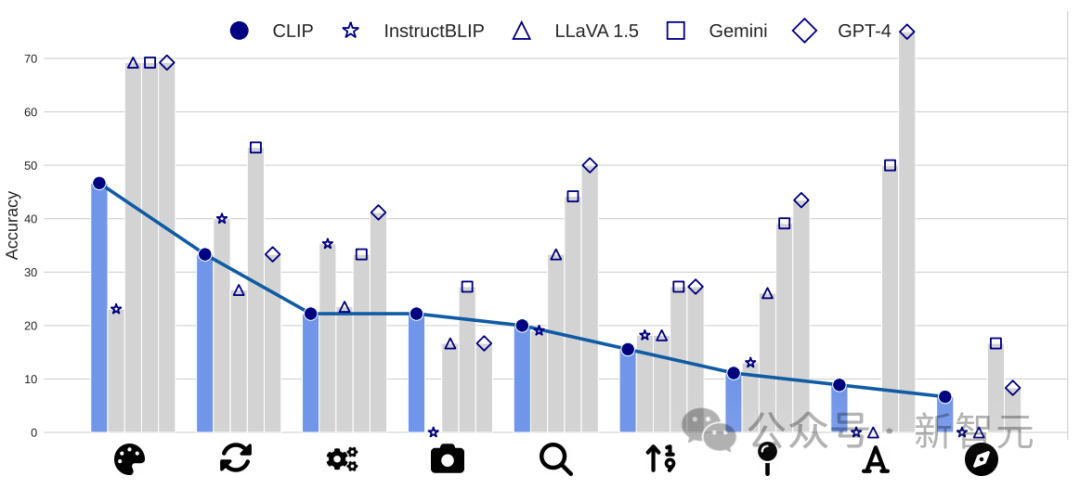
如果CLIP在处理诸如「方向」这类视觉模式时效果欠佳,那么MLLM在同样的视觉模式识别上也同样难以达到预期的性能。
此外,研究人员计算了CLIP模型和MLLM在每种视觉模式上的表现之间的Pearson Correlation。结果入下表显示,LLaVA 1.5和InstructBLIP的系数得分均大于0.7。
这个高分表明CLIP模型中视觉模式识别的弱点与MLLM的表现之间存在很强的相关性。

全新特征混合(MoF)方法
如果开源大语言模型在视觉方面的短板源自CLIP视觉编码器,该如何打造出一个表现更出色的视觉编码器?
为了回答这个问题,他们研究了一种特征混合(MoF)技术,它将专注于视觉的自监督学习(DINOv2)特征与CLIP特征结合在一起。

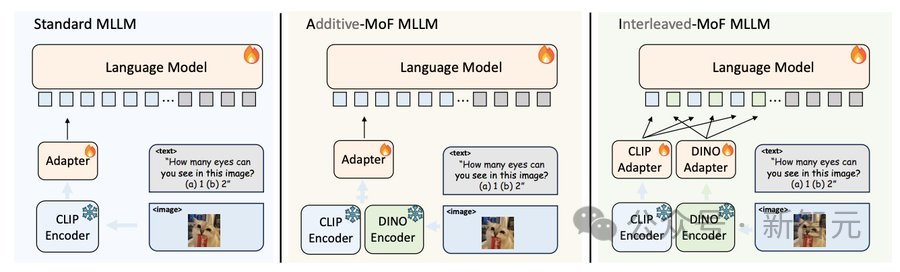
在大语言模型中采用不同的特征混合(MoF)策略。左图:标准的大语言模型采用现成的CLIP预训练视觉编码器;中图:加性特征混合(A-MoF)大语言模型:在适配器前将CLIP和DINOv2特征进行线性混合;右图:交错特征混合(I-MoF MLLM)在适配器后将CLIP视觉Token和DINOv2视觉Token进行空间交错。
只依赖视觉的自监督学习特征:虽提升了视觉识别能力,却削弱了语言处理性能
研究人员将预训练的DINOv2编码器加入到大语言模型中,并与CLIP预训练编码器进行了混合,发现:
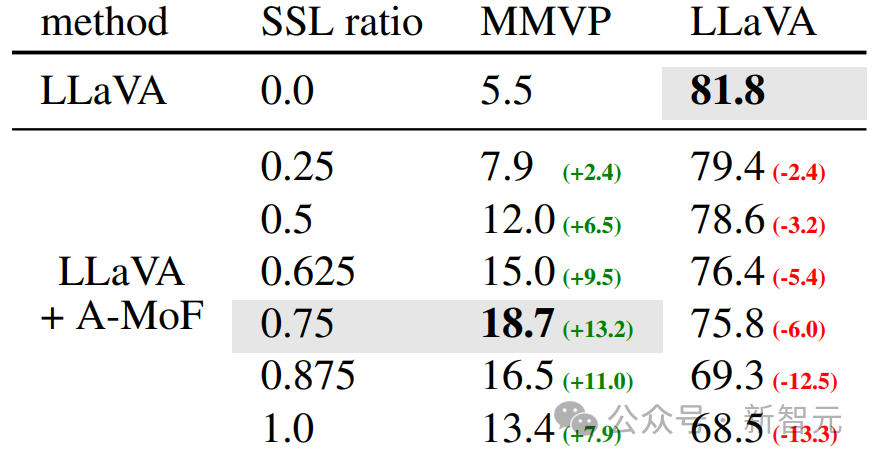
1. 随着DINOv2特征比例的提高,大语言模型在执行指令方面的能力开始下降。特别是当DINOv2特征比例达到87.5%时,能力下降尤为显著。
2. DINOv2特征比例的增加确实提升了模型对视觉信息的理解能力,但当DINOv2比例超过75%后,这一优势开始减弱,并且遵循指令的能力也明显受到了影响。
「交错特征混合(Interleaved-MoF)」:融合CLIP和DINOv2特征,发挥双方优点
最后研究人员提出「交错特征混合(Interleaved-MoF)方法」,通过将CLIP和DINOv2的特征交错排列,同时保持它们的原始空间顺序,以此来整合两者的优势,从而增强图像的表征。
这种交错特征混合显著提升了模型对视觉信息的理解能力,在MMVP测试中获得了10.7%的性能提升,而且模型执行指令的能力并没有受到影响。
这一实验在LLaVA-1.5的配置以及不同图像分辨率的条件下都进行了验证,均得到了类似的性能提升。
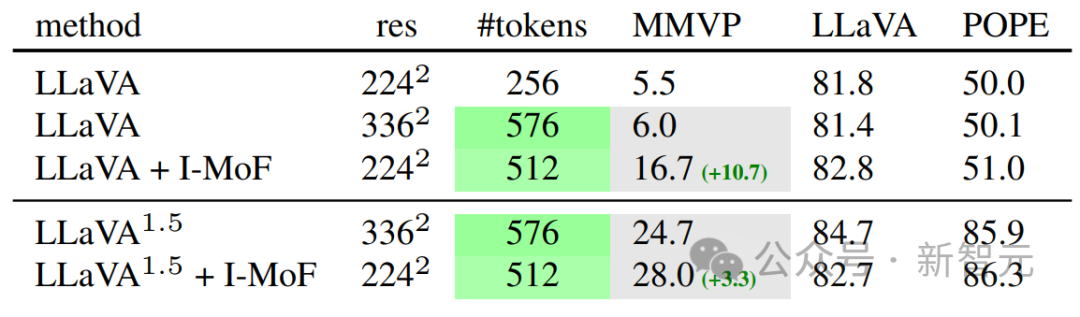
交错特征混合在提升视觉信息理解能力的同时,能够保持模型执行指令能力的稳定。
研究人员还评估了POPE,目的是测试视觉基础中的幻觉。
交错特征混合方法还显示出相对于原始LLaVA模型的持续改进。
仅仅增加图像分辨率以及因此增加的token数量并不能提高视觉基础能力。而交错特征混合改进了视觉基础任务中的表现。
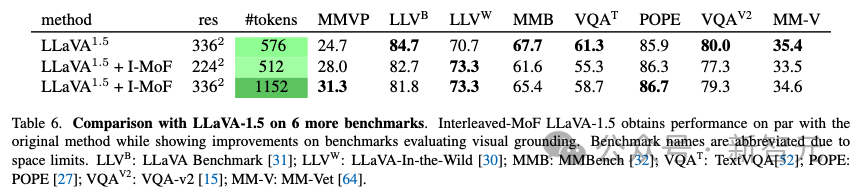
研究人员还在MMBench和GQA等其他基准上评估了交错特征混合方法,发现交错特征混合方法在这些基准上也实现了相似的性能。
作者介绍
Shengbang Tong(童晟邦)

Peter Tong(Shengbang Tong,童晟邦)是NYU Courant CS的一名博士生,导师是Yann LeCun教授和谢赛宁教授。
此前,他在加州大学伯克利分校主修计算机科学、应用数学(荣誉)和统计学(荣誉)。并曾是伯克利人工智能实验室(BAIR)的研究员,导师是马毅教授和Jacob Steinhardt教授。
他的研究兴趣是世界模型、无监督/自监督学习、生成模型和多模态模型。
P.S.马毅教授还特别鸣谢了Meta对研究给予的巨大支持。



























