译者 | 李睿
审校 | 重楼
PostgreSQL拥有丰富的扩展和解决方案生态系统,使开发人员能够将数据库用于通用人工智能应用程序。这一指南将引导他们完成使用PostgreSQL作为矢量数据库构建生成式人工智能应用程序所需的步骤。

首先从Pgvector扩展开始,它使Postgres具有特定于矢量数据库的功能。然后,将回顾在PostgreSQL上运行的人工智能应用程序如何提高性能和可扩展性的方法。最后,将使用一个功能齐全的生成式人工智能应用程序,向那些前往旧金山的旅客推荐Airbnb的住宿房源。
Airbnb推荐服务
示例应用程序是一项住宿推荐服务。想象一下,如果旅客计划去旧金山旅游,并希望住在金门大桥附近的一个靠谱社区。当他们进入Airbnb推荐服务,输入提示,应用程序就会推荐三个最相关的住宿选择。
该应用程序支持两种不同的模式:
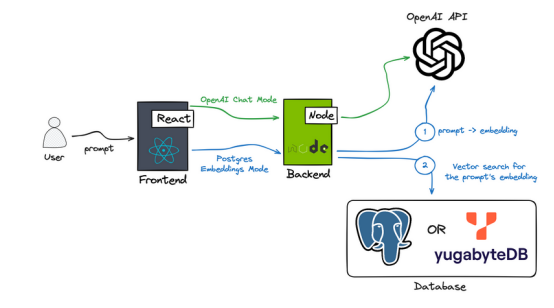
- OpenAI聊天模式:在这一模式下,Node.js后端利用OpenAI聊天通过API和GPT-4模型根据用户的输入生成住宿推荐。虽然这一模式不是本指南的重点,但可以进行尝试。
- Postgres嵌入模式:最初,后端使用OpenAI嵌入API将用户的提示转换为嵌入(文本数据的矢量化表示)。接下来,该应用程序在Postgres或YugabyteDB(分布式PostgreSQL)中进行相似性搜索,以找到与用户提示匹配的Airbnb属性。Postgres利用Pgvector扩展在数据库中进行相似性搜索。本指南将深入研究这个特定模式在应用程序中的实现。
先决条件
- 可访问嵌入模型的OpenAI订阅。
- 最新的Node.js版本
- 最新版本的Docker
使用Pgvector启动PostgreSQL
Pgvector扩展将向量数据库的所有基本功能添加到Postgres中。它允许存储和处理具有数千个维度的向量,计算向量化数据之间的欧几里得和余弦距离,并执行精确和近似的最近邻搜索。
1.在Docker中用Pgvector启动一个Postgres实例:
2.连接到数据库容器并打开一个psql会话:
3.启用Pgvector扩展:
4.确认矢量存在于扩展列表中:SQL
加载Airbnb数据集
该应用程序使用了Airbnb的数据集,该数据集包含旧金山7500多处待租房产。每个列表提供详细的属性描述,包括房间数量、设施类型、位置和其他功能。这些信息非常适合针对用户提示进行相似性搜索。
按照下面的步骤将数据集加载到已启动的Postgres实例中:
1.克隆应用程序存储库:
2.将Airbnb模式文件复制到Postgres容器中(将{app_dir}替换为应用程序目录的完整路径):
3.从下面的Google Drive位置下载包含Airbnb数据的文件。该文件的大小为174MB,包含了使用OpenAI嵌入模型为每个Airbnb属性描述生成的嵌入。
4.将数据集复制到Postgres容器(将{data_file_dir}替换为应用程序目录的完整路径)。
5.创建Airbnb架构并将数据加载到数据库中:
Airbnb的每个嵌入都是一个1536维的浮点数数组。这是Airbnb房产描述的数字/数学表示。
嵌入是用OpenAI的text- embeddings -ada-002模型生成的。如果需要使用不同的模型,那么:
- 更新{app_dir}/backend/embeddings_generator.js和{app_dir}/backend/postgres_embeddings_service.jsfile中的模型
- 通过node embeddings_generator.js命令启动生成器来重新生成嵌入。
查找最相关的Airbnb住宿房源
至此,Postgres已经准备好向用户推荐最相关的Airbnb住宿房源。该应用程序可以通过比较用户的提示嵌入与Airbnb描述的嵌入来获得这些推荐。
首先,启动Airbnb推荐服务的一个实例:
1.使用OpenAI API密钥更新{app_dir}/application.properties.ini:
2.启动Node.js后端:
3.启动React前端:
应用程序用户界面(UI)应在默认浏览器中自动打开。否则,请在地址打开http://localhost:300 。
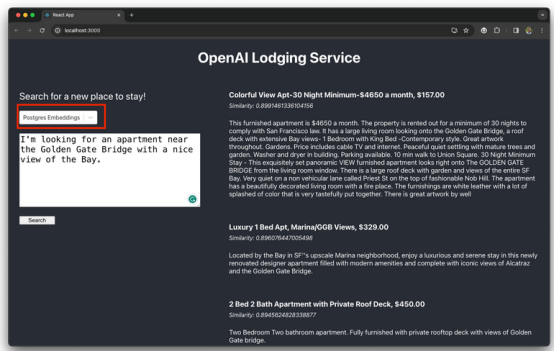
现在,从应用程序用户界面(UI)中选择Postgres Embeddings模式,并要求应用程序推荐一些与以下提示最相关的Airbnb住宿房源:
该服务将推荐三种住宿选择:
在内部,应用程序执行以下步骤来生成推荐(详细信息请参见{app_dir}/backend/postgres_embeddings_service.js):
1.应用程序使用OpenAI Embeddings模型(text- Embeddings -ada-002)生成用户提示的矢量化表示:
2.该应用程序使用生成的向量来检索存储在Postgres中的最相关的Airbnb属性:
相似度计算为存储在description_embedding列中的嵌入与用户提示向量之间的余弦距离。
3.建议的Airbnb属性以JSON格式返回到React前端:
扩展方式
目前,Postgres存储了超过7500处Airbnb住宅房源。通过比较用户提示和Airbnb描述的嵌入,数据库执行精确的最近邻搜索只需要几毫秒的时间。
然而,精确的最近邻搜索(全表扫描)有其局限性。随着数据集的增长,Postgres在多维向量上执行相似性搜索将花费更长的时间。
为了在不断增长的数据量和流量中保持Postgres的性能和可扩展性,可以为向量化数据使用专门的索引和/或使用分布式版本的Postgres水平扩展存储和计算资源。
Pgvector扩展支持多种索引类型,包括性能最好的HNSW索引(Hierarchical Navigable Small World)。该索引对向量化数据执行近似最近邻搜索(ANN),允许数据库即使使用大数据量也能保持低且可预测的延迟。然而,由于搜索是近似的,搜索的召回可能不是100%相关/准确的,因为索引只遍历数据的一个子集。
例如,以下是如何在Postgres中为Airbnb嵌入创建HNSW索引:
要想更深入地了解HNSW指数是如何构建的,以及如何在Airbnb数据上执行人工神经网络搜索,请查看以下视频:
使用分布式PostgreSQL,当单个数据库服务器的容量不再足够时,可以轻松地扩展数据库存储和计算资源。虽然PostgreSQL最初是为单服务器部署而设计的,但它的生态系统包含了一些扩展和解决方案,使它能够在分布式配置中运行。其中一个解决方案是YugabyteDB,它是一个分布式SQL数据库,扩展了Postgres在分布式环境中的功能。
YugabyteDB自2.19.2版本起支持Pgvector扩展。它将数据和嵌入分布在一组节点上,促进了大规模的相似性搜索。因此,如果希望Airbnb服务在Postgres的分布式版本上运行:
1.部署一个多节点YugabyteDB集群。
2.更新{app_dir}/application.properties.ini文件中的数据库连接设置:
3.从头加载数据(或者使用YugabyteDB Voyager从正在运行的Postgres实例中迁移数据)并重新启动应用程序。不需要其他代码级别的更改,因为YugabyteDB与Postgres具有功能和运行时兼容性。
观看以下的视频,了解Airbnb推荐服务如何在分布式Postgres版本上运行:
使用Postgres构建可扩展的人工智能应用程序很有趣,人们可以了解更多关于Postgres作为矢量数据库的知识。
原文标题:PostgreSQL as a Vector Database: Getting Started and Scaling,作者:Denis Magda