













译者 | 朱先忠
审校 | 重楼
简介

随着大型语言模型(LLM)席卷全球,向量搜索引擎也紧随其后。同时,向量数据库也构成大型语言模型长期记忆系统的基础。
通过有效的算法找到相关信息并使其作为上下文传递给语言模型,向量搜索引擎可以提供超出训练截止值的最新信息,并在不进行微调的情况下提高模型输出的质量。这个过程通常被称为检索增强生成(RAG:Retrieval Augmented Generation),它将近似最近邻(ANN:Approximate Nearest Neighbor)搜索这一曾经深奥的算法挑战推向了机器学习领域聚光灯下!
在所有众说纷纭的争议中,人们普遍认为向量搜索引擎与大型语言模型有着密不可分的联系。相关的故事还有很多很多。基于向量搜索技术,已经存在大量强大的应用程序,远远超出改进LLM的检索增强生成这一种技术!
在这篇文章中,我将向您展示向量搜索引擎在数据理解、数据探索、模型可解释性等方面的十个我最喜欢的应用案例。
以下是我们将要介绍的应用程序,按其复杂性大致递增的顺序分别是:
- 图像相似性搜索
- 反向图像搜索
- 对象相似性搜索
- 稳健型OCR文档搜索
- 语义搜索
- 跨模型检索
- 探索感知相似性
- 比较模型表示
- 概念插值
- 概念空间遍历
1.图像相似性搜索
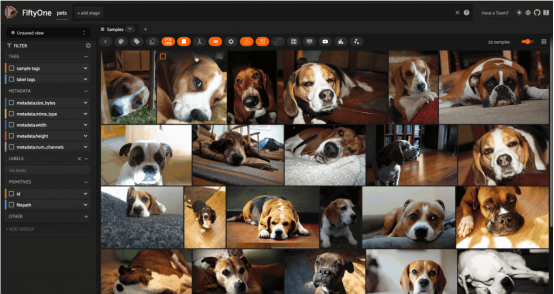
对来自Oxford IIIT宠物数据集(已获许可证)的图像进行图像相似性搜索(图片由作者本人提供)
也许最简单的应用算是图像相似性搜索。在这种应用中,你首先要准备一个由图像组成的数据集——它可以是任何东西,从简单的个人相册到极其复杂的经数千台分布式相机多年来拍摄的数十亿张图像的庞大存储库。
设置准备阶段很简单:首先计算该数据集中每一幅图像的嵌入,并从这些嵌入向量中生成一个对应的向量索引值。在最初的批计算之后,不需要作进一步的推断。探索此数据集结构的一个好方法是从数据集中选择一张图像,然后查询向量索引中的k个最近邻居(最相似的图像)。这种方式可以为查询图像周围的图像空间填充的密度提供一种直观的感觉。
有关图像相似性搜索的更多信息和工作代码,请参阅链接https://docs.voxel51.com/user_guide/brain.html#image-similarity。
2.反向图像搜索
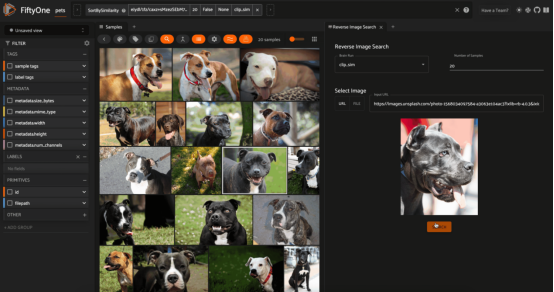
根据牛津IIIT宠物数据集对Unsplash(由Mladen Šćekić提供)网站的图像进行反向图像搜索(图片由作者本人提供)
类似地,图像相似性搜索的一个自然扩展是在数据集中找到与外部图像最相似的图像。这可以是来自本地文件系统的图像,也可以是来自互联网的图像!
要执行反向图像搜索,也要首先为数据集创建向量索引,这与图像相似性搜索示例中介绍的是一样的。二者的区别在于运行时阶段,即计算查询图像的嵌入,然后使用该向量查询向量数据库。
有关反向图像搜索的更多信息和工作代码,请参阅链接:https://github.com/jacobmarks/reverse-image-search-plugin。
3.对象相似性搜索
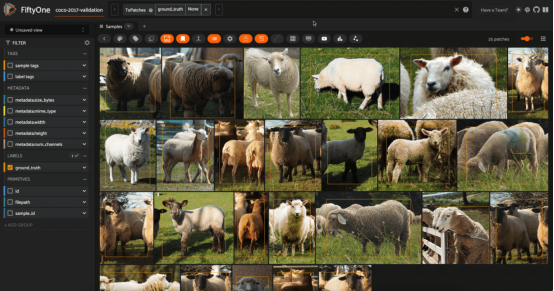
COCO-2017数据集验证分割(经许可)中针对绵羊的对象相似性搜索(图片由作者本人提供)
如果你想更深入地研究图像中的内容,那么对象或“图块”相似性搜索可能就是你想要研究的内容。其中一个这方面的例子是人物重新识别,即您有一张带有感兴趣人物的图像,并且您希望在数据集中找到该人物的所有实例。
人可能只占据每个图像的一小部分,因此他们所处的整个图像的嵌入可能强烈依赖于这些图像中的其他内容——例如,一张图片中可能有多个人。
一个更好的解决方案是将每个对象检测图块视为一个单独的实体,并计算每个对象的嵌入。然后,用这些补图块创建一个向量索引,并对要重新识别的人的图块进行相似性搜索。作为一个这方面的学习起点,您可能首先需要学会使用ResNet模型。
这里有两个微妙之处:
- 在向量索引中,需要存储元数据,将每个补丁映射回数据集中对应的图像。
- 在实例化索引之前,您需要运行一个对象检测模型来生成这些检测图块。您可能还希望只计算某些类对象(如人)的图块嵌入,而不计算其他类对象(椅子、桌子等)。有关对象相似性搜索的更多信息和工作代码,请参阅链接:https://docs.voxel51.com/user_guide/brain.html#object-similarity。
4.稳健型OCR文档搜索
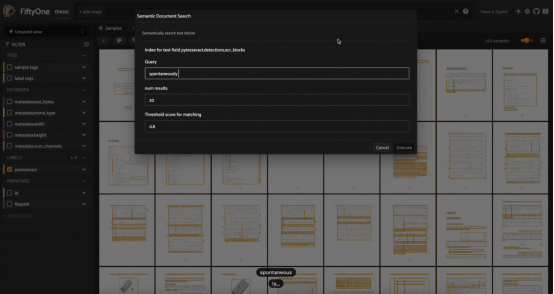
使用我的博士论文中的Tesseract OCR引擎生成的文本块进行模糊/语义搜索,这里使用GTE-base模型进行嵌入计算(图片由作者本人提供)
光学字符识别(OCR)是一种可以将手写笔记、旧期刊文章、医疗记录和藏在壁橱里的情书等文档数字化的技术。像Tesseract和PaddleOCR这样的OCR引擎的工作原理是识别图像中的单个字符和符号,并创建连续的文本“块”——比如段落。
一旦你有了这样的文本,你就可以在预测的文本块上执行传统的自然语言关键字搜索,如链接https://github.com/jacobmarks/keyword-search-plugin处提供的插件源码所实现的那样。然而,这种搜索方法容易出现单字符错误。如果OCR引擎意外地将“l”识别为“1”,则搜索“control”的关键字将失败。
我们可以使用向量搜索来克服这一挑战!使用文本嵌入模型嵌入文本块,如Hugging Face的句子转换器库中的GTE-base模型,并创建一个向量索引。然后,我们可以通过嵌入搜索文本和查询索引,在数字化文档中执行模糊和/或语义搜索。从宏观角度上看,这些文档中的文本块类似于对象相似性搜索中的对象检测补丁!
有关稳健型OCR文档搜索应用的更多信息和工作代码,请参阅链接:https://github.com/jacobmarks/semantic-document-search-plugin。
5.语义搜索

在COCO 2017验证拆分集合中使用自然语言进行语义图像搜索(图片由作者本人提供)
通过多模态模型,我们可以将语义搜索的概念从文本扩展到图像。像CLIP、OpenCLIP和MetaCLIP这样的模型被训练来找到图像及其字幕的常见表示,因此狗的图像的嵌入向量将与文本提示“a photo of a dog(狗的照片)”的嵌入向量非常相似。
这意味着,明智的做法是(即“允许”我们)从数据集中图像的CLIP嵌入中创建一个向量索引,然后对该向量数据库运行向量搜索查询,其中查询向量是文本提示的CLIP嵌入式。
值得注意的是,通过将视频中的各个帧视为图像,并将每个帧的嵌入添加到向量索引中,您还可以实现在视频中进行语义搜索!
有关语义搜索算法的更多信息和工作代码,请参阅链接:https://docs.voxel51.com/user_guide/brain.html#text-similarity。
6.跨模型检索
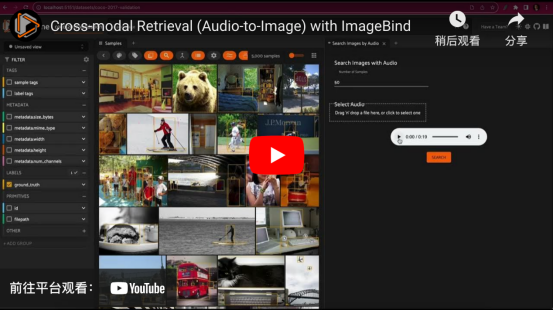
与一列火车中的输入音频文件匹配的图像跨模型检索。这是使用ImageBind和Qdrant向量索引在COCO 2017验证拆分集上实现的(视频由作者本人提供)
从某种意义上说,在图像数据集中进行语义搜索是一种跨模型检索形式。从概念角度来解释这种算法的话,我们检索与文本查询相对应的图像。有了像ImageBind这样的模型工具,我们就可以更深入地研究这方面的应用!
ImageBind将来自六种不同模态的数据(图像、文本、音频、深度、热和惯性测量单元)嵌入同一嵌入空间。这意味着,我们可以为这些模态中的任何一种生成向量索引,并使用这些模态中任何其他模态的样本查询该索引。例如,我们可以拍摄一个汽车鸣喇叭的音频片段,并检索所有汽车的图像!
有关跨模型检索的更多信息和工作代码,请参阅链接:https://github.com/jacobmarks/audio-retrieval-plugin。
7.探索感知相似性
向量搜索故事的一个非常重要的部分是模型,到目前为止我们基本上没有作相关性介绍。其实,我们的向量索引中的元素是来自模型的嵌入。这些嵌入可以是定制嵌入模型的最终输出,也可以是在另一个任务(如分类)上训练的模型的隐藏或潜在表示。
无论如何,我们用来嵌入样本的模型可能会对验证哪些样本与其他样本最相似产生重大影响。对于CLIP模型来说,它能够捕获语义概念,但难以表示图像中的结构信息。另一方面,ResNet模型非常善于表示结构和布局的相似性,能够在像素和图像切片的级别上进行操作。然后是像DreamSim这样的嵌入模型,该模型的目的是弥合差距并捕捉中等水平的相似性——将模型的相似性概念与人类感知的内容相一致。
最后,我们重点介绍一下向量搜索。这种搜索技术为我们提供了一种探索模型如何“看到”世界的方法。可以说,通过为我们感兴趣的每个模型(在相同的数据上)创建一个单独的向量索引,我们就可以快速找到不同模型如何在内部表示数据的直觉结论。
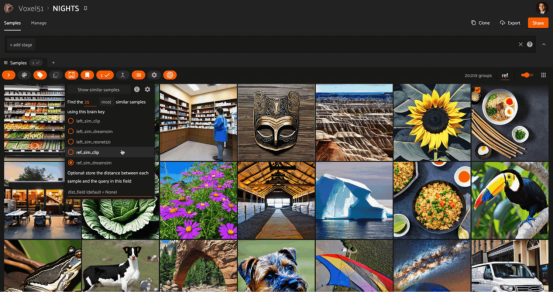
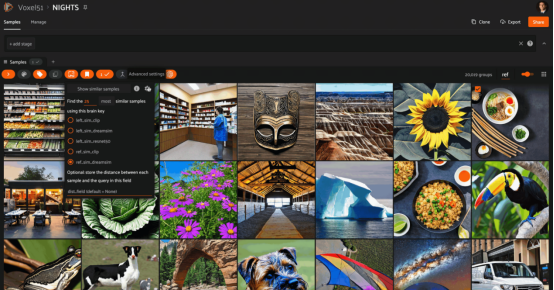
以下是一个示例,展示了在NIGHTS数据集上使用CLIP、ResNet和DreamSim模型嵌入的相同查询图像的相似性搜索结果:
在NIGHTS数据集中的图像上嵌入ResNet50的相似性搜索(使用Stable Diffusion生成的图像)其中,ResNet模型在像素和图块级别上运行;因此,检索到的图像在结构上与查询相似,但并不总是在语义上相似
在同一查询图像上嵌入CLIP的相似性搜索。CLIP模型尊重图像的底层语义,但不尊重它们的布局
在同一查询图像上嵌入DreamSim的相似性搜索结果。DreamSim弥合了这一差距,在语义和结构特征之间寻求最佳的中级相似性折衷
有关探索感知相似性的更多信息和工作代码,请参阅链接:https://medium.com/voxel51/teaching-androids-to-dream-of-sheep-18d72f44f2b。
8.比较模型表示
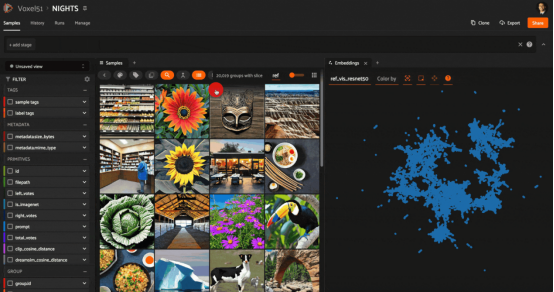
NIGHTS数据集的ResNet50和CLIP模型表示的启发式比较。ResNet嵌入已经使用UMAP(统一流形逼近与投影)方法减少到2D。在嵌入图中选择一个点并突出显示附近的样本,我们可以看到ResNet是如何捕捉构图和调色板的相似性而不是语义的相似性的。在具有CLIP嵌入的所选样本上运行向量搜索,我们可以看到,根据CLIP的大多数样本没有被ResNet搜索到。
通过将向量搜索和统一流形逼近与投影(UMAP:https://umap-learn.readthedocs.io/en/latest/)等降维技术相结合,我们可以对两个模型之间的差异有新的了解。方法如下:
每个模型的嵌入中都包含有关模型如何表示数据的信息。借助于UMAP(或t-SNE或PCA)技术,我们可以从原始模型(model1)生成嵌入的低维(2D或3D)表示。通过这样做,我们牺牲了一些细节,但希望保留一些关于哪些样本被认为与其他样本相似的信息。另一方面,我们获得的是将这些数据可视化的能力。
以原始模型(model1)的嵌入可视化为背景,我们可以在该图中选择一个点,并针对模型2(model2)的嵌入对该样本执行向量搜索查询。然后,我们就可以看到在2D可视化中检索到的点所在的位置!
前面的示例使用的是与上一节中相同的NIGHTS数据集,对ResNet嵌入可视化,结果可以捕获更多的组成方面和结构方面的相似性信息,并使用CLIP(语义方面)嵌入执行相似性搜索。
9.概念插值
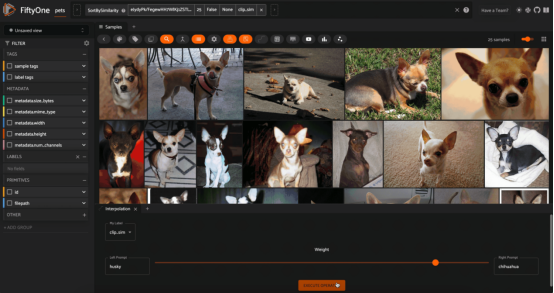
在Oxford IIIT宠物数据集上使用CLIP嵌入的“哈士奇(husky)”和“吉娃娃(chihuahua)”概念之间的插值
现在差不多到了本文的末尾,但幸运的是,我把一些最好的内容留到了最后。到目前为止,我们处理过的向量只有嵌入——向量索引是用嵌入填充的,查询向量也是嵌入的。但有时在嵌入空间中还有额外的结构,我们可以利用它来更动态地与数据交互。
这种动态交互的一个例子是我喜欢的“概念插值”。它的工作原理如下:首先获取图像数据集,然后使用多模态模型(文本和图像)生成向量索引。例如,选择两个文本提示,如“sunny”和“raining”,它们代表概念,并将值alpha设置在[0,1]范围内。我们可以为每个文本概念生成嵌入向量,并将这些向量添加到alpha指定的线性组合中。然后,我们对向量进行归一化,并将其用作对图像嵌入的向量索引的查询。
因为我们在两个文本提示(概念)的嵌入向量之间进行线性插值,所以我们在概念本身之间进行非常松散的插值!我们可以动态地更改alpha,并在每次交互时查询我们的向量数据库。
注意,这种概念插值的概念是实验性的(记住:这并不总是一个定义良好的操作)。我发现,当文本提示在概念上相关,并且数据集足够多样化,而且在插值谱系的不同位置有不同的结果时,它的效果最好。
有关概念插值的更多信息和工作代码,请参阅链接:https://github.com/jacobmarks/concept-interpolation。
10.概念空间遍历
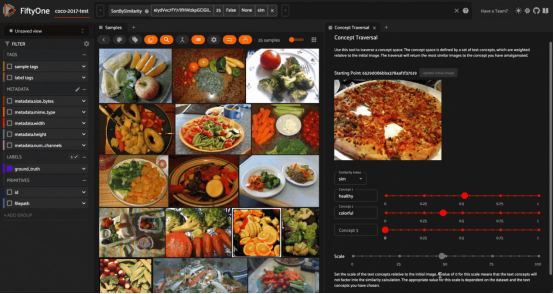
通过嵌入在各种文本提示的方向上移动来遍历“概念”的空间,这里给出的是在COCO 2017数据集的测试拆分子集上展示的结果。这里使用的是嵌入CLIP模型的图像和文本(图片由作者本人提供)
最后,还有很重要的一种应用是我喜欢的“概念空间遍历”。与概念插值一样,这种应用从图像数据集开始,使用CLIP等多模态模型生成嵌入。然后,从数据集中选择一个图像。这个图像将作为你的起点,从这里你可以“穿越”概念的空间。
此后,您可以通过提供一个文本字符串作为概念的替代,来定义您想要移动的方向。设置要在该方向上执行的“步长”的大小,该文本字符串的嵌入向量(具有乘法系数)将添加到初始图像的嵌入向量中。“目的地(destination)”向量将用于查询向量数据库。您可以添加任意数量的多个概念,并实时观察检索到的图像集的更新。
与“概念插值”一样,概念空间遍历并不总是一个严格定义的过程。然而,我发现它很吸引人,并且当应用于文本嵌入的系数足够高时,足以将此系数充分考虑在内时,这种方法的表现还是相当好。
有关概念空间遍历的更多信息和工作代码,请参阅链接:https://github.com/jacobmarks/concept-space-traversal-plugin。
结论
向量搜索引擎是非常强大的工具。它们当之无愧可算是机器学习在检索增强生成领域的“明星”。但其实,向量数据库的用途远不止于此。向量数据库能够帮助我们更深入地理解数据,深入了解模型如何表示数据,并为我们与数据交互提供新的途径。
注意,向量数据库未必只关联到大型语言模型领域。事实证明,无论何时涉及嵌入,它们都是有用的,并且嵌入正好位于模型和数据的交叉点。我们对嵌入空间的结构理解得越严格,我们支持向量搜索的数据和模型交互就越动态和具有普遍性。
如果你觉得这篇文章很有趣,你可能还想看看这些向量搜索的相关帖子:
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:From RAGs to Riches,作者:Jacob Marks, Ph.D.






















