













Text-to-image(T2I)扩散模型在生成高清晰度图像方面显示出了卓越的能力,这一成就得益于其在大规模图像-文本对上的预训练。
这引发了一个自然的问题:扩散模型是否可以用于解决视觉感知任务?
近期,来自字节跳动和复旦大学的技术团队提出了一种简单而有效的方案:利用扩散模型处理视觉感知任务。

论文地址:https://arxiv.org/abs/2312.14733
开源项目:https://github.com/fudan-zvg/meta-prompts
团队的关键洞察是引入可学习的元提示(meta prompts)到预训练的扩散模型中,以提取适合特定感知任务的特征。
技术介绍
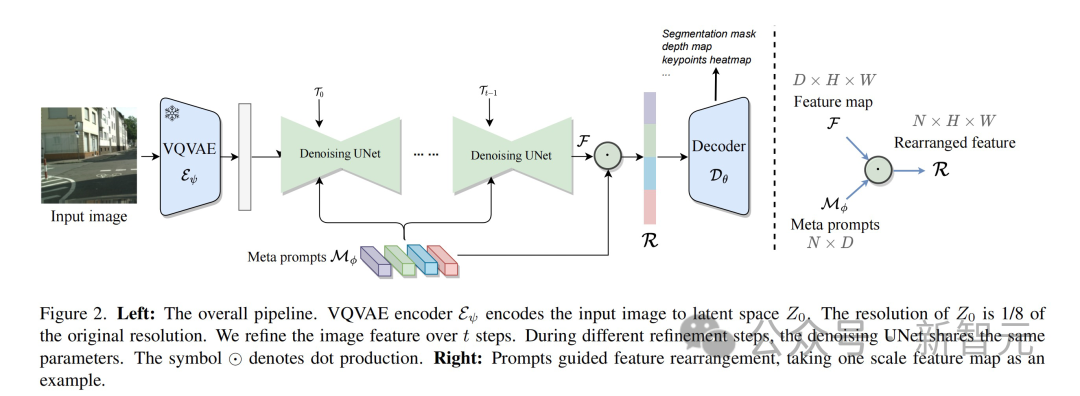
团队将text-to-image扩散模型作为特征提取器应用于视觉感知任务中。
输入图像首先通过VQVAE编码器进行图像压缩。这一步将图像分辨率降低到原始大小的1/8,产生latent space中的特征表示,即。值得注意的是,VQVAE编码器的参数是固定的,不参与后续训练。
接下来,保持未添加噪声的被送入到UNet进行特征提取。为了更好地适应不同任务,UNet同时接收调制的timestep embeddings和多个meta prompts,产生与形状一致的特征。
在整个过程中,为了增强特征表达,该方法进行了步的recurrent refinement。这使得UNet内不同层的特征能够更好地交互融合。在第次循环中,UNet的参数由特定的可学习的时间调制特征调节。
最终,UNet生成的多尺度特征输入到专门为目标视觉任务设计的解码器中。
可学习的元提示(meta prompts)设计
Stable diffusion model采用UNet架构,通过交叉注意力将文本提示融入图像特征中,实现了文生图。这种整合确保了图像生成在语境和语义上的准确性。
然而,视觉感知任务的多样性超出了这一范畴,因为图像理解面临着不同的挑战,往往缺乏文本信息作为指导,使得以文本驱动的方法有时显得不切实际。
为应对这一挑战,技术团队的方法采用了更为多样的策略——不依赖外部文本提示,而是设计了一种内部的可学习元提示,称为meta prompts,这些meta prompts被集成到扩散模型中,以适应感知任务。

Meta prompts以矩阵 的形式表示,其中表示meta prompts的数量,表示维度。具备meta prompts的感知扩散模型避免了对外部文本提示的需求,如数据集类别标签或图像标题,也无需预训练的文本编码器来生成最终的文本提示。
Meta prompts可以根据目标任务和数据集进行端到端的训练,从而为去噪UNet建立特别定制的适应条件。这些meta prompts包含丰富的、适应于特定任务的语义信息。比如:
- 在语义分割任务中,meta prompts有效地展示了对类别的识别能力,相同的meta prompts倾向于激活同一类别的特征。

- 在深度估计任务中,meta prompts表现出对深度的感知能力,激活值随深度变化,使prompts能够集中关注一致距离的物体。

- 在姿态估计中,meta prompts展现出一套不同的能力,特别是关键点的感知,这有助于人体姿态检测。

这些定性结果共同突显了技术团队提出的meta prompts在各种任务中对任务相关激活能力的有效性。
作为文本提示的替代品,meta prompts很好地填补了了text-to-image扩散模型与视觉感知任务之间的沟壑。
基于元提示的特征重组
扩散模型通过其固有的设计,在去噪UNet中生成多尺度特征,这些特征在接近输出层时聚焦于更细致、低级的细节信息。
虽然这种低级细节对于强调纹理和细粒度的任务来说足够,但视觉感知任务通常需要理解既包括低级细节的又包括高级语义解释的内容。
因此,不仅需要生成丰富的特征,确定这些多尺度特征的哪种组合方式可以为当前任务提供最佳表征也非常重要。
这就是meta prompts的作用所在——
这些prompts在训练过程中保存了与所使用数据集特定相关的上下文知识。这种上下文知识使meta prompts能够充当特征重组的过滤器,引导特征选取过程,从UNet产生的众多特征中筛选出与任务最相关的特征。
团队使用点积的方式将UNet的多尺度特征的丰富性与meta prompts的任务适应性结合起来。
考虑多尺度特征,其中每个。和表示特征图的高度和宽度。Meta prompts 。每个尺度上重排的特征的计算为:
最后,这些经过meta prompts过滤的特征随后输入到特定任务的解码器中。
基于可学习的时间调制特征的recurrent refinement
在扩散模型中,添加噪声然后多步去噪的迭代过程构成了图像生成的框架。
受此机制的启发,技术团队为视觉感知任务设计了一个简单的recurrent refinement过程——没有向输出特征中添加噪声,而是直接将UNet的输出特征循环输入到UNet中。
同时为了解决随着模型通过循环,输入特征的分布会发生变化但UNet的参数保持不变的不一致的问题,技术团队对于每个循环引入了可学习的独特的timestep embeddings,以调制UNet的参数。
这确保了网络对于不同步骤中输入特征的变化性保持适应性和响应性,优化了特征提取过程,并增强了模型在视觉识别任务中的性能。
结果显示,该方法在多个感知任务数据集上都取得了最优。




应用落地和展望
该文章提出的方法和技术有广泛的应用前景,可以在多个领域内推动技术的发展和创新:
- 视觉感知任务的改进:该研究能够提升各种视觉感知任务的性能,如图像分割、深度估计和姿态估计。这些改进可应用于自动驾驶、医学影像分析、机器人视觉系统等领域。
- 增强的计算机视觉模型:所提出的技术可以使计算机视觉模型在处理复杂场景时更加准确和高效,特别是在缺乏明确文本描述的情况下。这对于图像内容理解等应用尤为重要。
- 跨领域应用:该研究的方法和发现可以激励跨领域的研究和应用,比如在艺术创作、虚拟现实、增强现实中,用于提高图像和视频的质量和互动性。
- 长期展望:随着技术的进步,这些方法可能会进一步完善,带来更先进的图像生成和内容理解技术。
团队介绍
智能创作团队是字节跳动AI&多媒体技术中台,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法-工程系统-产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。
目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中,欢迎点击「阅读原文」查看。



























