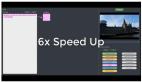
Magnific 图像超分 & 增强工具还正在火热体验中,它强大的图像升频与再创能力收获一致好评。现在,视频领域也有了自己的 Magnific。
拍摄的街道视频一片模糊,仿佛高度近视没戴眼镜一样:

与之相比,下面的视频清晰度高了很多:

视频画面两边形成鲜明的对比:左边视频已经模糊的看不清人脸,而右边视频建筑物的纹理也看得清清楚楚:

行驶的汽车仿佛从一个模糊的世界穿越到高清世界:

不同的方法进行比较,明显看到右下角的视频在微小的细节恢复方面更加清晰:

通过上述展示,我们可以看出,视频超分辨率(VSR)就像是给模糊的老电影穿上了高清新衣。比如上面展示的一段道路监控录像,由于画质太低,细节看起来像是被涂抹过一样。这时候就需要 VSR 技术出场了,它能够把这些低分辨率的视频变得更加清晰。
不过,这个过程并不简单。常常因为摄像机晃动或拍摄物体的移动,视频就像是被风吹过的湖面,波纹模糊。这时,我们不仅需要提升视频的清晰度,还得「摆平」这些模糊的干扰。这就需要视频超分辨率和去模糊的联合修复(VSRDB),它要在保持视频清晰度的同时,还得处理模糊,确保最后呈现出来的视频既清晰又流畅。
为了实现上述效果,来自韩国科学技术院(KAIST)与中央大学的研究者们提出了 FMA-Net 框架。这个框架基于流引导的动态滤波(Flow-Guided Dynamic Filtering, FGDF)和迭代特征细化的多重注意力机制(Iterative Feature Refinement with Multi-Attention, FRMA),旨在实现从小到大的运动表示学习,并具有良好的联合恢复性能(见图 1)。FGDF 的关键之处在于执行滤波时要注意运动轨迹,而不是拘泥于固定位置,这样就能用较小的核有效处理较大的运动。

- 论文地址:https://arxiv.org/abs/2401.03707
- 项目主页:http://kaist-viclab.github.io/fmanet-site/
- 论文标题:FMA-Net: Flow-Guided Dynamic Filtering and Iterative Feature Refinement with Multi-Attention for Joint Video Super-Resolution and Deblurring
方法介绍
该研究的目标是同时实现视频超分辨率和去模糊(VSRDB)。对于一个模糊的 LR(低分辨率, low-resolution )输入序列 ,式中 T = 2N + 1、c 分别表示输入帧数和中心帧索引。VSRDB 的目标是预测一个清晰的 HR( 高分辨率,high-resolution )中心框架
,式中 T = 2N + 1、c 分别表示输入帧数和中心帧索引。VSRDB 的目标是预测一个清晰的 HR( 高分辨率,high-resolution )中心框架 。如下图展示了 VSRDB 框架 FMA-Net。
。如下图展示了 VSRDB 框架 FMA-Net。
FMA-Net 包括两部分:退化学习网络 Net^D ;修复网络 Net^R 。退化学习网络用于估计感知运动的时空变化退化核;修复网络利用这些预测出的退化核来恢复模糊的低分辨率视频。

其中,退化学习网络 Net^D 用来预测运动感知的时空变化退化,而 Net^R 以全局自适应的方式利用 Net^D 预测的退化来恢复中心帧 X_c。
Net^D 和 Net^R 具有相似的结构,它们由 FRMA( feature refinement with multiattention )块和 FGDF( flow-guided dynamic filtering )块组成。
下图 4 (a) 显示了第 (i+1) 步更新时 FRMA 块的结构,图 4 (b) 为多注意力结构。

下图 2 展示了 FGDF 概念。FGDF 看起来类似于可变形卷积(DCN),但不同之处在于 FGDF 学习的是位置相关的 n×n 动态滤波器系数,而 DCN 学习的是位置不变的 n×n 滤波器系数。
此外,新提出的多注意力机制,包括以中心为导向的注意力和退化感知注意力,使得 FMA-Net 能够专注于目标帧,并以全局适应的方式使用退化核进行视频超分辨率和去模糊。

训练策略
该研究采用两阶段的训练策略来训练 FMA-Net。首先对 Net^D 进行预训练,损失 L_D 为:

然后,为了提高性能,本文还提出了 TA 损失,即等式右侧的最后一项。
总的训练损失为:

实验结果
表 1 显示了在测试集 REDS4 上的定量比较结果。从表 1 可以看出:
- 级联 SR 和去模糊的序列方法会导致先前模型的错误传播,导致性能显著下降,并且使用两个模型还会增加内存和运行时成本;
- 与序列级联方法相比,VSRDB 方法始终表现出优越的整体性能,表明这两个任务高度相关;
- FMA-Net 在 PSNR、SSIM 和 tOF 方面显著优于所有 SOTA 方法,具体来说,FMA-Net 比 SOTA 算法 RVRT * 和 BasicVSR++* 分别提高了 1.03 dB 和 1.77 dB。

表 2 为定量比较结果。当对两个测试集进行平均时,FMA-Net 的性能分别比 RVRT * 和 GShiftNet * 提高了 2.08 dB 和 1.93 dB。

下图为不同方法对 ×4 VSRDB 的可视化比较结果,表明 FMA-Net 生成的图像比其他方法生成的图像在视觉上更清晰。

不同方法在 REDS4、GoPro 和 YouTube 测试集上的可视化结果。放大观看效果最好。

了解更多技术细节,请阅读原文。