研究人员发现,在神经网络推理的某些数据图中存在尖峰,这些尖峰往往出现在神经网络判断模糊与产生错误的地方。观察这些尖峰,研究人员可以更容易发现人工智能系统中的故障点。
从分析癌症突变的原因到决定谁应该获得贷款,在解决这些问题的过程中,仿照人脑的神经网络比人类表现得更加快速、准确、公正。但是由于人工智能的工作并不透明,难以得知它们推理判断的过程,这引发了对人工智能可靠性的担忧。现在,一项新的研究提供了一种发现神经网络的错误出在哪里的方法。这项研究为揭示神经网络在出错时正在进行怎样的操作提供了可能。
神经网络在对数据集进行计算时,会将注意力集中在样本上,例如图像中是否包含人脸。编码这些细节的数字串被用来计算样本属于某个特定类别的概率。在本例中,计算的是图像中是否有一个人,以及这个人的脸是否显示出来。
然而,神经网络从哪些样本数据细节中习得了解决问题的方法,仍是未解之谜。神经网络的「黑盒」特性使得研究者难以判断神经网络给出的答案是否正确。
论文作者,普渡大学的计算机科学教授 David Gleich 认为:「当你向一个人询问解决某个问题的方法,他可以给出一个你能理解的答案。」但是神经网络不会给出他们的解题过程。
在这项新研究中,Gleich 和同事们没有追踪实验中神经网络对单个样本的决策过程,而是试图将系统对于整个数据库的所有决策结果与样本之间的关系进行可视化。
Gleich 表示:「我仍然对这项技术在帮助我们理解神经网络的可解释性。」研究团队用 ImageNet 数据库中的 130 万余张图片对神经网络进行了训练。他们开发了一种能够拆分与合并样本分类的方法,用以识别有高概率属于多个分类的图像。
在此基础上,研究团队运用拓扑学,绘制出了神经网络的推断结果与每个分类之间的关系图。拓扑学的知识能够帮助他们识别不同数据集之间的相似性。Gleich 表示:「基于拓扑数据分析的工具曾在分析乳腺癌中的特定亚群与基因是否有关的问题中发挥作用。」

论文链接:https://www.nature.com/articles/s42256-023-00749-8
在根据新研究成果生成的关系图中,每个点代表神经网络认为有关联的图像组,不同分类的图由不同的颜色表示。点之间的距离越近,神经网络认为每组图像越相似。这些地图的大部分区域都显示了单一颜色的点群。
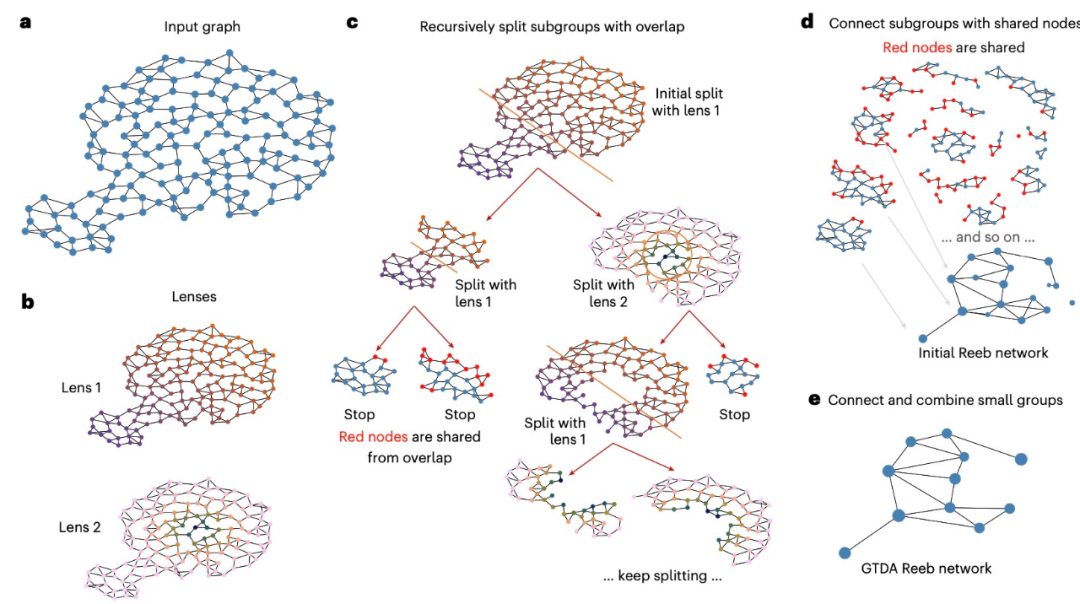
两个不同颜色的重叠点表示有高概率属于多个分类的图像。「我们的方法能够构建出类似地图的关系图,放大某些数据区域。」 Gleich 表示,「这些区域通常是某几个分类边界不明显的地方,在这些地方,解决方案可能并不那么清晰。不过,它能突出值得进一步研究的特定的数据预测。」
由新方法生成的地图能够显示网络无法分类的区域。这种方法提供了「让研究者能够运用人类与生俱来的思维方式来推测神经网络的推理思路」的途径。Gleich 表示道:「这使我们可以根据已知的网络来预测它将如何响应全新的输入。」
研究团队发现神经网络特别容易混淆如胸腔的 X 光片、基因序列以及服装等类别的图案。例如,当一个网络在 Imagenette 数据库(ImageNet 的一个子集)测试时,它反复地将汽车的图片归类为磁带播放器。他们发现这是由于这些图片是从网购列表中提取的,含有汽车音响设备的标签。
该团队的新方法有助于揭示「错误出在哪里」。Gleich 介绍说:「在这个层面上分析数据,可以让科学家们从仅仅在新数据上得到一堆有用的预测,深入理解神经网络可能是如何处理他们的数据的。」
「我们的工具似乎很擅长帮助发现训练数据本身是否包含错误,」Gleich 表示。「人们在手工标注数据时确实会犯错误。」
这种分析策略的潜在用途可能包括特别重要的神经网络应用。比如说,神经网络在医疗保健或医学中的应用,以研究败血症或皮肤癌。
批评者认为,由于大多数神经网络都是根据过去的决定训练出来的,这些决定反映了对人类群体本来存在的偏见,因此 AI 系统最终会复制过去的错误。Gleich 说,如果能找到一种方法来使用新工具「了解预测中的偏见或成见」,可能是一个显著的进步。
Gleich 表示,这一新工具可与神经网络一起使用,通过小数据集生成特定预测,例如「基因突变是否可能有害」。但目前为止,研究人员还没有办法将它应用于大语言模型或扩散模型。
了解更多内容,请参考原论文。