Linux文件系统作为操作系统的核心组成部分,其运行机制也是我们程序员需要了解和掌握的,磁盘为系统提供了最基本的持久化存储,文件系统则在磁盘的基础上提供系统里所有文件的管理,在Linux里一切皆文件,不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。今天我们就一起来聊一聊:磁盘和文件系统是怎么工作的?
索引节点和目录项
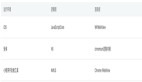
在Linux文件系统中,一个文件的元数据包括:目录项、索引节点、数据块。
- 目录项:简称为dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存(Cache)。
- 索引节点:简称为inode,用来记录文件的元数据,包括inode 编号、文件大小、访问权限、修改日期、数据的位置、链接数等,索引节点信息会持久化到磁盘中存储,占用磁盘空间。
- 数据块: 简称为block,存储文件数据的地方。磁盘的最小存储单位叫做扇区(Sector),每个扇区存储512字节,相当于0.5KB,操作系统读取硬盘的时候,不会一个扇区一个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB(八个sector)。
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
- 索引节点区,用来存储索引节点。
- 数据块区,用来存储文件或目录数据。
虚拟文件系统
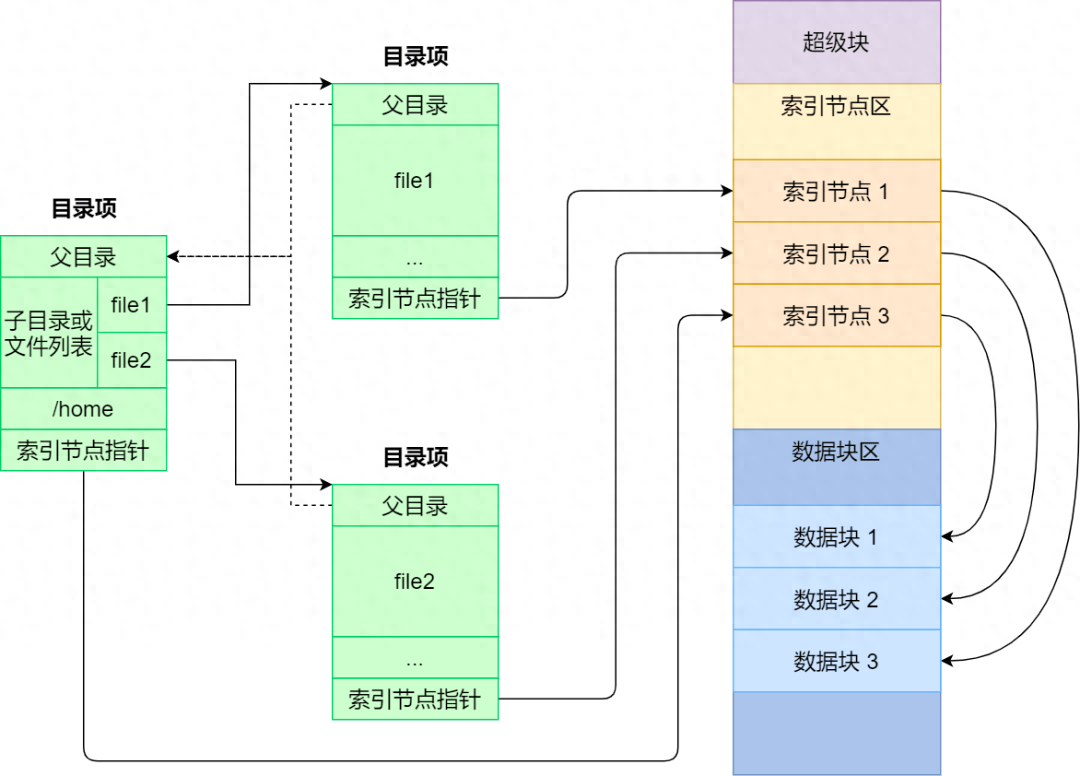
Linux系统中的虚拟文件系统(VFS,Virtual File System)是一个抽象层,用于提供统一的文件系统接口,使得用户和应用程序能够以相同的方式访问不同类型的文件系统,而无需关心底层文件系统的具体实现。
用户程序和 glibc 库都是属于用户空间的,本质都是用户程序。应用层的程序和glibc通过调用“系统调用层(SCI)”的函数,完成对文件的操作。这些函数是 Linux 内核对外提供的函数接口,用户通过这些函数向系统申请操作。比如系统cat命令,它首先调用open()函数 ,打开一个文件;然后调用read() 函数,读取文件的内容;最后再调用 write()函数 ,把文件内容输出到控制台的标准输出中。常见的文件系统类型又可以分为以下几大类:
- 基于本地磁盘:EXT3、EXT4、XFS、OverlayFS 等。这类文件系统的特点是数据直接存储在计算机本地挂载的磁盘中,性能好,没有网络IO的访问消耗。
- 基于网络文件系统:NFS、CIFS/SMB、CephFS、GlusterFS等,这类文件的特点是它们允许用户通过网络访问和管理文件。分布式、跨平台、灵活性和可扩缩性是它们的最大优势。
- 基于内存文件系统:tmpfs、ramfs、/proc等,这些基于内存的文件系统通常用于特定的用途,如临时文件存储、缓存、快速数据访问等。它们提供了在内存中进行文件读写操作的高性能解决方案,但也需要注意内存限制和数据易失性的特点。
文件 I/O
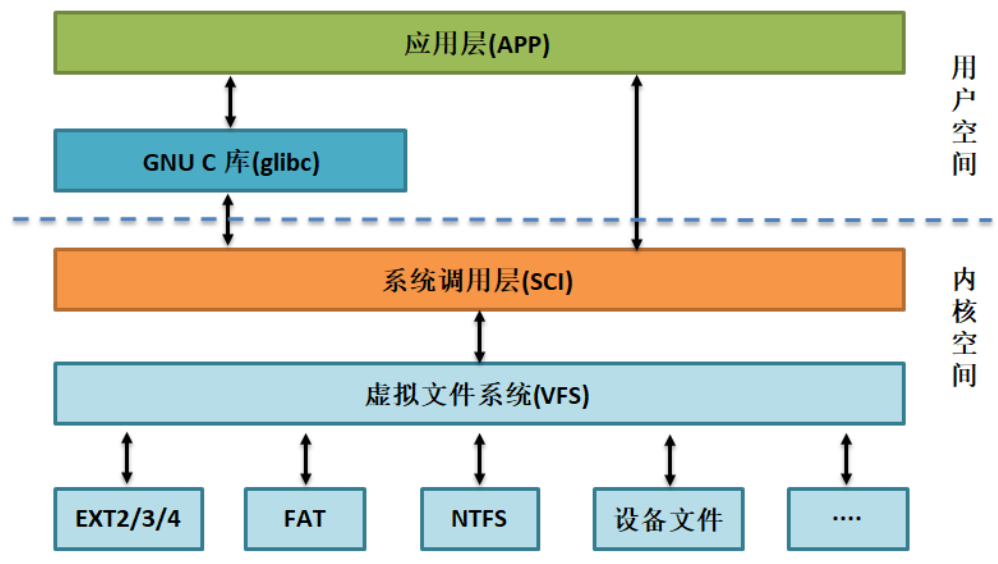
我们对磁盘进行的分区、格式化这些操作就是建立不同类型的文件系统,这些文件系统需要通过mount的方式挂载到Linux的VFS上的某个目录才能被系统使用,应用程序对文件的读写有不同的方式,也就是我们常说的I/O类型,以下是我们常见的I/O类型。
缓冲与非缓冲I/O
- 所谓不带缓冲,并不是指内核不提供缓冲,而是只单纯的系统调用,不是函数库的调用。系统内核对磁盘的读写都会提供一个块缓冲,当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行排队,当块缓冲达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓冲的I/O是指进程不提供缓冲功能。每调用一次write或read函数,直接系统调用。(内核提供缓冲的)。
- 而带缓冲的I/O是指进程对输入输出流进行了改进,提供了一个流缓冲。当用write函数写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。(双重缓冲)
- 因此,带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。
直接 I/O与非直接I/O
- 直接I/O:就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。
- 非直接I/O:就是文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用后写入磁盘。
- 对于直接I/O,如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载的效率会比较慢。但是类型于数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,使用直接I/O更合适。
阻塞I/O和非阻塞I/O
- 阻塞I/O:应用进程调用I/O操作时阻塞,只有等待要操作的数据准备好,并复制到应用进程的缓冲区中才返回。特点是:实现难度低、开发应用较容易,适用并发量小的网络应用开发。
- 非阻塞I/O:是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。特点是:相对来说复杂一些。适用并发量较小、且不需要及时响应的网络应用开发
同步和异步 I/O
- 同步I/O:是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 异步I/O:是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
关于文件的一些常见小知识
磁盘剩余空间还很多,新建文件和目录报空间不足。
- 排查思路:大概率是小文件太多,inode用完了,可以使用df -i。
du和df统计的硬盘使用情况不一致问题。
- du是统计被文件系统记录到的每个文件的大小,然后进行累加得到的总大小,是通过文件系统获取到的。而df主要是从超级块(superblock)中读入硬盘使用信息,df获取到的是磁盘块被使用的情况。产生这种情况大概率是有文件被删除了,但是有别的进程正在使用它(占有句柄),可以通过lsof | grep deleted查到。当进程停止或者被kill时,这些空间将被释放。
我们查询磁盘容量的时候,Used+Avail的大小为啥总是小于总容量(SIze)。
- 为了预防紧急情况,linux ext文件系统会预留部分硬盘空间,具体预留的数值可以通过tune2fs -l [dev_name] | grep “Reserved block count”查看到,(dev_name)是设备名,这里预留的空间会被df计算到已用空间中,从而导致df和du统计不一致。如果需要调整预留空间大小, 我们可以使用tune2fs -m [size] [dev_name]来进行调整。