













在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。

什么是RAG
在人工智能领域,检索增强生成(retrieve - augmented Generation, RAG)作为一种变革性技术改进了大型语言模型(Large Language Models)的能力。从本质上讲,RAG通过允许模型从外部源动态检索实时信息来增强AI响应的特异性。
该体系结构将生成能力与动态检索过程无缝结合,使人工智能能够适应不同领域中不断变化的信息。与微调和再训练不同,RAG提供了一种经济高效的解决方案,允许人工智能在不改变整个模型的情况下能够得到最新和相关的信息。
RAG的作用
1、提高准确性和可靠性
通过将大型语言模型(llm)重定向到权威的知识来源来解决它们的不可预测性。降低了提供虚假或过时信息的风险,确保更准确和可靠的反应。
2、增加透明度和信任
像LLM这样的生成式人工智能模型往往缺乏透明度,这使得人们很难相信它们的输出。RAG通过允许组织对生成的文本输出有更大的控制,解决了对偏差、可靠性和遵从性的关注。
3、减轻幻觉
LLM容易产生幻觉反应——连贯但不准确或捏造的信息。RAG通过确保响应以权威来源为基础,减少关键部门误导性建议的风险。
4、具有成本效益的适应性
RAG提供了一种经济有效的方法来提高AI输出,而不需要广泛的再训练/微调。可以通过根据需要动态获取特定细节来保持最新和相关的信息,确保人工智能对不断变化的信息的适应性。
多模式模态模型
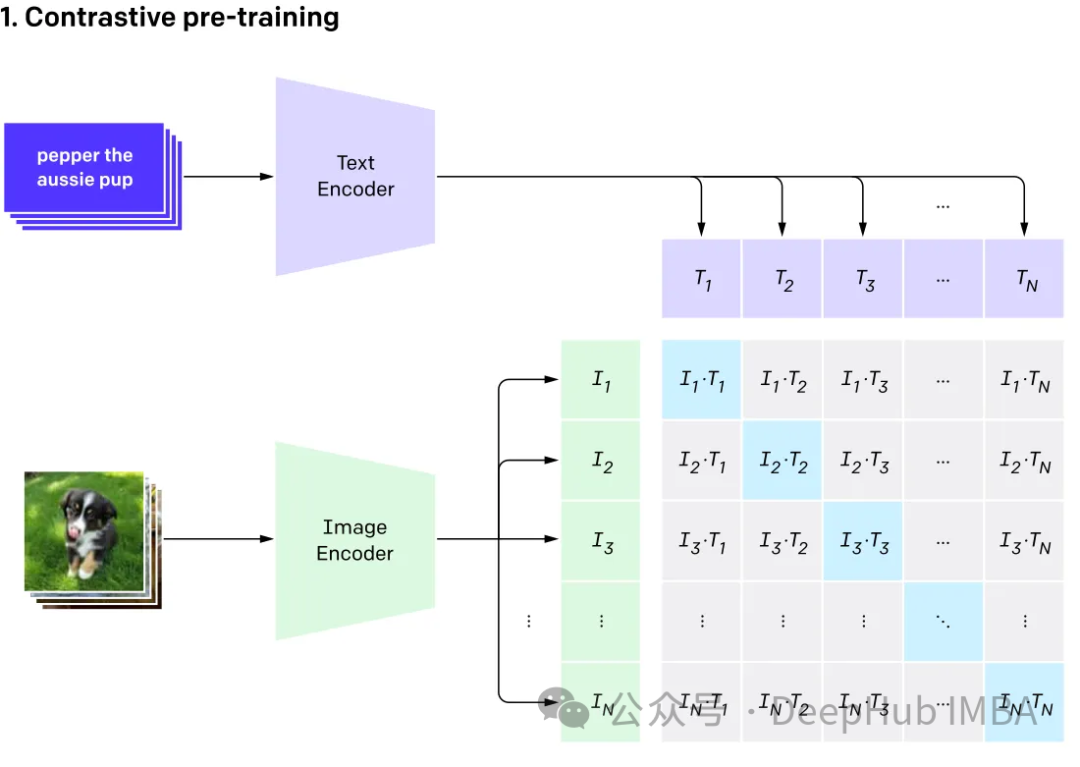
多模态涉及有多个输入,并将其结合成单个输出,以CLIP为例:CLIP的训练数据是文本-图像对,通过对比学习,模型能够学习到文本-图像对的匹配关系。
该模型为表示相同事物的不同输入生成相同(非常相似)的嵌入向量。
多模态大型语言(multi-modal large language)
GPT4v和Gemini vision就是探索集成了各种数据类型(包括图像、文本、语言、音频等)的多模态语言模型(MLLM)。虽然像GPT-3、BERT和RoBERTa这样的大型语言模型(llm)在基于文本的任务中表现出色,但它们在理解和处理其他数据类型方面面临挑战。为了解决这一限制,多模态模型结合了不同的模态,从而能够更全面地理解不同的数据。
多模态大语言模型它超越了传统的基于文本的方法。以GPT-4为例,这些模型可以无缝地处理各种数据类型,包括图像和文本,从而更全面地理解信息。
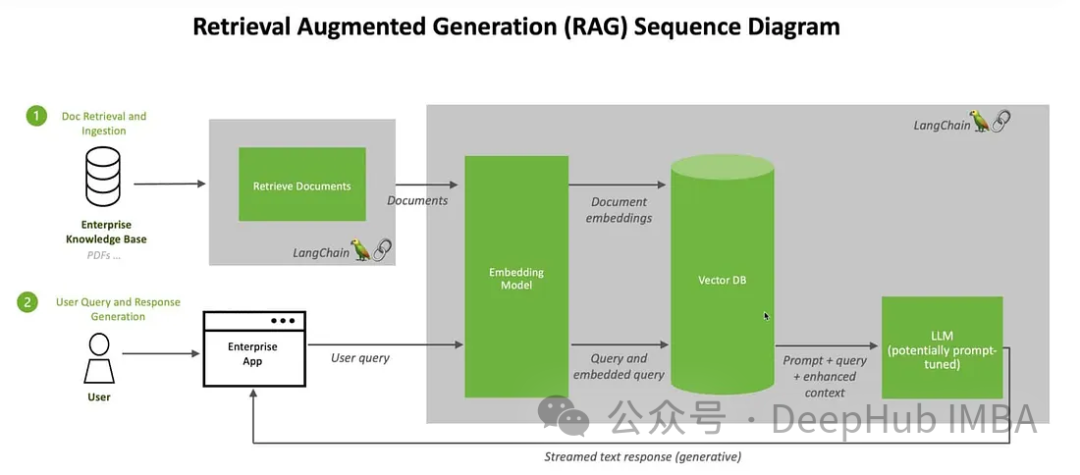
与RAG相结合
这里我们将使用Clip嵌入图像和文本,将这些嵌入存储在ChromDB矢量数据库中。然后将利用大模型根据检索到的信息参与用户聊天会话。
我们将使用来自Kaggle的图片和维基百科的信息来创建一个花卉专家聊天机器人。
首先我们安装软件包:
预处理数据的步骤很简单只是把图像和文本放在一个文件夹里。
可以随意使用任何矢量数据库,这里我们使用ChromaDB。
ChromaDB需要自定义嵌入函数。
这里将创建2个集合,一个用于文本,另一个用于图像。
对于Clip,我们可以像这样使用文本检索图像。

也可以使用图像检索相关的图像。

文本集合如下所示:
然后使用上面的文本集合获取嵌入。
结果如下:
或使用图片获取文本。

上图的结果如下:
这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。
我们是用visheratin/LLaVA-3b。
加载tokenizer。
然后定义处理器,方便我们以后调用。
下面就可以直接使用了。
得到的结果如下:

结果还包含了我们需要的大部分信息。

这样我们整合就完成了,最后就是创建聊天模板。
如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
https://github.com/nadsoft-opensource/RAG-with-open-source-multi-modal































