













Kafka是由Apache软件基金会开发一个开源流处理平台,使用Scala和Java编写, 该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个按照分布式事务日志架构的大规模发布/订阅消息队列。这种工作方式使它为企业级基础设施来处理流失数据非常有价值。
本文的目的是使用Docker容器来部署Kafka, 这样可以省略Kafka安装配置的中间过程, 节省大量时间。文章中分别从几个维度来阐述Kafka的部署过程, 包括:基础环境要求、安装zookeeper、容器内的设置等, 最后给出了一个从生产者角度向消费者发送消息, 消费者成功接收到消息作为结尾, 最后给出了一个在全过程当中遇到问题排查的正确方法。

认识Kafka
Kafka存储的消息来自任务多被称为"生产者"(Producer)的进程。数据从而可以被分配到不同的"分区"(Partition)、不同的“Topic”下。在一个分区内, 消息被索引并连同时间戳存储在一起。而其它被称为"消费者"(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上, 并且分区可以跨集群节点分布。Kafka的架构如下图所示:

以下列出了Kafka技术相关的术语:
- Topic - 用来对消息进行分类, 每个进入到Kafka的信息都会被放到一个Topic下。
- Broker - 用来实现数据存储的主机服务器。
- Partition - 每个Topic中的消息会被分为若干个Partition,以提高消息的处理效率
- Producer - 消息的生产者
- Consumer - 消息的消费者
了解了以上概念之后,对于Kafka的部署已经没有什么障碍, 下面开始正式的部署过程。
基础环境准备
大多数Linux发行版都支持安装Kafka,这里我准备了一台ubuntu 22.04.3 LTS版本的虚拟机作为试验环境。
登录到系统输入:docker -v 命令, 如果出现:
Docker version 24.0.5, build 24.0.5-0ubuntu1~22.04.1类似于这样的提示信息,说明Docker已安装,如果没有,请输入以下命令安装Docker:
$ sudo apt update
$ sudo apt install docker.io
安装zookeeper
由于Kafka依赖Zookeeper实现高可用性和一致性,其为Kafka提供了关键的分布式协调服务,因此部署Kafka必须先部署Zookeeper集群作为基础, 以下进入部署Zookeeper的过程:
在命令行直接输入以下命令,docker会自动拉取对应镜像:
# docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper拉取过程如图:

安装Kafka
Zookeeper安装成功后, 接着安装Kafka组件, 在命令行直接输入以下命令,docker会自动拉取对应镜像:
# docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=[你的IP地址]:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://[你的IP地址]:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka注意, 我的服务器IP是192.168.201.206,所以上面的IP要根据自己的实际情况进行变更,我变更后的命令如下:
# docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.201.206:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.201.206:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka拉取过程如图:

进入容器
Kafka安装完毕后,还要进入到容器中启动生产者和消费者,这样可以验证kafka功能是否正常,顺序执行命令如下:
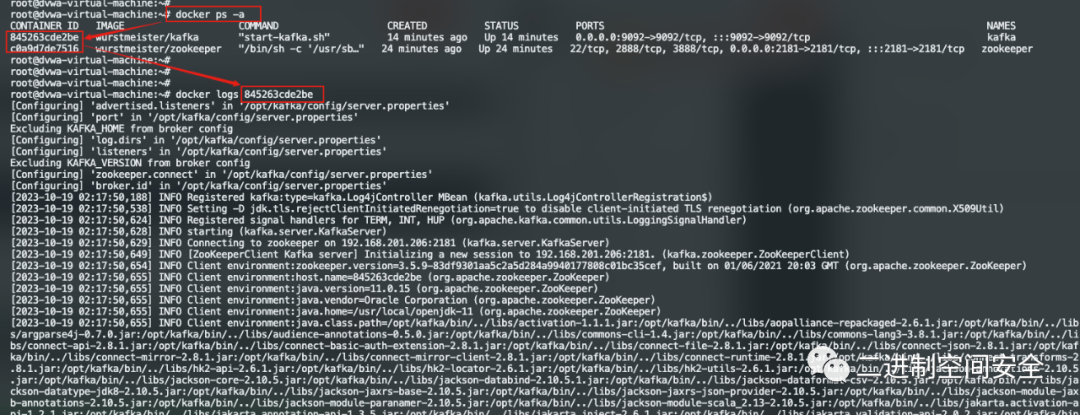
# docker ps -a #查看kafka镜像的容器ID
# docker exec -it 容器ID /bin/sh #进入到容器内部
# cd /opt/kafka/bin # 切到容器内部kafka执行目录下执行最后的结果如图:

启动生产者
在容器里执行以下命令启动生产者:
./kafka-console-producer.sh --broker-list localhost:9092 --topic [你的topic名称]我这里自己起了一个topic名称,名字为test123, 如图:

产生者脚本启动成功后,会有一个">"提示符。
启动消费者
为了看到生产者和消费者之间的消息传递效果,这里需要另开一个终端,按照上面的方法进入容器对应目录,并执行以下命令:
./kafka-console-consumer.sh --bootstrap-server [你的IP地址]:9092 --topic [你的topic名称]注意,这里有两个变量需要自己调整,一个是IP地址,另一个是上面建立的Topic名称, 我这里填入信息后的完整命令如下:
./kafka-console-consumer.sh --bootstrap-server 192.168.201.206:9092 --topic test123执行过程如图:

生产者与消费者测试
切换到生产者窗口,连续输入一些信息,如图:

再切换回消费者窗口, 正常的话已经可以收到生产者发送的信息了,如图:

1故障排查
如果在使用Docker过程中遇到任何错误, 可以命令:
docker logs 容器ID通过查看容器日志进行故障排查,过程如图:
总结
在部署Kafka的整个过程中, 遵循以下部署顺序流程:
- 首先检查Docker安装是否正常, 确保Docker安装无任何异常。
- 其次安装Kafka的依赖服务Zookeeper, 只需要一句命令可实现自动镜像拉取。
- 接着安装Kafka组件,也是一句命令即可搞定, 自动拉取对应的镜像。
- 进入到容器内部, 分别启动生产者和消费者脚本, 便可以开始进行发送消息测试了。
- 在整个部署过程中,遇到任何错误或问题都可以通过Docker日志进行问题排查。
















