这几天,家务活都被机器人抢着干了。
前脚来自斯坦福的会用锅的机器人刚刚登场,后脚又来了个会用咖啡机的机器人 Figure-01 。

只需给它观看示范视频,加上10个小时的训练,Figure-01 就能学会使用咖啡机,放咖啡胶囊到按下启动键,一气呵成。
但是想要让机器人无师自通,第一次见到各式各样的家具家电,就能在没有示范视频的情况下熟练使用。这是个难以解决的问题,不仅需要机器人拥有强大的视觉感知、决策规划能力,更需要精确的操纵技能。
现在,一个三维具身图文大模型系统为以上难题提供了新思路。该系统将基于三维视觉的精准几何感知模型与擅长规划的二维图文大模型结合了起来,无需样本数据,即可解决与家具家电有关的复杂长程任务。
这项研究由斯坦福大学的 Leonidas Guibas 教授、北京大学的王鹤教授团队,与智源人工智能研究院合作完成。

论文链接:https://arxiv.org/abs/2312.01307
项目主页:https://geometry.stanford.edu/projects/sage/
代码:https://github.com/geng-haoran/SAGE
研究问题概述

图 1:根据人类指令,机械臂能够无师自通地使用各种家用电器。
近日,PaLM-E 和 GPT-4V 带动了图文大模型在机器人任务规划中的应用,视觉语言引导下的泛化机器人操控成为了热门研究领域。
以往的常见方法是建立一个两层的系统,上层的图文大模型做规划和技能调度,下层的操控技能策略模型负责物理地执行动作。但当机器人在家务活中面对各种各样从未见过并且需要多步操作的家用电器时,现有方法中的上下两层都将束手无策。
以目前最先进的图文大模型 GPT-4V 为例,虽然它可以对单张图片进行文字描述,但涉及可操作零部件检测、计数、定位及状态估计时,它仍然错误百出。图二中的红色高亮部分是 GPT-4V 在描述抽屉柜、烤箱和立柜的图片时出现的各种错误。基于错误的描述,机器人再进行技能调度,显然不太可靠。

图 2:GPT-4V 不能很好处理计数,检测,定位,状态估计等泛化操控所关注的任务。
下层的操控技能策略模型负责在各种各样的实际情况中执行上层图文大模型给出的任务。现有的研究成果大部分是基于规则生硬地对一些已知物体的抓取点位和操作方式进行了编码,无法泛应对没见过的新物体类别。而基于端到端的操作模型(如 RT-1,RT-2 等)只使用了 RGB 模态,缺乏对距离的准确感知,对新环境中如高度等变化的泛化性较差。
受王鹤教授团队之前的 CVPR Highlight 工作 GAPartNet [1] 启迪,研究团队将重点放在了各种类别的家用电器中的通用零部件(GAPart)之上。虽然家用电器千变万化,但总有几样零件不可或缺,每个家电和这些通用的零件之间存在相似的几何和交互模式。
由此,研究团队在 GAPartNet [1] 这篇论文中引入了 GAPart 这一概念。GAPart 指可泛化可交互的零部件。GAPart 出现在不同类别的铰接物体上,例如,在保险箱,衣柜,冰箱中都能找到铰接门这种零件。如图 3,GAPartNet [1] 在各类物体上标注了 GAPart 的语义和位姿。

图3:GAPart:可泛化可交互的零部件[1]。
在之前研究的基础上,研究团队创造性地将基于三维视觉的 GAPart 引入了机器人的物体操控系统 SAGE 。SAGE 将通过可泛化的三维零件检测 (part detection),精确的位姿估计 (pose estimation) 为 VLM 和 LLM 提供信息。新方法在决策层解决了二维图文模型精细计算和推理能力不足的问题;在执行层,新方法通过基于 GAPart 位姿的鲁棒物理操作 API 实现了对各个零件的泛化性操作。
SAGE 构成了首个三维具身图文大模型系统,为机器人从感知、物理交互再到反馈的全链路提供了新思路,为机器人能够智能、通用地操控家具家电等复杂物体探寻了一条可行的道路。
系统介绍
图 4 展示了 SAGE 的基本流程。首先,一个能够解读上下文的指令解释模块将解析输入机器人的指令和其观察结果,将这些解析转化为下一步机器人动作程序以及与其相关的语义部分。接下来,SAGE 将语义部分(如容器 container)与需要进行操作部分(如滑动按钮 slider button)对应起来,并生成动作(如按钮的 「按压 press」 动作)来完成任务。
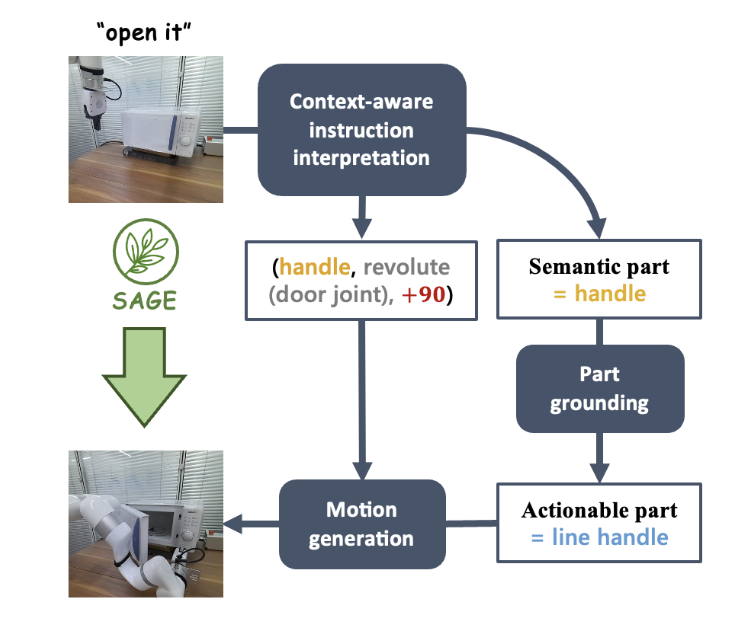
图 4:方法概览。
为了方便大家理解整个系统流程,一起来看看在无需样本的情况下,让机械臂使用操作一款没见过的微波炉的例子。
指令解析:从视觉和指令输入到可执行的技能指令
输入指令和 RGBD 图像观测后,解释器首先使用 VLM 和 GAPartNet [1] 生成了场景描述。随后,LLM(GPT-4)将指令和场景描述作为输入,生成语义零件和动作程序。或者也可以在这个环节输入一个特定的用户手册。LLM 将基于输入生成一个可操作零件的目标。

图 5:场景描述的生成(以 zero-shot 使用微波炉为例)。
为了更好地协助动作生成,场景描述包含物体信息、零件信息以及一些与互动相关的信息。在生成场景描述之前,SAGE 还将采用专家级 GAPart 模型 [1] 为 VLM 生成专家描述作为提示。这种兼收了两种模型的优点的方法效果良好。
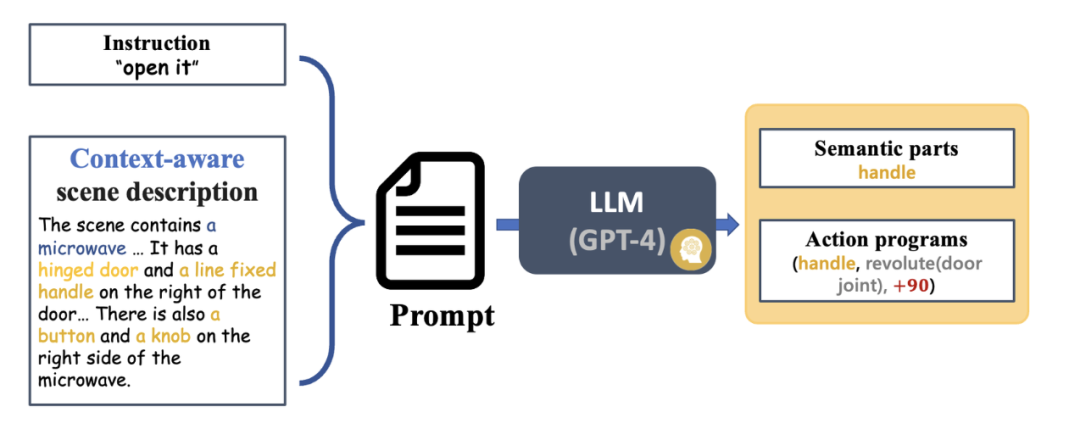
图 6:指令理解和运动规划(以 zero-shot 使用微波炉为例)。
零件交互信息的理解与感知

图 7:零件理解。
在输入观察结果的过程中,SAGE 综合了来自 GroundedSAM 的二维(2D)提示和来自 GAPartNet 的三维(3D)提示,然后这些提示被用作可操作零件的具体定位。研究团队利用 ScoreNet、非极大值抑制(NMS)和 PoseNet 等展示了新方法的感知结果。
其中:(1)对于零件感知评估基准,文章直接采用了 SAM [2]。然而,在操作流程中,文章使用了 GroundedSAM,它也考虑到了作为输入的语义零件。(2)如果大型语言模型(LLM)直接输出了一个可操作零件的目标,那么定位过程将被绕过。

图 8:零件理解(以 zero-shot 使用微波炉为例)。
动作生成
一旦将语义零件定位到可操作零件之上,SAGE 将在这个零件上生成可执行的操作动作。首先,SAGE 将估计零件的姿态,根据铰接类型(平移或旋转)计算铰接状态(零件轴线和位置)和可能的运动方向。然后,它再根据以上估算生成机器人操作零件的动作。
在启动微波炉这个任务中,SAGE 首先预测机械臂应该以一个初始夹爪姿态作为主要动作。再根据 GAPartNet [1] 中定义的预定策略产生动作。这个策略是根据零件姿态和铰接状态确定的。例如,为了打开一个带有旋转铰接的门,起始位置可以在门的边缘或把手上,其轨迹是沿着门铰链定向的圆弧。
交互反馈
到目前为止,研究团队只使用了一个初始观测来生成开环交互。这时,他们引入了一种机制,可以进一步利用在互动过程中获得的观测结果,更新感知结果并相应调整操作。为了实现这一目标,研究团队为互动过程中引入了一个两部分的反馈机制。
应当注意,在首次观测的感知过程中可能出现遮挡和估算错误。

图 9:直接开门不能打开,该轮交互失败(以 zero-shot 使用微波炉为例)。
为了解决这些问题,研究者们进而提出了一个模型,利用交互式观测 (Interactive Perception) 来增强操作。在整个互动过程中,目标夹持器和零件状态的跟踪得以保持。如果出现显著的偏差,规划器可以自行选择以下四种状态之一:「继续」、「转移到下一步」、「停止并重新规划」或 「成功」。
例如,如果设置夹持器沿着一个关节旋转 60 度,但门只打开了 15 度,大型语言模型(LLM)规划器会选择 「停止并重新规划」。这种互动跟踪模型确保 LLM 在互动过程中能够具体问题具体分析,在微波炉启动失败的挫折中也能重新「站起来」。

图 10:通过交互反馈和重新规划,机器人意识到按钮打开的方法并成功。
实验结果
研究团队首先搭建了一个大规模语言指导的铰接物体交互的测试基准。

图 11:SAPIEN 模拟实验。
他们使用了 SAPIEN 环境 [4] 进行了模拟实验,并设计了 12 项语言引导的铰接物体操作任务。对于微波炉、储物家具和橱柜的每个类别,各设计了 3 个任务,包括在不同初始状态下的开启状态和关闭状态。其他任务为「打开锅盖」、「按下遥控器的按钮」和「启动搅拌器」。实验结果显示,在几乎所有任务中 SAGE 都表现卓越。
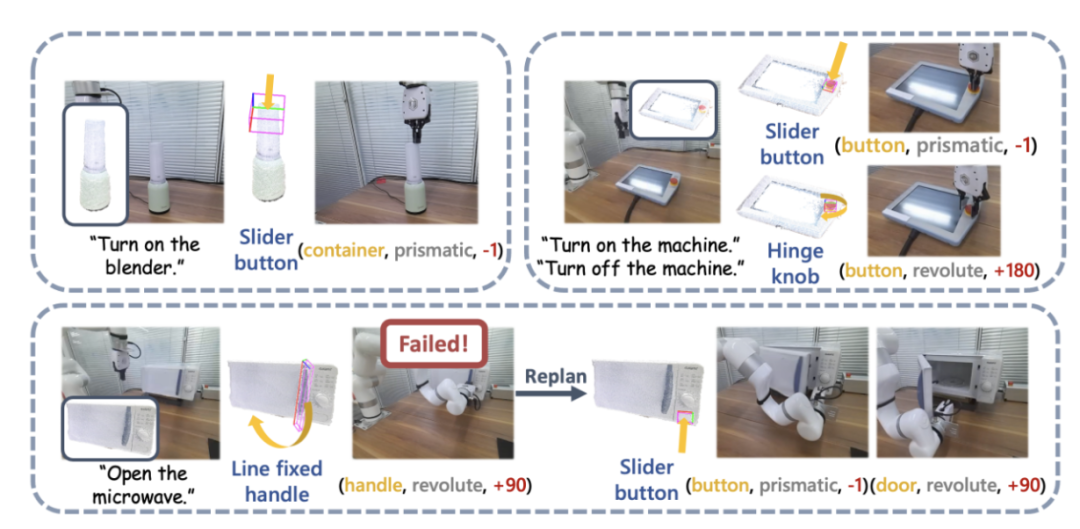
图 12:真机演示。
研究团队同时也进行了大规模真实世界实验,他们使用 UFACTORY xArm 6 和多种不同的铰接物体进行操作。上图的左上部分展示了一个启动搅拌器的案例。搅拌器的顶部被感知为一个用于装果汁的容器,但其实际功能需要按下一个按钮来开启。SAGE 的框架有效地连接了其语义和动作理解,并成功执行了任务。
上图右上部分展示了机器人,需要按下(下压)紧急停止按钮来停止操作,旋转(向上)来重启。借助用户手册的辅助输入,在 SAGE 指导下的机械臂完成了这两个任务。上图底部的图片展示了开启微波炉任务中的更多细节。

图 13:更多真机演示和指令解读示例。
总结
SAGE是首个能够生成通用的家具家电等复杂铰接物体操控指令的三维视觉语言模型框架。它通过在零件级别上连接物体语义和可操作性理解,将语言指令的动作转化为可执行的操控。
此外,文章还研究了将通用的大型视觉 / 语言模型与领域专家模型相结合的方法,以增强网络预测的全面性和正确性,更好地处理这些任务并实现最先进的性能。实验结果表明,该框架具有强大的泛化能力,可以在不同物体类别和任务上展示出优越的性能。此外,文章还为语言指导的铰接物体操作提供了一个新的基准测试。
团队介绍
SAGE 这一研究成果来自斯坦福大学 Leonidas Guibas 教授实验室、北京大学王鹤教授具身感知和交互(EPIC Lab)以及智源人工智能研究院。论文的作者为北京大学学生、斯坦福大学访问学者耿浩然(共同一作)、北京大学博士生魏松林(共同一作)、斯坦福大学博士生邓丛悦,沈博魁,指导老师为 Leonidas Guibas 教授和王鹤教授。