













本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人理解
三维场景标注通常需要耗费大量的人力物力财力,是制约自动驾驶模型训练迭代的一大瓶颈问题,从大量的二维视频中自监督地学习出有效的三维场景表示是一个有效的解决方案。我们提出的SelfOcc通过使用NeRF监督首次实现仅使用视频序列进行三维场景表示(BEV或TPV)学习。SelfOcc在自监督单目场景补全、环视三维语义占有预测、新视角深度合成、单目深度估计和环视深度估计等任务上均取得了SOTA的性能。

SelfOcc的相关背景
自监督3D占用预测
在当前的自动驾驶技术领域,以视觉为核心的系统通常依赖于精细的三维(3D)标注来学习有效的3D表示。然而,这种依赖精细3D标注的方法面临着严峻挑战,主要表现在3D标注获取的高成本,尤其是在近来被提出的3D占用预测任务中,这一问题尤为突出。
3D占用预测任务的核心在于预测一个场景中各个体素是否被占用。但是,要实现这一点,大多数现有方法需要对每个体素进行逐一的语义监督。这种方法虽然能够提供精确的3D表示,但其训练过程极其耗时且成本高昂,这使得这些方法难以应用于大规模数据训练。为了解决这一问题,目前已有一些自监督的3D占用预测方法被提出,如SceneRF和BTS。然而,这些方法主要针对单目视频,无法有效处理环视场景。
在这种背景下,SelfOcc方法的提出显得尤为重要。SelfOcc的目标是通过自监督学习方式,有效学习3D表示。与传统方法不同,SelfOcc不单单聚焦于单一视角,而是通过显式建模3D表示,天然地融合了单目和环视两种视角。这种方法能够利用单目视频的数据来理解3D结构,同时也能够处理环视视频,从而为自动驾驶车辆提供更全面、更精确的环境感知能力。
可泛化神经辐射场
以2D图像为基础的自监督3D重建的主要范式是神经辐射场(NeRF),它通过从多个视角捕获的2D图像来重建3D场景。NeRF的核心优势在于其能够生成高度真实且连续的三维视觉效果,但传统的NeRF方法在训练过程中需要大量的同一场景的不同视角图像,这在实际应用中是一个显著的限制。而且,传统NeRF缺乏对新场景的泛化能力,意味着它无法有效处理之前未见过的场景。
为了克服这些限制,部分研究工作提出了以图像特征为条件的NeRF。这种方法的目的是通过较少的视角来实现对3D场景的重建,同时增强模型对新场景的泛化能力。然而,这种方法仅依赖于2D图像特征作为主要的信息源,而忽略了3D特征编码对于深层次的3D感知和理解的重要性。
在这个背景下,SelfOcc提供了一个新的视角。与传统的以2D图像特征为基础的方法不同,SelfOcc显著地强调了学习场景级别的3D表示的重要性。它的特征提取过程主要在三维空间内进行,这意味着SelfOcc不仅关注二维图像所呈现的表面信息,而更重要的是,它能够探索和理解空间中的深层结构和关系。这种方法通过直接在三维空间内提取和处理特征,能够更全面地捕捉到场景的三维特性,从而提高了三维重建的质量和准确性。
自监督深度估计
NeRF的训练过程面临着一些显著的挑战,特别是收敛速度慢和容易发生过拟合的问题。这些问题主要源于NeRF对场景的高度非线性建模和对训练数据的密集依赖。为此,一些研究工作开始引入深度信息作为辅助监督,或者采用自监督深度估计约束。
引入深度信息作为辅助监督的方法基于这样一个理念:通过提供额外的深度信息,可以帮助NeRF更好地理解场景的空间结构,从而加速训练过程并减少过拟合的风险。同时,自监督深度估计约束的引入旨在通过对深度估计的优化来提高NeRF模型的泛化能力。然而,这些方法在实际应用中也面临一些固有的挑战。首先,NeRF的体渲染积分过程为优化深度引入了多余的自由度,这使得深度优化变得复杂且不稳定。此外,视角变换后的双线性插值限制了优化深度的感受野,导致深度估计易受局部特征的影响,从而容易陷入局部最优。
为了克服这些挑战,SelfOcc提出了一种创新的MVS-embedded策略,以实现稳定高效的自监督深度优化。MVS(Multi-View Stereo)技术是一种成熟的三维重建技术,它能够从多个视角的图像中重建出精确的三维模型。SelfOcc通过将MVS技术嵌入到NeRF的训练过程中,利用MVS的强大深度估计能力来指导NeRF模型的优化。这种策略有效地减少了体渲染过程中的自由度,使得深度优化过程更加稳定和高效。同时,MVS-embedded策略通过整合多个视角的信息,扩大了深度优化的感受野,从而减少了局部最优的风险。
详解SelfOcc算法

上图是SelfOcc方法的整体流程图:SelfOcc首先利用2D图像主干网络提取得到多尺度图像特征,再使用3D特征编码器从图像特征中提取3D场景表示,最后通过轻量级解码器将3D表示解码为符号距离场(SDF),并通过时序帧之间的提渲染约束实现监督。
从2D图像到3D占用
SelfOcc首先通过一个图像编码器处理2D输入图像。该图像编码器的主要任务是将标准的2D图像转换为包含丰富信息的多尺度特征图,从而为后续的三维表示提供必要的原始数据。随后,SelfOcc利用三维编码器处理这些多尺度图像特征图。三维编码器的功能是将二维图像特征转化为三维空间表示(BEV/TPV)。这一转换过程是将二维平面信息扩展到三维空间的关键步骤,它使得模型能够探索和理解空间中的深层结构和关系。最后,SelfOcc使用一个轻量级的解码器从3D表示中解码出最终的三维占用预测结果。
从3D占用到2D图像
为了有效地自监督生成的3D表示,SelfOcc采用了基于SDF的体渲染技术,将3D表示渲染为2D图像和深度图。
具体而言,SelfOcc首先使用解码器将3D表示解码为符号距离场(SDF)。SDF提供了一种描述物体表面的有效方式,其中每个点的值表示该点到最近表面的距离,正负号表示点在物体内部还是外部。相较于密度场,SDF具有更加明确的物理意义和关于梯度大小的约束,从而使其在进行正则化和优化时更加高效。此外,SDF的另一个优点是其在处理复杂几何形状时的精确度,因为一个点的符号可以直接确定它在表面内还是在表面外。
得到SDF场之后,SelfOcc通过体渲染生成2D结果。在这个过程中,一条从观察点出发穿过三维场景的光线被模拟,沿光线路径收集体素的属性信息,然后基于这些信息计算出最终像素的颜色和强度。
以3D占用为核心的监督策略
基于MVS的深度优化策略

SelfOcc提出了一种创新的深度优化策略,称之为MVS-embedded策略,旨在解决NeRF框架下使用传统自监督深度估计约束时遇到的一些关键问题。自监督深度估计通常需要经过一个复杂的积分过程,该过程涉及将深度信息积分到一个单一的值,随后通过透视投影进行两个视角间的转换,并最终通过比较目标像素和源图像上经过双线性插值得到的源像素来评估深度估计的准确性。然而,这种做法存在一些本质的限制。首先,积分过程的多自由度问题导致了深度估计在优化过程中的震荡和不确定性。此外,采用双线性插值的方法限制了深度优化的感受野,意味着深度估计过程过于依赖于局部特征,难以捕捉到更广阔的场景上下文,从而容易陷入局部极值。
为了克服这些限制,SelfOcc提出了一种直接优化一条射线上的多个深度proposal的权重的方法,从而避免了复杂的积分过程。这种策略的核心在于,通过对射线上不同深度点的权重进行优化,我们可以更直接地评估每个深度点的贡献和重要性,从而获得更准确和稳定的深度估计。此外,这种方法中多个深度proposal的引入显著增大了深度优化的感受野,这意味着我们的优化过程可以考虑到更广泛的场景信息,从而减少局部极值的问题。
时序约束和SDF场的正则化
考虑到自动驾驶相机通常朝外并且每个相机的视角重叠区域较小,SelfOcc选择使用时序上相邻的帧——即之前和之后的帧——作为NeRF的监督目标。这种方法考虑到了自动驾驶场景中视角变化的独特性,通过利用时间上的连续性来弥补空间视角重叠不足的问题。
在SDF场的正则化方面,我们采用了多种措施以确保SDF的物理意义和连续性。首先,我们引入了Eikonal loss,这是一种常用于保证SDF物理合理性的正则化方法。Eikonal loss的主要作用是确保SDF在空间中的梯度大小保持恒定,这有助于保持SDF场的一致性和准确性。其次,我们还引入了二阶导数约束,这种约束的目的是提高SDF的空间连续性。通过限制SDF的二阶导数,我们可以更好地控制SDF场的平滑度,减少在复杂几何形状处的不连续和尖锐变化。除此之外,我们还引入了稀疏性约束,这是为了强制模型将看不到的区域预测为空。在自动驾驶的应用中,由于视角的限制,总会有一部分区域是不可见的。通过稀疏性约束,我们可以确保这些不可见区域在SDF场中被合理处理,避免在这些区域产生误导性的预测。这些正则化措施在面对少视角的欠定问题时,能够有效地引导SDF学习过程,确保学到的SDF场在满足视角重建的要求的同时,尽可能地与物理先验对齐。
实验
我们在三个主要自动驾驶数据集上开展了实验,包括nuScenes,SemanticKITTI和KITTI-2015,覆盖三维占有预测,新视角深度预测和深度估计等自监督三维理解任务。所有实验在8张RTX 3090上进行,训练和测试代码均已开源。以下是主要实验结果和可视化,更多内容详见论文和GitHub仓库。
自监督3D占用预测

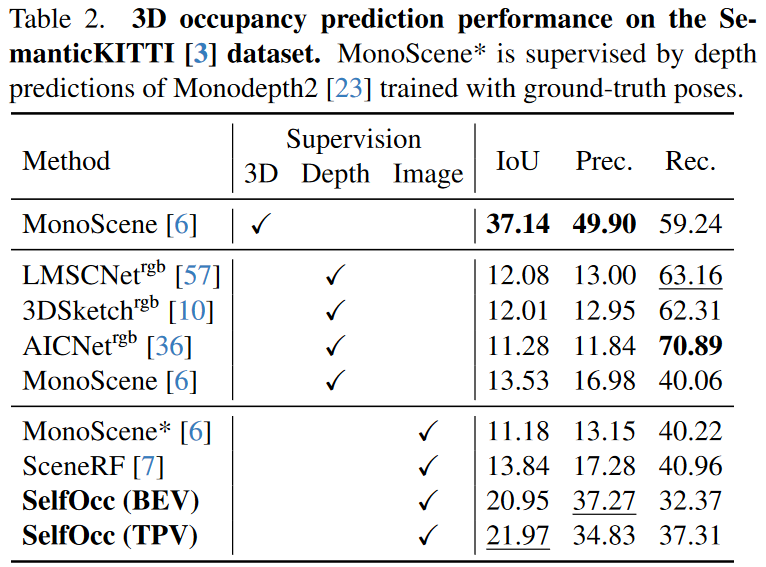
表1和表2列出了3D占用预测任务的结果。在Occ3D数据集上,与有监督方法相比,我们的方法没有使用任何形式的3D监督,仍取得了较高的IoU以及合理的mIoU。45.01%的IoU表明SelfOcc从视频序列中学习到了有意义的几何结构。更重要的是,相比LiDAR监督的TPVFormer和3D真值监督的MonoScene,SelfOcc甚至取得了更高的IoU和mIoU。
在SemanticKITTI数据集上,我们将各种方法归类为3D真值、深度和图片监督三种类别。从表2可以看出,SelfOcc取得了基于视觉的深度监督和图片监督的3D占有预测方法的新SOTA,并且在IoU指标上超过上一任SOTA方法SceneRF达58.7%。
自监督新视角深度预测

表3展示了SelfOcc在自监督新视角深度预测任务上的性能。SelfOcc在SemanticKITTI和nuScenes数据集上的所有指标上都优于之前最先进的SceneRF。
自监督深度预测

表4展示了SelfOcc在自监督深度估计任务上的性能。SelfOcc在nuScenes上取得了SOTA结果,且与KITTI-2015数据集上的SOTA方法性能相当。
可视化


上面两幅图展示了SelfOcc在nuScenes数据集上的自监督3D占有预测和深度估计的可视化结果。
论文信息
作者:黄原辉*,郑文钊*,张博睿,周杰,鲁继文
机构:清华大学自动化系
文章链接:https://arxiv.org/pdf/2311.12754.pdf
项目主页:https://huang-yh.github.io/SelfOcc/
代码仓库:https://github.com/huang-yh/SelfOcc (已开源)

原文链接:https://mp.weixin.qq.com/s/3ysN139lRE8Txl1YU7Nfyw

















