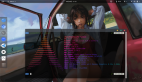
Segment Anything Model (SAM) 的提出在图像分割领域引起了巨大的关注,其卓越的泛化性能引发了广泛的兴趣。然而,尽管如此,SAM 仍然面临一个无法回避的问题:为了使 SAM 能够准确地分割出目标物体的位置,每张图片都需要手动提供一个独特的视觉提示。如下图所示,即使点击的是同一物体(图 (b)-(d)),微小位置变化都会导致分割结果的显著差异。这是因为视觉提示缺乏语义信息,即使提示在想要分割的目标物体上,仍然可能引发歧义。框提示和涂鸦提示(图 (e)(f))虽然提供了更具体的位置信息,但由于机器和人类对目标分割物的理解存在偏差,效果常常与期望有所出入。

目前的一些方法,如 SEEM 和 AV-SAM,通过提供更多模态的输入信息来引导模型更好地理解要分割的物体是什么。然而,尽管输入信息变得更加具体和多样化,但在实际场景中,每个无标注样本仍然需要一个独特的提示来作为指导,这是一种不切实际的需求。理想情况下,作者希望告知机器当前的无标注数据都是采集自于什么任务,然后期望机器能够批量地按照作者的要求对这些同一任务下的样本进行分割。然而,当前的 SAM 模型及其变体受到必须为每幅图手动提供提示这一要求的限制,因此很难实现这一点。

来自伦敦大学玛丽女王学院的研究者们提出了一种无需训练的分割方法 GenSAM ,能够在只提供一个任务通用的文本提示的条件下,将任务下的所有无标注样本进行有效地分割。

- 论文链接:https://arxiv.org/pdf/2312.07374.pdf
- 项目链接:https://lwpyh.github.io/GenSAM/
- 代码链接:https://github.com/jyLin8100/GenSAM/
问题设置
对于给定的分割任务,例如伪装样本分割,对于该任务下来自各个数据集的所有无标注样本,只提供一个任务描述:“the camouflaged animal” 作为这些图片的唯一提示  。对于该任务下的任意一张图像
。对于该任务下的任意一张图像  ,需要利用
,需要利用  来有针对性地完成与任务相关的目标的分割。在这种情况下,目标是根据任务描述准确地分割图像中伪装的动物。模型需要理解并利用提供的任务描述来执行分割,而不依赖于手动提供每个图像的特定提示。
来有针对性地完成与任务相关的目标的分割。在这种情况下,目标是根据任务描述准确地分割图像中伪装的动物。模型需要理解并利用提供的任务描述来执行分割,而不依赖于手动提供每个图像的特定提示。
这种方法的优势在于,通过提供通用任务描述,可以批量地处理所有相关任务的无标注图片,而无需为每个图片手动提供具体的提示。这对于涉及大量数据的实际场景来说是一种更加高效和可扩展的方法。
GenSAM 的流程图如下所示:

方法介绍
为了解决这一问题,作者提出了 Generalizable SAM(GenSAM)模型,旨在摆脱像 SAM 这类提示分割方法对样本特定提示的依赖。具体而言,作者提出了一个跨模态思维链(Cross-modal Chains of Thought Prompting,CCTP)的概念,将一个任务通用的文本提示映射到该任务下的所有图片上,生成个性化的感兴趣物体和其背景的共识热力图,从而获得可靠的视觉提示来引导分割。此外,为了实现测试时自适应,作者进一步提出了一个渐进掩膜生成(Progressive Mask Generation,PMG)框架,通过迭代地将生成的热力图重新加权到原图上,引导模型对可能的目标区域进行从粗到细的聚焦。值得注意的是,GenSAM 无需训练,所有的优化都是在实时推理时实现的。
跨模态思维链
Cross-modal Chains of Thought Prompting (CCTP)
随着大规模数据上训练的 Vision Language Model (VLM) 的发展,如 BLIP2 和 LLaVA 等模型具备了强大的推理能力。然而,在面对复杂场景,如伪装样本分割时,这些模型很难准确推理出复杂背景下任务相关物体的身份,而且微小提示变化可能导致结果显著差异。同时,目前的 VLM 只能推理出可能的目标描述,而不能将其定位到图像中。为了解决这一问题,作者以现有任务描述  为基础构建了多个思维链,希望通过从多个角度获得共识来推理第 j 个链上前景物体的关键词
为基础构建了多个思维链,希望通过从多个角度获得共识来推理第 j 个链上前景物体的关键词  和背景的关键词
和背景的关键词  。
。
然而,当前大多数求取共识的方法基于一个假设:VLM 的输出结果是有限的,可以通过多数表决来确定正确答案。在作者的场景中,链路数量是有限的,而输出结果是无法预测的。过去的多数表决方法在这里难以应用。此外,VLM 只能推理出可能目标的关键词,而不能将其准确定位于图像中。
为了克服这一问题,受到 CLIP Surgery 的启发,作者提出了一个 spatial CLIP 模块,在传统的 CLIP Transformer 基础上添加了一个由 K-K-V 自注意力机制构成的 Transformer 结构,将 VLM 在不同链路上推理得到的不可预测的关键词映射到同一张热力图上。这样,无法在语言层面求取共识的问题可以在视觉层面上得到解决。具体而言,作者通过 Spatial CLIP 的共识特征  和
和  分别获取不同链路上的前景和背景关键词。由于复杂场景中背景物体可能对结果产生干扰,作者通过用
分别获取不同链路上的前景和背景关键词。由于复杂场景中背景物体可能对结果产生干扰,作者通过用  减去
减去  来排除这种干扰,得到最终的相似度热力图
来排除这种干扰,得到最终的相似度热力图  。$SI$ 通过上采样到原有图片的大小,即获得了定位任务相关目标位置的热力图 H 。其中,具有很高和很低置信度的点分别被视为正和负提示点,它们被筛选出来用于引导 SAM 进行分割。
。$SI$ 通过上采样到原有图片的大小,即获得了定位任务相关目标位置的热力图 H 。其中,具有很高和很低置信度的点分别被视为正和负提示点,它们被筛选出来用于引导 SAM 进行分割。
渐进掩膜生成
Progressive Mask Generation (PMG)
然而,单一的推断可能无法提供令人满意的分割结果。对于具有复杂背景的图像,热图中某些背景对象可能也会在很大程度上被激活,导致在推断点提示时出现一些噪声。为了获得更强大的提示,作者使用热图作为视觉提示,对原始图像进行重新加权,并在测试时引导模型进行适应。加权图像  可以通过下面的公式获得:
可以通过下面的公式获得:

这里 X 是输入图片,$w_{pic}$ 是权重,$H$ 是热力图。此外,在随后的迭代中,作者使用前一次迭代的掩码通过绘制边界框来引导分割,作为后处理步骤。作者选择与掩码具有最高 IoU(交并比)值的框作为作者的选择。这优化了当前迭代并提高了分割结果的一致性。第 i 次迭代获得的掩码被定义为  ,其中 i ∈ 1,...,Iter。Iter 被设定为 6。为了消除由每次迭代中不一致提示引起的歧义的影响,每次迭代中获得的掩码被平均。最后,通过选择在所有迭代中最接近平均掩码的迭代结果来确定所选迭代
,其中 i ∈ 1,...,Iter。Iter 被设定为 6。为了消除由每次迭代中不一致提示引起的歧义的影响,每次迭代中获得的掩码被平均。最后,通过选择在所有迭代中最接近平均掩码的迭代结果来确定所选迭代  :
:

 就是 X 的最终分割结果。
就是 X 的最终分割结果。
实验

作者在伪装样本分割任务上的三个不同数据集上进行了实验,并分别与点监督和涂鸦 (scribble) 监督下进行训练后的方法进行了比较。GenSAM 不仅比基线方法相比取得了长足的进步,还再更好的监督信号和完全没有训练的情况下,取得了比弱监督方法类似甚至更好的性能。
作者还进一步进行了可视化实验,分析不同 iter 下的分割结果,首先是在 SAM 处理不佳的伪装样本分割任务上进行了评估:

此外,为了验证 GenSAM 的泛化性,还在阴影分割和透明物体分割上进行了可视化实验,均取得了出色的性能。

总结
总的来说,GenSAM 的提出使得像 SAM 这类提示分割方法能够摆脱对样本特定提示的依赖,这一能力为 SAM 的实际应用迈出了重要的一步。