













当大家都在研究大模型(LLM)参数规模达到百亿甚至千亿级别的同时,小巧且兼具高性能的小模型开始受到研究者的关注。
小模型在边缘设备上有着广泛的应用,如智能手机、物联网设备和嵌入式系统,这些边缘设备通常具有有限的计算能力和存储空间,它们无法有效地运行大型语言模型。因此,深入探究小型模型显得尤为重要。
接下来我们要介绍的这两项研究,可能满足你对小模型的需求。
TinyLlama-1.1B
来自新加坡科技设计大学(SUTD)的研究者近日推出了 TinyLlama,该语言模型的参数量为 11 亿,在大约 3 万亿个 token 上预训练而成。

- 论文地址:https://arxiv.org/pdf/2401.02385.pdf
- 项目地址:https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama 以 Llama 2 架构和分词器(tokenizer)为基础,这意味着 TinyLlama 可以在许多基于 Llama 的开源项目中即插即用。此外,TinyLlama 只有 11 亿的参数,体积小巧,适用于需要限制计算和内存占用的多种应用。
该研究表示仅需 16 块 A100-40G 的 GPU,便可在 90 天内完成 TinyLlama 的训练。

该项目从上线开始,持续受到关注,目前星标量达到 4.7K。

TinyLlama 模型架构详细信息如下所示:

训练细节如下:

研究者表示,这项研究旨在挖掘使用较大数据集训练较小模型的潜力。他们重点探究在用远大于扩展定律(scaling law)建议的 token 数量进行训练时,较小模型的行为表现。
具体来说,该研究使用大约 3 万亿个 token 训练具有 1.1B 个参数的 Transformer (仅解码器)模型。据了解,这是第一次尝试使用如此大量的数据来训练具有 1B 参数的模型。
尽管规模相对较小,但 TinyLlama 在一系列下游任务中表现相当出色,它的性能显著优于同等大小的现有开源语言模型。具体来说,TinyLlama 在各种下游任务中都超越了 OPT-1.3B 和 Pythia1.4B 。
此外,TinyLlama 还用到了各种优化方法,如 flash attention 2、FSDP( Fully Sharded Data Parallel )、 xFormers 等。
在这些技术的加持下,TinyLlama 训练吞吐量达到了每 A100-40G GPU 每秒 24000 个 token。例如,TinyLlama-1.1B 模型对于 300B token 仅需要 3,456 A100 GPU 小时,而 Pythia 为 4,830 小时,MPT 为 7,920 小时。这显示了该研究优化的有效性以及在大规模模型训练中节省大量时间和资源的潜力。
TinyLlama 实现了 24k tokens / 秒 / A100 的训练速度,这个速度好比用户可以在 8 个 A100 上用 32 小时训练一个具有 11 亿参数、220 亿 token 的 chinchilla-optimial 的模型。同时,这些优化也大大减少了显存占用,用户可以把 11 亿参数的模型塞入 40GB 的 GPU 里面还能同时维持 16k tokens 的 per-gpu batch size。只需要把 batch size 改小一点, 你就可以在 RTX 3090/4090 上面训练 TinyLlama。


实验中,该研究主要关注具有纯解码器架构的语言模型,包含大约 10 亿个参数。具体来说,该研究将 TinyLlama 与 OPT-1.3B、Pythia-1.0B 和 Pythia-1.4B 进行了比较。
TinyLlama 在常识推理任务上的性能如下所示,可以看出 TinyLlama 在许多任务上都优于基线,并获得了最高的平均分数。

此外,研究者在预训练期间跟踪了 TinyLlama 在常识推理基准上的准确率,如图 2 所示,TinyLlama 的性能随着计算资源的增加而提高,在大多数基准中超过了 Pythia-1.4B 的准确率。

表 3 表明,与现有模型相比,TinyLlama 表现出了更好的问题解决能力。

手快的网友已经开始整活了:运行效果出奇得好,在 GTX3060 上运行,能以 136 tok / 秒的速度运行。

「确实是快!」

小模型 LiteLlama
由于 TinyLlama 的发布,SLM(小型语言模型)开始引起广泛关注。德克萨斯工农大学的 Xiaotian Han 发布了 SLM-LiteLlama。它有 460M 参数,由 1T token 进行训练。这是对 Meta AI 的 LLaMa 2 的开源复刻版本,但模型规模显著缩小。
项目地址:https://huggingface.co/ahxt/LiteLlama-460M-1T
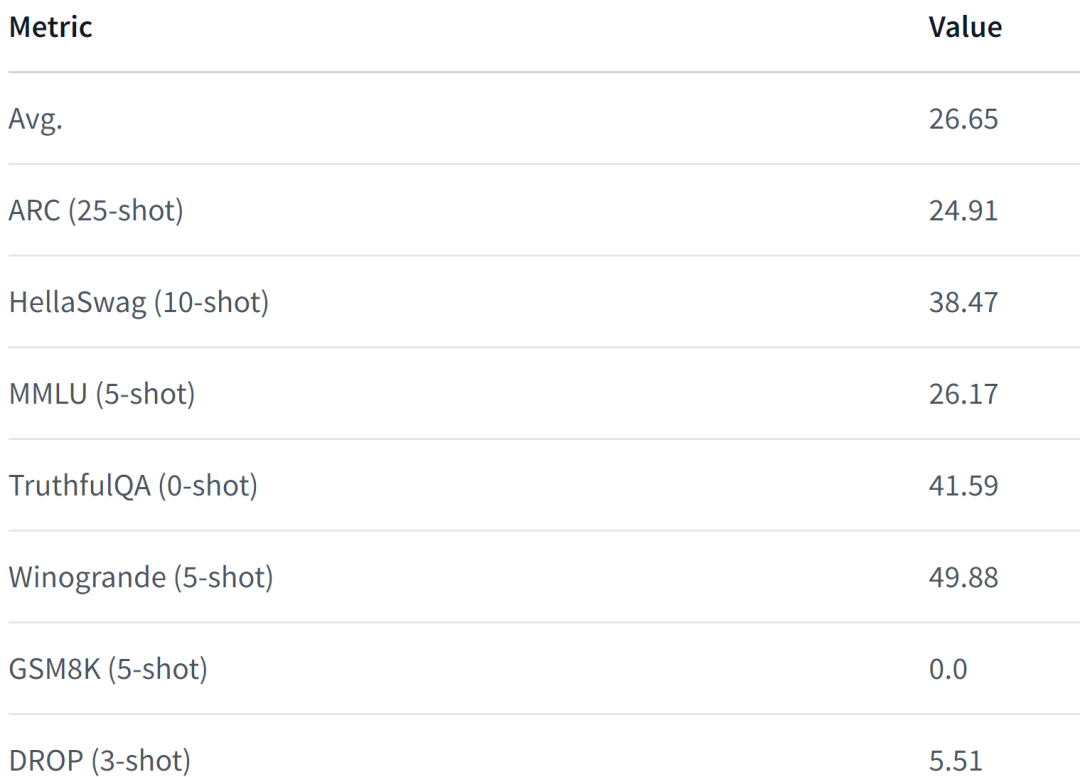
LiteLlama-460M-1T 在 RedPajama 数据集上进行训练,并使用 GPT2Tokenizer 对文本进行 token 化。作者在 MMLU 任务上对该模型进行评估,结果如下图所示,在参数量大幅减少的情况下,LiteLlama-460M-1T 仍能取得与其他模型相媲美或更好的成绩。

以下为该模型的性能表现,更详细内容请参阅:
https://huggingface.co/datasets/open-llm-leaderboard/details_ahxt__llama2_xs_460M_experimental
面对规模大幅缩小的 LiteLlama,有网友好奇,它是否能够在 4GB 的内存上运行。如果你也想知道,不如亲自试试看吧。





















