在开发中,我们经常会遇到这样的需求,将数据库中的图片导出到本地,再传给别人。
一、一般我会这样做:
- 通过接口或者定时任务的形式。
- 读取Oracle或者MySQL数据库。
- 通过FileOutputStream将Base64解密后的byte[]存储到本地。
- 遍历本地文件夹,将图片通过FTP上传到第三方服务器。

现场炸锅了!
实际的数据量非常大,据统计差不多有400G的图片需要导出。
现场人员的反馈是,已经跑了12个小时了,还在继续,不知道啥时候能导完。
停下来呢?之前的白导了,不停呢?不知道要等到啥时候才能导完。
这不行啊,速度太慢了,一个简单的任务,不能被这东西耗死吧?
@Value("${months}")
private String months;
@Value("${imgDir}")
private String imgDir;
@Resource
private UserDao userDao;
@Override
public void getUserInfoImg() {
try {
// 获取需要导出的月表
String[] monthArr = months.split(",");
for (int i = 0; i < monthArr.length; i++) {
// 获取月表中的图片
Map<String, Object> map = new HashMap<String, Object>();
String tableName = "USER_INFO_" + monthArr[i];
map.put("tableName", tableName);
map.put("status", 1);
List<UserInfo> userInfoList = userDao.getUserInfoImg(map);
if (userInfoList == null || userInfoList.size() == 0) {
return;
}
for (int j = 0; j < userInfoList.size(); j++) {
UserInfo user = userInfoList.get(j);
String userId = user.getUserId();
String userName = user.getUserName();
byte[] content = user.getImgContent;
// 下载图片到本地
FileUtil.dowmloadImage(imgDir + userId+"-"+userName+".png", content);
// 将下载好的图片,通过FTP上传给第三方
FileUtil.uploadByFtp(imgDir);
}
}
} catch (Exception e) {
serviceLogger.error("获取图片异常:", e);
}
}二、谁写的?赶紧加班优化,会追责吗?
经过1小时的深思熟虑,慢的原因可能有以下几点:
- 查询数据库
- 程序串行
- base64解密
- 图片落地
- FTP上传到服务器


使用 索引 + 异步 + 不解密 + 不落地 后,40G图片的导出上传,从 12+小时 优化到 15 分钟,你敢信?
差不多的代码,效率差距竟如此之大。
下面贴出导出图片不落地的关键代码。
@Resource
private UserAsyncService userAsyncService;
@Override
public void getUserInfoImg() {
try {
// 获取需要导出的月表
String[] monthArr = months.split(",");
for (int i = 0; i < monthArr.length; i++) {
userAsyncService.getUserInfoImgAsync(monthArr[i]);
}
} catch (Exception e) {
serviceLogger.error("获取图片异常:", e);
}
}@Value("${months}")
private String months;
@Resource
private UserDao userDao;
@Async("async-executor")
@Override
public void getUserInfoImgAsync(String month) {
try {
// 获取月表中的图片
Map<String, Object> map = new HashMap<String, Object>();
String tableName = "USER_INFO_" + month;
map.put("tableName", tableName);
map.put("status", 1);
List<UserInfo> userInfoList = userDao.getUserInfoImg(map);
if (userInfoList == null || userInfoList.size() == 0) {
return;
}
for (int i = 0; i < userInfoList.size(); i++) {
UserInfo user = userInfoList.get(i);
String userId = user.getUserId();
String userName = user.getUserName();
byte[] content = user.getImgContent;
// 不落地,直接通过FTP上传给第三方
FileUtil.uploadByFtp(content);
}
} catch (Exception e) {
serviceLogger.error("获取图片异常:", e);
}
}4、异步线程池工具类
- 在方法上添加@Async,表示此方法是异步方法。
- 在类上添加@Async,表示类中的所有方法都是异步方法。
- 使用此注解的类,必须是Spring管理的类。
- 需要在启动类或配置类中加入@EnableAsync注解,@Async才会生效。
在使用@Async时,如果不指定线程池的名称,也就是不自定义线程池,@Async是有默认线程池的,使用的是Spring默认的线程池SimpleAsyncTaskExecutor。
默认线程池的默认配置如下:
- 默认核心线程数:8。
- 最大线程数:Integet.MAX_VALUE。
- 队列使用LinkedBlockingQueue。
- 容量是:Integet.MAX_VALUE。
- 空闲线程保留时间:60s。
- 线程池拒绝策略:AbortPolicy。
从最大线程数可以看出,在并发情况下,会无限制的创建线程,我勒个吗啊。
spring:
task:
execution:
pool:
max-size: 10
core-size: 5
keep-alive: 3s
queue-capacity: 1000
thread-name-prefix: my-executor也可以自定义线程池,下面通过简单的代码来实现以下@Async自定义线程池。
@EnableAsync// 支持异步操作
@Configuration
public class AsyncTaskConfig {
/**
* com.google.guava中的线程池
* @return
*/
@Bean("my-executor")
public Executor firstExecutor() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("my-executor").build();
// 获取CPU的处理器数量
int curSystemThreads = Runtime.getRuntime().availableProcessors() * 2;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(curSystemThreads, 100,
200, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), threadFactory);
threadPool.allowsCoreThreadTimeOut();
return threadPool;
}
/**
* Spring线程池
* @return
*/
@Bean("async-executor")
public Executor asyncExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
// 核心线程数
taskExecutor.setCorePoolSize(24);
// 线程池维护线程的最大数量,只有在缓冲队列满了之后才会申请超过核心线程数的线程
taskExecutor.setMaxPoolSize(200);
// 缓存队列
taskExecutor.setQueueCapacity(50);
// 空闲时间,当超过了核心线程数之外的线程在空闲时间到达之后会被销毁
taskExecutor.setKeepAliveSeconds(200);
// 异步方法内部线程名称
taskExecutor.setThreadNamePrefix("async-executor-");
/**
* 当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略
* 通常有以下四种策略:
* ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
* ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
* ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
* ThreadPoolExecutor.CallerRunsPolicy:重试添加当前的任务,自动重复调用 execute() 方法,直到成功
*/
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.initialize();
return taskExecutor;
}
}三、告别劣质代码,优化从何入手?
我觉得优化有两个大方向:
- 业务优化
- 代码优化
1、业务优化
业务优化的影响力非常大,但它一般属于产品和项目经理的范畴,CRUD程序员很少能接触到。
比如上面说的图片导出上传需求,经过产品经理和项目经理的不懈努力,这个需求不做了,这优化力度,史无前例啊。
2、代码优化
- 数据库优化
- 复用优化
- 并行优化
- 算法优化
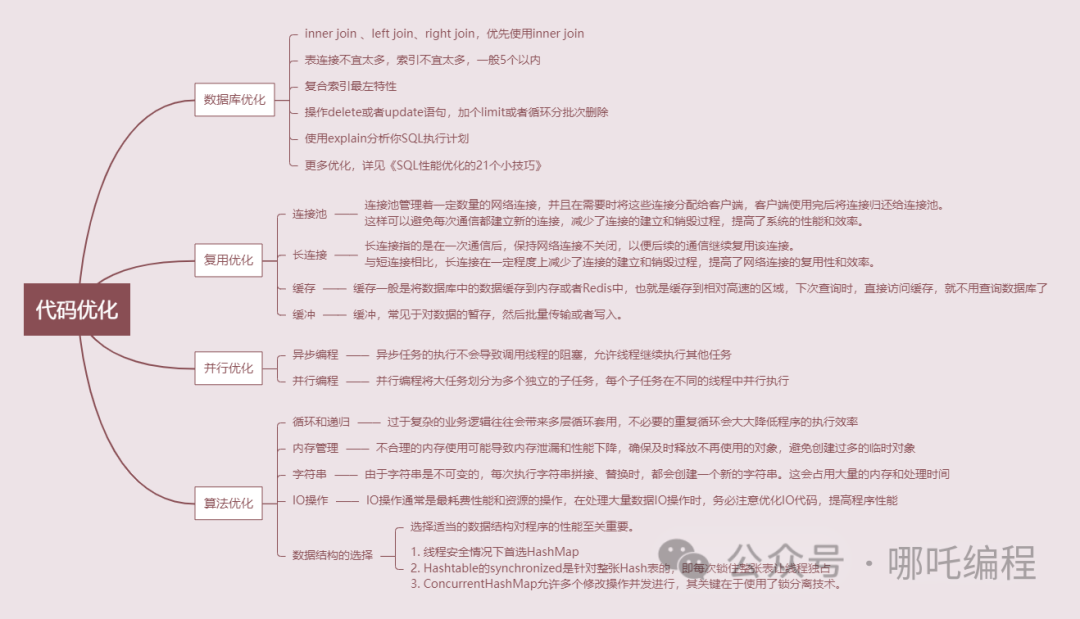
四、数据库优化
- inner join 、left join、right join,优先使用inner join
- 表连接不宜太多,索引不宜太多,一般5个以内
- 复合索引最左特性
- 操作delete或者update语句,加个limit或者循环分批次删除
- 使用explain分析你SQL执行计划
- ...
五、复用优化
写代码的时候,大家一般都会将重复性的代码提取出来,写成工具方法,在下次用的时候,就不用重新编码,直接调用就可以了。
这个就是复用。
数据库连接池、线程池、长连接也都是复用手段,这些对象的创建和销毁成本过高,复用之后,效率提升显著。
1、连接池
连接池是一种常见的优化网络连接复用性的方法。连接池管理着一定数量的网络连接,并且在需要时将这些连接分配给客户端,客户端使用完后将连接归还给连接池。这样可以避免每次通信都建立新的连接,减少了连接的建立和销毁过程,提高了系统的性能和效率。
在Java开发中,常用的连接池技术有Apache Commons Pool、Druid等。使用连接池时,需要合理设置连接池的大小,并根据实际情况进行调优。连接池的大小过小会导致连接不够用,而过大则会占用过多的系统资源。
2、长连接
长连接是另一种优化网络连接复用性的方法。长连接指的是在一次通信后,保持网络连接不关闭,以便后续的通信继续复用该连接。与短连接相比,长连接在一定程度上减少了连接的建立和销毁过程,提高了网络连接的复用性和效率。
在Java开发中,可以通过使用Socket编程实现长连接。客户端在建立连接后,通过设置Socket的Keep-Alive选项,使得连接保持活跃状态。这样可以避免频繁地建立新的连接,提高网络连接的复用性和效率。
3、缓存
缓存也是比较常用的复用,属于数据复用。
缓存一般是将数据库中的数据缓存到内存或者Redis中,也就是缓存到相对高速的区域,下次查询时,直接访问缓存,就不用查询数据库了,缓存主要针对的是读操作。
4、缓冲
缓冲常见于对数据的暂存,然后批量传输或者写入。多使用顺序方式,用来缓解不同设备之间频繁地、缓慢地随机写,缓冲主要针对的是写操作。
六、并行优化
1、异步编程
上面的优化方式就是异步优化,充分利用多核处理器的性能,将串行的程序改为并行,大大提高了程序的执行效率。
异步编程是一种编程模型,其中任务的执行不会阻塞当前线程的执行。通过将任务提交给其他线程或线程池来处理,当前线程可以继续执行其他操作,而不必等待任务完成。
2、异步编程的特点
- 非阻塞:异步任务的执行不会导致调用线程的阻塞,允许线程继续执行其他任务;
- 回调机制:异步任务通常会注册回调函数,当任务完成时,会调用相应的回调函数进行后续处理;
- 提高响应性:异步编程能够提高程序的响应性,尤其适用于处理IO密集型任务,如网络请求、数据库查询等;
Java 8引入了CompletableFuture类,可以方便地进行异步编程。
3、并行编程
并行编程是一种利用多个线程或处理器同时执行多个任务的编程模型。它将大任务划分为多个子任务,并发地执行这些子任务,从而加速整体任务的完成时间。
4、并行编程的特点
- 分布式任务:并行编程将大任务划分为多个独立的子任务,每个子任务在不同的线程中并行执行;
- 数据共享:并行编程需要考虑多个线程之间的数据共享和同步问题,以避免出现竞态条件和数据不一致的情况;
- 提高性能:并行编程能够充分利用多核处理器的计算能力,加速程序的执行速度。
5、并行编程如何实现?
- 多线程:Java提供了Thread类和Runnable接口,用于创建和管理多个线程。通过创建多个线程并发执行任务,可以实现并行编程。
- 线程池:Java的Executor框架提供了线程池的支持,可以方便地管理和调度多个线程。通过线程池,可以复用线程对象,减少线程创建和销毁的开销;
- 并发集合:Java提供了一系列的并发集合类,如ConcurrentHashMap、ConcurrentLinkedQueue等,用于在并行编程中实现线程安全的数据共享。
异步编程和并行编程是Java中处理任务并提高程序性能的两种重要方法。
异步编程通过非阻塞的方式处理任务,提高程序的响应性,并适用于IO密集型任务。
而并行编程则是通过多个线程或处理器并发执行任务,充分利用计算资源,加速程序的执行速度。
在Java中,可以使用CompletableFuture和回调接口实现异步编程,使用多线程、线程池和并发集合实现并行编程。通过合理地运用异步和并行编程,我们可以在Java中高效地处理任务和提升程序的性能。
6、代码示例
public static void main(String[] args) {
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
// 使用线程池创建CompletableFuture对象
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// 一些不为人知的操作
return "result"; // 返回结果
}, executor);
// 使用CompletableFuture对象执行任务
CompletableFuture<String> result = future.thenApply(result -> {
// 一些不为人知的操作
return "result"; // 返回结果
});
// 处理任务结果
String finalResult = result.join();
// 关闭线程池
executor.shutdown();
}7、Java 8 parallel
(1)parallel()是什么
Stream.parallel() 方法是 Java 8 中 Stream API 提供的一种并行处理方式。在处理大量数据或者耗时操作时,使用 Stream.parallel() 方法可以充分利用多核 CPU 的优势,提高程序的性能。
Stream.parallel() 方法是将串行流转化为并行流的方法。通过该方法可以将大量数据划分为多个子任务交由多个线程并行处理,最终将各个子任务的计算结果合并得到最终结果。使用 Stream.parallel() 可以简化多线程编程,减少开发难度。
需要注意的是,并行处理可能会引入线程安全等问题,需要根据具体情况进行选择。
(2)举一个简单的demo
定义一个list,然后通过parallel() 方法将集合转化为并行流,对每个元素进行i++,最后通过 collect(Collectors.toList()) 方法将结果转化为 List 集合。
使用并行处理可以充分利用多核 CPU 的优势,加快处理速度。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
System.out.println(list);
List<Integer> result = list.stream().parallel().map(i -> i++).collect(Collectors.toList());
System.out.println(result);
}
}我勒个去,什么情况?

(3)parallel()的优缺点
① 优点:
- 充分利用多核 CPU 的优势,提高程序的性能;
- 可以简化多线程编程,减少开发难度。
② 缺点:
- 并行处理可能会引入线程安全等问题,需要根据具体情况进行选择;
- 并行处理需要付出额外的开销,例如线程池的创建和销毁、线程切换等,对于小数据量和简单计算而言,串行处理可能更快。
(4)何时使用parallel()?
在实际开发中,应该根据数据量、计算复杂度、硬件等因素综合考虑。
比如:
- 数据量较大,有1万个元素;
- 计算复杂度过大,需要对每个元素进行复杂的计算;
- 硬件够硬,比如多核CPU。
七、算法优化
在上面的例子中,避免base64解密,就应该归类于算法优化。
程序就是由数据结构和算法组成,一个优质的算法可以显著提高程序的执行效率,从而减少运行时间和资源消耗。相比之下,一个低效的算法就可能导致运行非常缓慢,并占用大量系统资源。
很多问题都可以通过算法优化来解决,比如:
1、循环和递归
循环和递归是Java编程中常见的操作,然而,过于复杂的业务逻辑往往会带来多层循环套用,不必要的重复循环会大大降低程序的执行效率。
递归是一种函数自我调用的技术,类似于循环,虽然递归可以解决很多问题,但是,递归的效率有待提高。
2、内存管理
Java自带垃圾收集器,开发人员不用手动释放内存。
但是,不合理的内存使用可能导致内存泄漏和性能下降,确保及时释放不再使用的对象,避免创建过多的临时对象。
3、字符串
我觉得字符串是Java编程中使用频率最高的技术,很多程序员恨不得把所有的变量都定义成字符串。
然而,由于字符串是不可变的,每次执行字符串拼接、替换时,都会创建一个新的字符串。这会占用大量的内存和处理时间。
使用StringBuilder来处理字符串的拼接可以显著的提高性能。
4、IO操作
IO操作通常是最耗费性能和资源的操作。在处理大量数据IO操作时,务必注意优化IO代码,提高程序性能,比如上面提高的图片不落地就是彻底解决IO问题。
5、数据结构的选择
选择适当的数据结构对程序的性能至关重要。
比如Java世界中用的第二多的Map,比较常用的有HashMap、HashTable、ConcurrentHashMap。
- HashMap,底层数组+链表实现,可以存储null键和null值,线程不安全;
- HashTable,底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化;
- ConcurrentHashMap,底层采用分段的数组+链表实现,线程安全,通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。