













为了实现应用高并发和高可用,企业通常会选择将应用部署在多个地域的多个集群,甚至多云、混合云环境中。在这种情况下,如何在多个集群中部署和管理应用,成为了一个挑战,当然多集群方案也逐步成为了企业应用部署的最佳选择了。同样对多云、混合云、虚拟机等异构基础设施的服务治理也是 Istio 重点支持的场景之一,Istio 从 v1.0 版本开始支持一些多集群功能,并在之后的版本中添加了新功能。
多集群服务网格的好处是所有服务对客户端看起来都一样,不管工作负载实际上运行在哪里,无论是部署在单个还是多个网格中,它对应用程序都是透明的。要实现此行为,需要使用单个逻辑控制平面管理所有服务。但是,单个逻辑控制平面不一定需要是单个物理 Istio 控制平面。
多集群模型
Istio 多集群网格有多种模型,在网络拓扑上分为扁平网络和非扁平网络,在控制面上分为单一控制平面和多控制平面。
- 扁平网络:所有集群都在同一个网络中,可以直接访问到其他集群的服务,不需要通过网关。
- 优点: 跨集群访问不经过东西向网关,延迟低
- 缺点:组网较为复杂,Service、Pod 网段不能重叠,借助 VPN 等技术将所有集群的 Pod 网络打通,需要考虑网络安全问题
- 非扁平网络:集群之间的网络是隔离的,需要通过网关访问其他集群的服务。
优点:不同集群的网络是互相隔离的,安全性更高,不需要打通不同集群的容器网络,不用提前规划集群的网段
缺点:跨集群访问依赖东西向网关,延迟高。东西向网关工作模式是 TLS AUTO_PASSTHROUGH,不支持 HTTP 路由策略。
单控制面:所有集群共用一个控制平面,所有集群的配置都在同一个控制平面中。
优点:所有集群的配置都在同一个控制平面中,集群之间的配置可以共享,部署运维更简单
缺点:控制平面的性能和可用性会受到影响,不适合大规模集群
多控制面:每个集群都有一个独立的控制平面,集群之间的配置不共享。
优点:控制平面的性能和可用性不会受到影响,适合大规模集群
缺点:集群之间的配置不共享,部署运维较为复杂
总体来说 Istio 目前支持 4 种多集群模型:扁平网络单控制面、扁平网络多控制面、非扁平网络单控制面、非扁平网络多控制面。其中扁平网络单控制面是最简单的模型,非扁平网络多控制面是最复杂的模型。
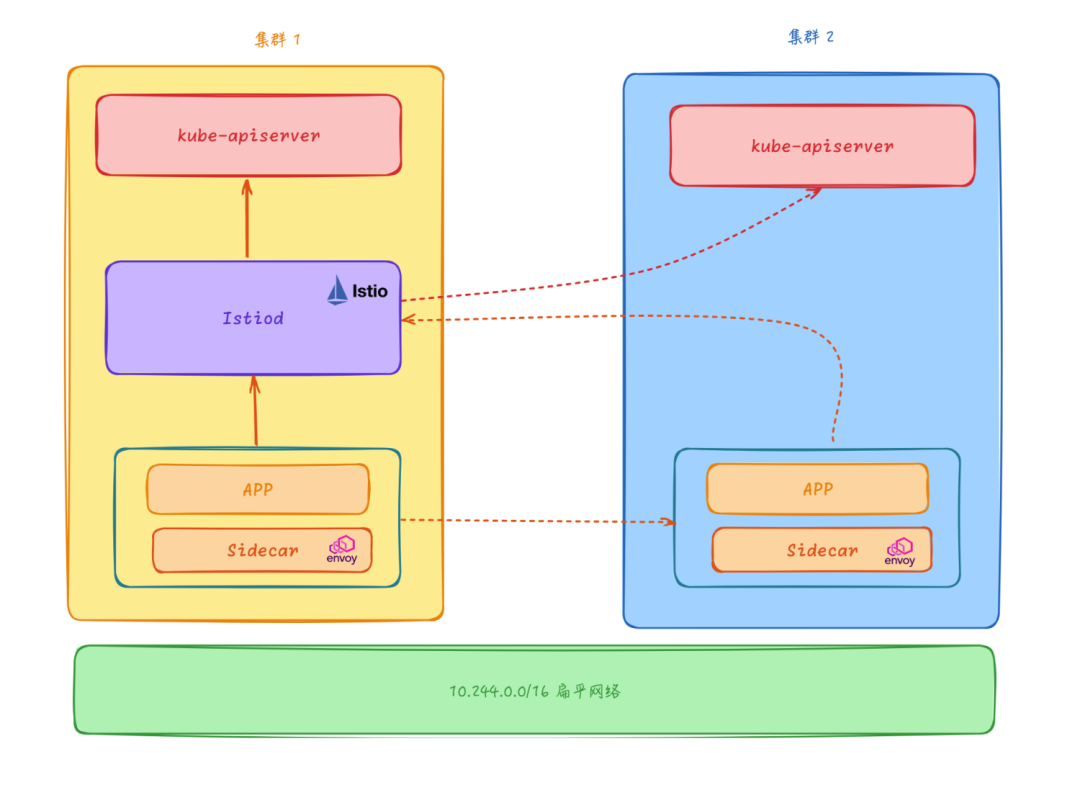
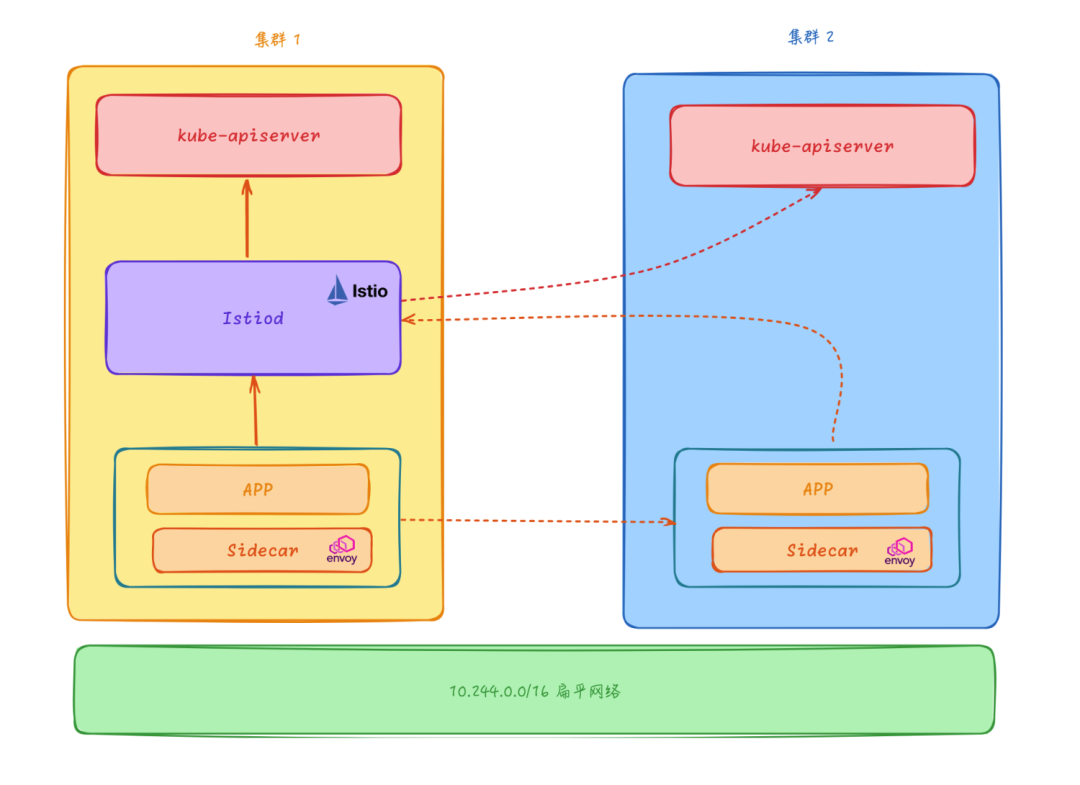
扁平网络单控制面
该模型下只需要将 Istio 控制面组件部署在主集群中,然后可以通过这个控制面来管理所有集群的 Service 和 Endpoint,其他的 Istio 相关的 API 比如 VirtualService、DestinationRule 等也只需要在主集群中配置即可,其他集群不需要部署 Istio 控制面组件。
控制平面的 Istiod 核心组件负责连接所有集群的 kube-apiserver,获取每个集群的 Service、Endpoint、Pod 等信息,所有集群的 Sidecar 均连接到这个中心控制面,由这个中心控制面负责所有的 Envoy Sidecar 的配置生成和分发。
 扁平网络单控制面
扁平网络单控制面
多集群扁平网络模型和单一集群的服务网格在访问方式上几乎没什么区别,但是需要注意不同集群的 Service IP 和 Pod 的 IP 不能重叠,否则会导致集群之间的服务发现出现问题,这也是扁平网络模型的一个缺点,需要提前规划好集群的网段。
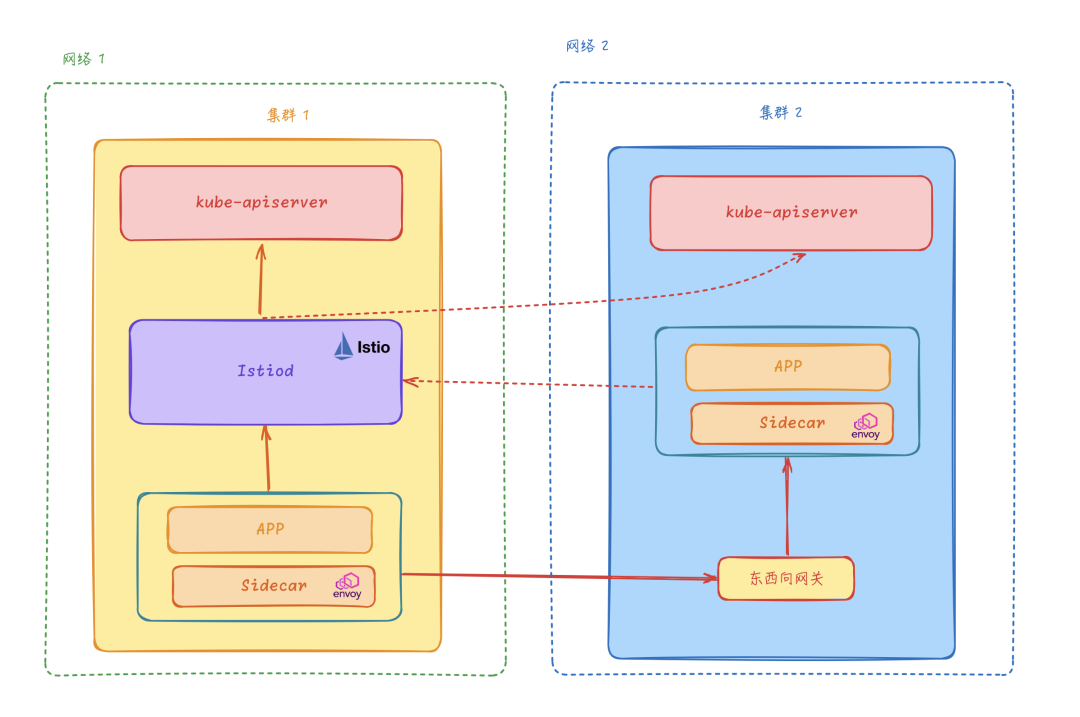
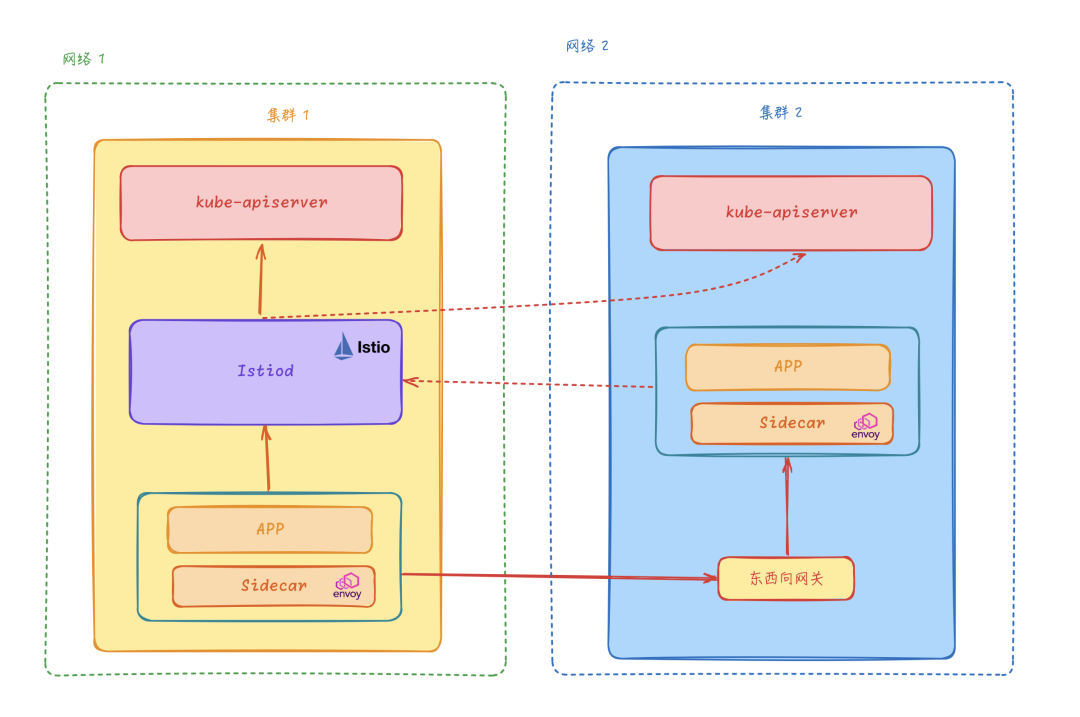
非扁平网络单控制面
在很多场景下我们多个集群并不在同一个网络中,为满足这个场景 Istio 又提出了一种更加灵活的网络方案,即非扁平网络。在非扁平网络中,我们可以通过配置东西向网关来转发跨集群的访问流量。和扁平网络的方案一样,Istio 控制面一样需要连接所有 Kubernetes 集群的 kube-apiserver,订阅所有集群的 Service、Endpoint 等资源,所有集群的 Envoy Sidecar 都被连接到同一控制平面。
 非扁平网络单控制面
非扁平网络单控制面
非扁平网络单控制面模型在同一集群内部的服务访问和单集群模型还是一样的,但是如果有一个目标服务实例运行在另外一个集群中,那么这个时候就需要目标集群的东西向网关来转发跨集群的服务请求。
扁平网络多控制面
多控制面模型是每个集群都使用自己的 Istio 控制面,但是每个 Istio 控制面仍然要感知所有集群中的 Service、Endpoint 等资源,并控制集群内或者跨集群的服务间访问。对于多控制面模型来说,相同的 Istio 配置需要被复制下发到多个集群中,否则不同集群的 Sidecar 订阅到的 xDS 配置可能会存在不一致,导致不同集群的服务访问行为不一致的情况。多控制面模型还有以下的一些特点:
- 共享根 CA:为了支持跨集群的 mTLS 通信,多控制面模型要求每个集群的控制面 Istiod 都是有相同 CA 机构颁发的中间 CA 证书,供 Citadel 签发证书使用,以支持跨集群的 TLS 双向认证通信。
- Sidecar 与本集群的 Istiod 控制面连接订阅 xDS,xDS 通信的可靠性相对更高。
- 与单控制面模型相比,多控制面模型的控制面性能和可用性更好,适合大规模集群。
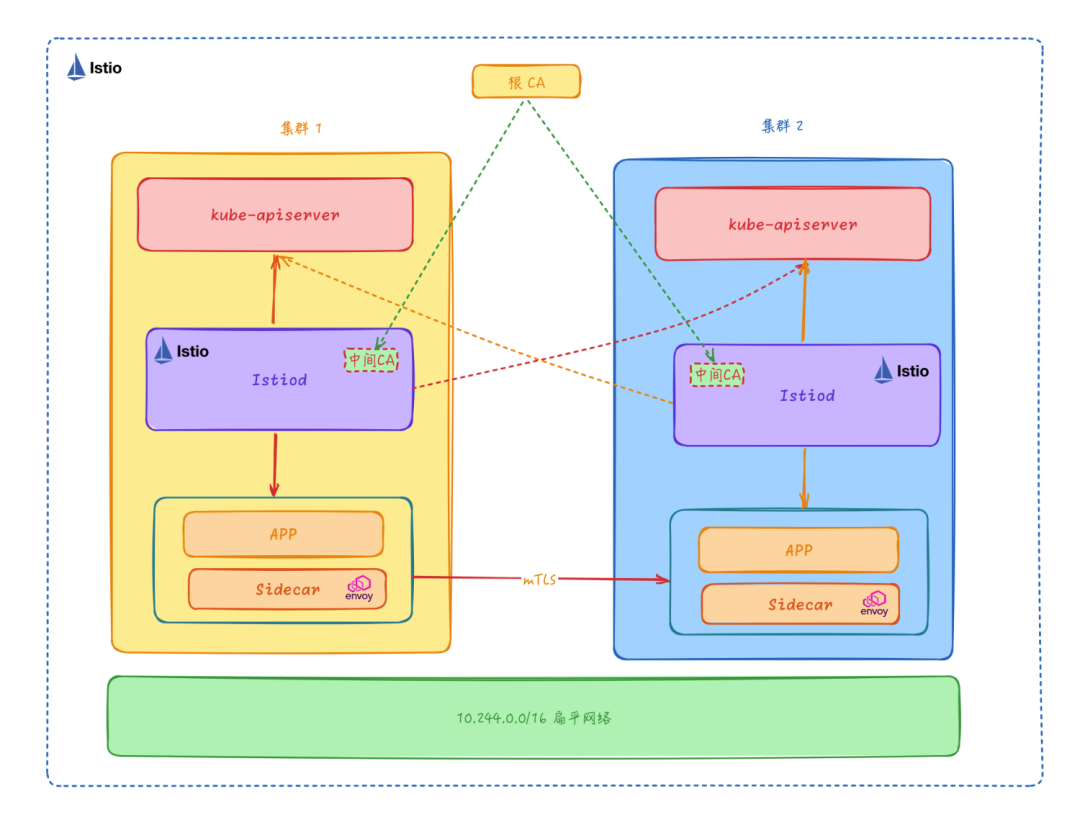
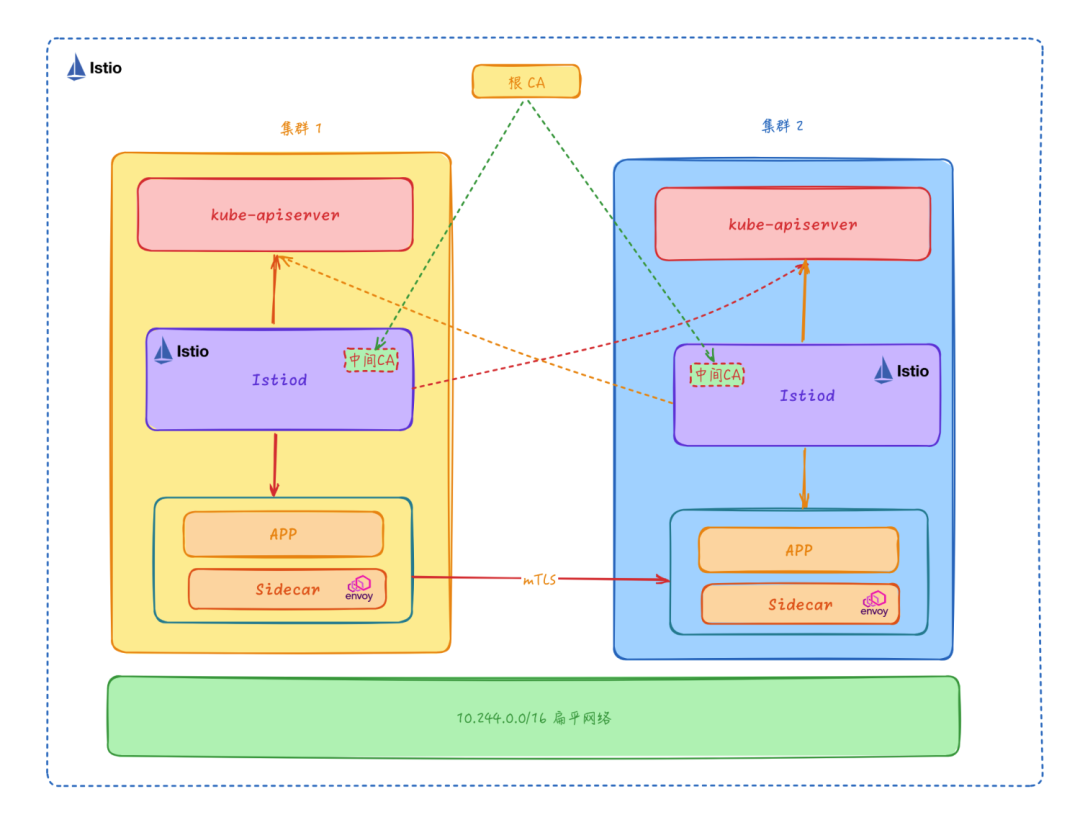 扁平网络多控制面
扁平网络多控制面
这种模型适用于控制面可用性和控制面时延要求较高的场景,但是由于每个集群都需要部署 Istio 控制面,所以部署和运维的成本也会相应增加,同一配置规则需要重复创建多份,存在资源冗余的问题。
非扁平网络多控制面
非扁平网络多控制面模型与扁平网络多控制面模型类似,它们在控制面方面完全相同,每个 Kubernetes 集群分别部署独立的 Istio 控制面,并且每个控制面都监听所有 Kubernetes 集群的 Service、Endpoint 等资源。
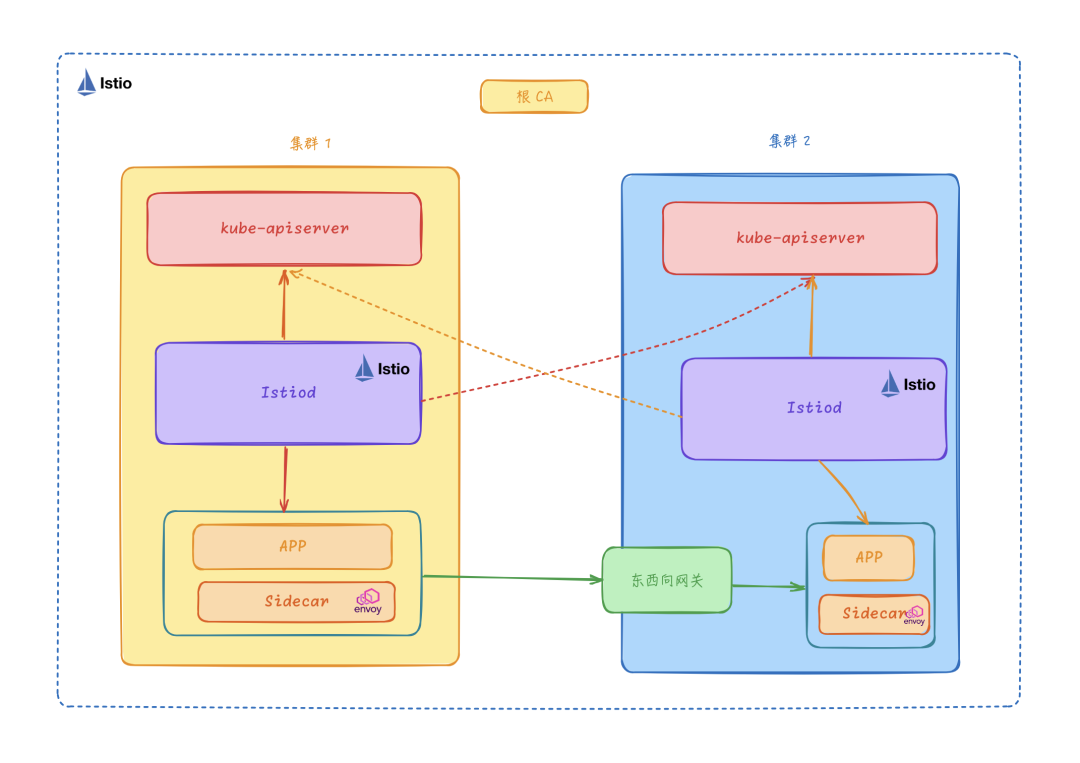
非扁平网络多控制面
因为是非扁平网络模型,所以不同的集群不需要三层打通,跨集群的服务访问通过 Istio 的东西向网关来转发。每个集群的 Pod 地址范围与服务地址可以与其他集群重叠,不同的集群之间互不干扰。另外集群的 Sidecar 只连接到本集群的 Istio 控制面,通信效率更高。
多集群安装
在选择 Istio 多集群模型时,当然需要结合自己的实际场景来决定。如果集群之间的网络是扁平的,那么可以选择扁平网络模型,如果集群之间的网络是隔离的,那么可以选择非扁平网络模型。如果集群规模较小,那么可以选择单控制面模型,如果集群规模较大,那么可以选择多控制面模型。
接下来我们这里选择跨网络多主架构的模型来进行安装说明,即非扁平网络多控制面模型。这里我们将在 cluster1 和 cluster2 两个集群上,分别安装 Istio 控制平面, 且将两者均设置为主集群(primary cluster)。 集群 cluster1 在 network1 网络上,而集群 cluster2 在 network2 网络上,这意味着这些跨集群边界的 Pod 之间,网络不能直接连通。
为了方便测试,我们这里使用 kind 来测试多集群,先保证已经安装了 Docker 和 KinD:
$ docker version
Client:
Cloud integration: v1.0.29
Version: 20.10.21
API version: 1.41
Go version: go1.18.7
Git commit: baeda1f
Built: Tue Oct 25 18:01:18 2022
OS/Arch: darwin/arm64
Context: orbstack
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 24.0.7
API version: 1.43 (minimum version 1.12)
Go version: go1.20.10
Git commit: 311b9ff
Built: Thu Oct 26 09:08:17 2023
OS/Arch: linux/arm64
Experimental: false
containerd:
Version: v1.7.7
GitCommit: 8c087663b0233f6e6e2f4515cee61d49f14746a8
runc:
Version: 1.1.9
GitCommit: 82f18fe0e44a59034f3e1f45e475fa5636e539aa
docker-init:
Version: 0.19.0
GitCommit: de40ad0
$ kind version
kind v0.20.0 go1.20.4 darwin/arm64这里我们将安装多集群的相关脚本放在了 github.com/cnych/multi-cluster-istio-kind 仓库中,先将这个仓库克隆到本地,然后进入到 multi-cluster-istio-kind 目录,在 kind-create 目录下面是我们定义了一个 create-cluster.sh 脚本,用于创建多个 K8s 集群:
# This script handles the creation of multiple clusters using kind and the
# ability to create and configure an insecure container registry.
set -o xtrace
set -o errexit
set -o nounset
set -o pipefail
# shellcheck source=util.sh
NUM_CLUSTERS="${NUM_CLUSTERS:-2}"
KIND_IMAGE="${KIND_IMAGE:-}"
KIND_TAG="${KIND_TAG:-v1.27.3@sha256:3966ac761ae0136263ffdb6cfd4db23ef8a83cba8a463690e98317add2c9ba72}"
OS="$(uname)"
function create-clusters() {
local num_clusters=${1}
local image_arg=""
if [[ "${KIND_IMAGE}" ]]; then
image_arg="--image=${KIND_IMAGE}"
elif [[ "${KIND_TAG}" ]]; then
image_arg="--image=kindest/node:${KIND_TAG}"
fi
for i in $(seq "${num_clusters}"); do
kind create cluster --name "cluster${i}" "${image_arg}"
fixup-cluster "${i}"
echo
done
}
function fixup-cluster() {
local i=${1} # cluster num
if [ "$OS" != "Darwin" ];then
# Set container IP address as kube API endpoint in order for clusters to reach kube API servers in other clusters.
local docker_ip
docker_ip=$(docker inspect --format='{{range .NetworkSettingkc s.Networks}}{{.IPAddress}}{{end}}' "cluster${i}-control-plane")
kubectl config set-cluster "kind-cluster${i}" --server="https://${docker_ip}:6443"
fi
# Simplify context name
kubectl config rename-context "kind-cluster${i}" "cluster${i}"
}
echo "Creating ${NUM_CLUSTERS} clusters"
create-clusters "${NUM_CLUSTERS}"
kubectl config use-context cluster1
echo "Kind CIDR is $(docker network inspect -f '{{$map := index .IPAM.Config 0}}{{index $map "Subnet"}}' kind)"
echo "Complete"上面的脚本默认会创建两个 v1.27.3 版本的 K8s 集群,这里需要注意的是我们安装的每个集群的 APIServer 必须能被网格中其他集群访问,很多云服务商通过网络负载均衡器(NLB)开放 APIServer 的公网访问。如果 APIServer 不能被直接访问,则需要调整安装流程以放开访问,我们这里容器的 IP 地址设置为 kube API 端点地址,以便集群可以访问其他集群中的 kube API 服务器。
直接运行上面的脚本即可创建两个 K8s 集群:
cd kind-create
bash ./create-cluster.sh可以安装一个 kubectx 工具来方便切换集群。
另外 istio 创建的入口和出口网关都需要外部 IP,我们可以使用 MetalLB 来进行分配。
# install-metallb.sh
#!/usr/bin/env bash
set -o xtrace
set -o errexit
set -o nounset
set -o pipefail
NUM_CLUSTERS="${NUM_CLUSTERS:-2}"
for i in $(seq "${NUM_CLUSTERS}"); do
echo "Starting metallb deployment in cluster${i}"
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/master/manifests/namespace.yaml --context "cluster${i}"
kubectl create secret generic -n metallb-system memberlist --from-literal=secretkey="$(openssl rand -base64 128)" --context "cluster${i}"
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/master/manifests/metallb.yaml --context "cluster${i}"
kubectl apply -f ./metallb-configmap-${i}.yaml --context "cluster${i}"
echo "----"
donekind 集群控制的 IP 地址范围可以通过 docker network inspect -f '{{$map := index .IPAM.Config 0}}{{index $map "Subnet"}}' kind 获取。比如我们这里上述命令的输出是 192.168.247.0/24,我们已经创建了 metallb-configmap-1.yaml 和 metallb-configmap-2.yaml,这会将 192.168.247.225-192.168.247.250 和 192.168.247.200-192.168.247.224 IP 范围分别分配给 cluster1 和 cluster2。
应用上面的脚本安装 metallb:
cd kind-create
bash ./install-metallb.sh多集群服务网格部署要求我们在网格中的所有集群之间建立信任,我们需要使用一个公共的根 CA 来为每个集群生成中间证书,在 kind-create 目录中同样我们定义了一个安装 CA 的脚本:
cd kind-create
bash ./install-cacerts.sh在 tools/certs 目录下面包含两个用于生成新根证书、中间证书和工作负载证书的 Makefile:
- Makefile.k8s.mk:基于 k8s 集群中的 root-ca 创建证书。默认 kubeconfig 中的当前上下文用于访问集群。
- Makefile.selfsigned.mk:根据生成的自签名根创建证书。
执行上面的脚本后会生成一个公共的根 CA 证书,然后会使用这个证书为 cluster1 和 cluster2 集群生成中间证书,而且在这个脚本中,我们将 istio 命名空间添加了一个 topology.istio.io/network=network${i} 标签。
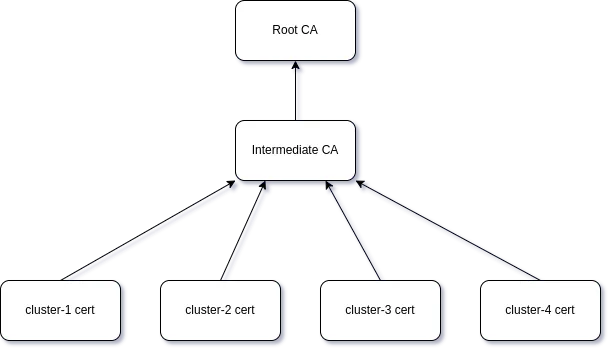
Root CA
接下来就可以安装 Istio 集群了,在 istio-create 目录下面我们定义了一个 install-istio.sh 脚本,用于安装 Istio 集群:
#!/usr/bin/env bash
set -o xtrace
set -o errexit
set -o nounset
set -o pipefail
OS="$(uname)"
NUM_CLUSTERS="${NUM_CLUSTERS:-2}"
for i in $(seq "${NUM_CLUSTERS}"); do
echo "Starting istio deployment in cluster${i}"
kubectl --cnotallow="cluster${i}" get namespace istio-system && \
kubectl --cnotallow="cluster${i}" label namespace istio-system topology.istio.io/network="network${i}"
sed -e "s/{i}/${i}/" cluster.yaml > "cluster${i}.yaml"
istioctl install --force --cnotallow="cluster${i}" -f "cluster${i}.yaml"
echo
done其中有一个比较重要的是 cluster.yaml 文件,这个文件定义了 Istio 的安装配置,由于我们这里使用的是非扁平网络多控制面模型,所以我们需要在这个文件中定义 network 和 clusterName 用来标识不同的 Istio 集群,这里我们将 network 设置为 network${i},将 clusterName 设置为 cluster${i}。
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
global:
meshID: mesh{i}
multiCluster:
clusterName: cluster{i}
network: network{i}直接运行上面的脚本即可在两个 Kubernetes 集群中分别安装 Istio 集群:
cd istio-create
bash ./install-istio.yaml在安装过程需要手动确认是否安装 Istio,输入 y 即可。默认安装完成后会有 istiod、istio-ingressgateway 以及 istio-eastwestgateway 三个组件:
# 两个 kubernetes 集群都有这三个组件
$ kubectl get pods -n istio-system
NAME READY STATUS RESTARTS AGE
istio-eastwestgateway-66758cf789-dztsz 1/1 Running 0 23m
istio-ingressgateway-6d4bc4cc8f-ppdjx 1/1 Running 0 2m6s
istiod-79d66c57dd-gmx76 1/1 Running 0 2m8s
$ kubectl get svc -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-eastwestgateway LoadBalancer 10.96.251.150 192.168.247.226 15021:31106/TCP,15443:30675/TCP,15012:30483/TCP,15017:30517/TCP 24m
istio-ingressgateway LoadBalancer 10.96.111.72 192.168.247.225 15021:30540/TCP,80:31137/TCP,443:32705/TCP 47m
istiod ClusterIP 10.96.45.118 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 47m由于我们在 Kubernetes 集群中安装了 metallb,所以我们可以看到 istio-ingressgateway 服务的 EXTERNAL-IP 被分配了一个 IP 地址,这个地址是我们在 metallb-configmap-1.yaml 和 metallb-configmap-2.yaml 中定义的范围内。
前面我们提到过非扁平网络多控制面模型的场景下需要一个专用于东西向流量的网关,所有配置都依赖于专用于东西向流量的单独网关部署。这样做是为了避免东西向流量淹没默认的南北向入口网关。上面的脚本中同样也包括生成东西向网关的配置。
到这里 istio 集群和专用于东西向流量的网关都安装成功了。因为集群位于不同的网络中,所以我们需要在两个集群东西向网关上开放所有服务(*.local)。虽然此网关在互联网上是公开的,但它背后的服务只能被拥有可信 mTLS 证书、工作负载 ID 的服务访问, 就像它们处于同一网络一样。执行下面的命令在两个集群中暴露服务:
NUM_CLUSTERS="${NUM_CLUSTERS:-2}"
for i in $(seq "${NUM_CLUSTERS}"); do
echo "Expose services in cluster${i}"
kubectl --cnotallow="cluster${i}" apply -n istio-system -f samples/multicluster/expose-services.yaml
echo
done上面的命令其实就是在两个集群中创建如下所示的 Gateway 对象,用来暴露所有的服务:
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway # 专用于东西向流量的网关
servers:
- port:
number: 15443 # 已经声明了
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH # 东西向网关工作模式是 TLS AUTO_PASSTHROUGH,不支持 HTTP 路由策略
hosts:
- "*.local" # 暴露所有的服务最后我们还需要配置每个 istiod 来 watch 其他集群的 APIServer,我们使用 K8s 集群的凭据来创建 Secret 对象,以允许 Istio 访问其他 (n-1) 个远程 kubernetes apiserver。
cd istio-setup
bash ./enable-endpoint-discovery.sh在上面的脚本中我们将使用 istioctl create-remote-secret 命令来使用 K8s 集群的凭据来创建 Secret 对象,以允许 Istio 访问远程的 Kubernetes apiservers。
docker_ip=$(docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' "cluster${i}-control-plane")
istioctl create-remote-secret \
--cnotallow="cluster${i}" \
--server="https://${docker_ip}:6443" \
--name="cluster${i}" | \
kubectl apply --validate=false --cnotallow="cluster${j}" -f -这样 cluster1 和 cluster2 均可以监测两个集群 API Server 的服务端点了,我们的非扁平网络多控制面模型的 Istio 集群就安装完成了。
多集群应用测试
接下来我们可以部署一个简单的示例来验证下我们的多集群服务网格是否安装成功了。
这里我们将在所有集群中创建名为 sample 的命名空间,然后在所有集群中创建 helloworld 的 Service,并在每个集群中交替部署 helloworld 的 v1 和 v2 两个版本。
cd testing
bash ./deploy-app.sh部署完成后在 cluster1 集群中将运行 v2 版本,在 cluster2 集群中将运行 v1 版本:
# cluster1 集群
$ kubectl get pods -n sample
NAME READY STATUS RESTARTS AGE
helloworld-v2-79d5467d55-7k2hv 2/2 Running 0 3m57s
# cluster2 集群
$ kubectl get pods -n sample
NAME READY STATUS RESTARTS AGE
helloworld-v1-b6c45f55-8lw2j 2/2 Running 0 4m25s此外我们还在 sample 命名空间下面部署了一个用于测试的 sleep 应用,我们可以到 sleep Pod 中进行测试,如下的命令:
while true; do curl -s "helloworld.sample:5000/hello"; done正常会输出如下所示的内容:
Hello version: v1, instance: helloworld-v1-776f57d5f6-znwk5
Hello version: v2, instance: helloworld-v2-54df5f84b-qmg8t..
...同样我们换另外一个集群的 sleep Pod 重复上面的命令,重复几次这个请求,验证 HelloWorld 的版本在 v1 和 v2 之间切换:
Hello version: v1, instance: helloworld-v1-776f57d5f6-znwk5
Hello version: v2, instance: helloworld-v2-54df5f84b-qmg8t..
...到这里我们就成功在多集群环境中安装、并验证了 Istio!
地域负载均衡
接下来我们来了解下如何在 Istio 中配置地域负载均衡。
一个地域定义了 workload instance 在网格中的地理位置。这三个元素定义了一个地域:
- Region:代表较大的地理区域,例如 us-east,一个地区通常包含许多可用区。在 Kubernetes 中,标签 topology.kubernetes.io/region 决定了节点所在的地区。
- Zone:区域内的一组计算资源。通过在地区内的多个区域中运行服务,可以在地区内的区域之间进行故障转移,同时保持最终用户的数据地域性。在 Kubernetes 中,标签 topology.kubernetes.io/zone 决定了节点所在的区域。
- Sub-zone:分区,允许管理员进一步细分区域,以实现更细粒度的控制。Kubernetes 中不存在分区的概念,在 Istio 中引入了自定义节点标签 topology.istio.io/subzone 来定义分区。
如果你使用托管的 Kubernetes 服务,则云提供商会为你配置地区和区域标签。如果你正在运行自己的 Kubernetes 集群,则需要将这些标签添加到自己的节点上。比如前面我们使用 Kind 搭建的两个集群已经添加上了相应的标签:
$ kubectl get nodes --show-labels --context cluster1
NAME STATUS ROLES AGE VERSION LABELS
cluster1-control-plane Ready control-plane 38h v1.27.3 beta.kubernetes.io/arch=arm64,beta.kubernetes.io/os=linux,kubernetes.io/arch=arm64,kubernetes.io/hostname=cluster1-control-plane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=,topology.kubernetes.io/reginotallow=region1,topology.kubernetes.io/znotallow=zone1
$ kubectl get nodes --show-labels --context cluster2
NAME STATUS ROLES AGE VERSION LABELS
cluster2-control-plane Ready control-plane 38h v1.27.3 beta.kubernetes.io/arch=arm64,beta.kubernetes.io/os=linux,kubernetes.io/arch=arm64,kubernetes.io/hostname=cluster2-control-plane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=,topology.kubernetes.io/reginotallow=region2,topology.kubernetes.io/znotallow=zone2地域是分层的,按匹配顺序排列:Region -> Zone -> Sub-zone。这意味着,在 foo 地区的 bar 区域中运行 Pod 不会被视为在 baz 地区的 bar 区域中运行的 Pod。
配置权重分布
现在我们有两个 Istio 集群,接下来我们来配置下权重分布。权重分布是一种流量管理策略,它允许您将流量分配到不同的地区。这里我们配置 region1 -> zone1 和 region1 -> zone2 两个地区的权重分别为 80% 和 20%。
首先为 helloworld 服务创建一个专用的 Gateway 和 VirtualService 对象:
# helloworld-gateway.yaml
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: helloworld-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: helloworld
spec:
hosts:
- "*"
gateways:
- helloworld-gateway
http:
- match:
- uri:
exact: /hello
route:
- destination:
host: helloworld
port:
number: 5000在两个集群中都需要部署这个 Gateway 和 VirtualService 对象:
kubectl apply -f samples/helloworld/helloworld-gateway.yaml -n sample --context cluster1
kubectl apply -f samples/helloworld/helloworld-gateway.yaml -n sample --context cluster2接下来我们就可以分别通过 cluster1 和 cluster2 集群的 Gateway 来访问 helloworld 服务了:
# 集群 1
$ kubectl get svc istio-ingressgateway -n istio-system --context cluster1
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.96.199.106 192.168.247.225 15021:31651/TCP,80:32531/TCP,443:32631/TCP 38h
$ while true; do curl -s "http://192.168.247.225/hello"; done
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
# 集群 2
$ kubectl get svc istio-ingressgateway -n istio-system --context cluster2
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.96.149.60 192.168.247.175 15021:31057/TCP,80:30392/TCP,443:32610/TCP 38h
$ while true; do curl -s "http://192.168.247.175/hello"; done
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69从上面结果可以看出来无论我们访问哪个集群的 Gateway,都会将流量负载到两个集群中的 helloworld 服务上,当然如果是在线上环境,我们在最前面可以加上一个统一的 LB 入口,这样就可以将流量负载到不同地区/区域的集群中了。
如果我们想对流量进行更精细的控制,比如我们想将 region1 -> zone1 和 region1 -> zone2 两个地区的权重分别为 80% 和 20%,那么我们可以使用 DestinationRule 来配置权重分布了。
创建如下所示的 DestinationRule 对象:
# locality-lb-weight.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: helloworld
namespace: sample
spec:
host: helloworld.sample.svc.cluster.local
trafficPolicy:
connectionPool:
http:
maxRequestsPerConnection: 1
loadBalancer:
simple: ROUND_ROBIN
localityLbSetting:
enabled: true
distribute:
- from: region1/*
to:
"region1/*": 80
"region2/*": 20
- from: region2/*
to:
"region2/*": 80
"region1/*": 20
outlierDetection:
consecutive5xxErrors: 1
interval: 1s
baseEjectionTime: 1m在上面的 DestinationRule 对象中我们指定了流量策略,其中最重要的是 localityLbSetting,它定义了流量按地区的分布策略,如果流量请求来自 region1 地区,那么将有 80% 的流量被负载到 region1,有 20% 的流量被负载到 region2,反之亦然,这样就实现了地区的按权重的负载均衡。最后通过 outlierDetection 配置了故障检测。
在两个集群中都需要部署这个 DestinationRule 对象:
kubectl apply -f samples/helloworld/locality-lb-weight.yaml -n sample --context cluster1
kubectl apply -f samples/helloworld/locality-lb-weight.yaml -n sample --context cluster2创建过后当我们再次访问 helloworld 服务时,就会按照我们配置的权重分布来负载流量了:
# 集群1
$ while true; do curl -s "http://192.168.247.225/hello"; done
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
# 集群2
$ while true; do curl -s "http://192.168.247.175/hello"; done
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v2, instance: helloworld-v2-79d5467d55-mvgms到这里我们就成功的在 Istio 中配置了按权重的地域负载均衡了。
配置地域故障转移
我们知道当我们在多个地区/区域部署多个服务实例时,如果某个地区/区域的服务实例不可用,那么我们可以将流量转移到其他地区/区域的服务实例上,实现地域故障转移,这样就可以保证服务的高可用性。
同样在 Istio 中要实现地域故障转移,我们需要使用 DestinationRule 对象来配置故障转移策略,比如我们将 region1 故障转移到 region2,region2 故障转移到 region1。创建如下所示的 DestinationRule 对象:
# locality-lb-failover.yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: helloworld
namespace: sample
spec:
host: helloworld.sample.svc.cluster.local
trafficPolicy:
connectionPool:
http:
maxRequestsPerConnection: 1 # 关闭 HTTP Keep-Alive,强制每个HTTP请求使用一个新连接的策略
loadBalancer:
simple: ROUND_ROBIN
localityLbSetting:
enabled: true
failover:
- from: region1
to: region2
- from: region2
to: region1
outlierDetection:
consecutive5xxErrors: 1 # 连续 1 次 5xx 错误
interval: 1s # 检测间隔 1s
baseEjectionTime: 1m # 基础驱逐时间 1m要实现故障转移非常简单,只需要在 localityLbSetting 中配置 failover,这里我们将 region1 故障转移到 region2,region2 故障转移到 region1。
在两个集群中都需要部署这个 DestinationRule 对象:
kubectl apply -f samples/helloworld/locality-lb-failover.yaml -n sample --context cluster1
kubectl apply -f samples/helloworld/locality-lb-failover.yaml -n sample --context cluster2创建完成后我们先访问从集群 1 访问 helloworld 服务:
# 集群1
$ while true; do curl -s "http://192.168.247.225/hello"; done
Hello version: v2, instance: helloworld-v2-79d5467d55-m7sp9
Hello version: v2, instance: helloworld-v2-79d5467d55-m7sp9
Hello version: v2, instance: helloworld-v2-79d5467d55-m7sp9
Hello version: v2, instance: helloworld-v2-79d5467d55-m7sp9
Hello version: v2, instance: helloworld-v2-79d5467d55-m7sp9验证响应中的 version 是 v2,也就是说我们访问的是 region1 的 helloworld 服务。重复几次,验证响应总是相同的,因为现在没有任何故障,所以只访问本区域的实例。
接下来,触发故障转移到 region2。这里我们将 region1 中 HelloWorld 逐出 Envoy Sidecar 代理:
$ kubectl --cnotallow=cluster1 exec \
"$(kubectl get pod --cnotallow=cluster1 -n sample -l app=helloworld \
-l versinotallow=v2 -o jsnotallow='{.items[0].metadata.name}')" \
-n sample -c istio-proxy -- curl -sSL -X POST 127.0.0.1:15000/drain_listeners再次访问 helloworld 服务:
$ while true; do curl -s "http://192.168.247.225/hello"; done
upstream connect error or disconnect/reset before headers. retried and the latest reset reason: remote connection failure, transport failure reason: delayed connect error: 111
upstream connect error or disconnect/reset before headers. retried and the latest reset reason: remote connection failure, transport failure reason: delayed connect error: 111
# ......
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69
Hello version: v1, instance: helloworld-v1-b6c45f55-r2l69前面几次调用将会失败,差不多一分钟后故障检测生效,这将触发故障转移,多次重复该命令,并验证响应中的 version 始终为 v1,也就是说我们访问的是 region2 的 helloworld 服务,这样就实现了地域故障转移。






























