












当你和朋友隔着冷冰冰的手机屏幕聊天时,你得猜猜对方的语气。当 Ta 发语音时,你的脑海中还能浮现出 Ta 的表情甚至动作。如果能视频通话显然是最好的,但在实际情况下并不能随时拨打视频。
如果你正在与一个远程朋友聊天,不是通过冰冷的屏幕文字,也不是缺乏表情的虚拟形象,而是一个逼真、动态、充满表情的数字化虚拟人。这个虚拟人不仅能够完美地复现你朋友的微笑、眼神,甚至是细微的肢体动作。你会不会感到更加的亲切和温暖呢?真是体现了那一句「我会顺着网线爬过来找你的」。
这不是科幻想象,而是在实际中可以实现的技术了。
面部表情和肢体动作包含的信息量很大,这会极大程度上影响内容表达的意思。比如眼睛一直看着对方说话和眼神基本上没有交流的说话,给人的感觉是截然不同的,这也会影响另一方对沟通内容的理解。我们在交流过程中对这些细微的表情和动作都有着极敏锐的捕捉能力,并用它们来形成对交谈伙伴意图、舒适度或理解程度的高级理解。因此,开发能够捕捉这些微妙之处的高度逼真的对话虚拟人对于互动至关重要。
为此,Meta 与加利福尼亚大学的研究者提出了一种根据两人对话的语音音频生成逼真虚拟人的方法。它可以合成各种高频手势和表情丰富的面部动作,这些动作与语音非常同步。对于身体和手部,他们利用了基于自回归 VQ 的方法和扩散模型的优势。对于面部,他们使用以音频为条件的扩散模型。然后将预测的面部、身体和手部运动渲染为逼真虚拟人。研究者证明了在扩散模型上添加引导姿势条件能够生成比以前的作品更多样化和合理的对话手势。

- 论文地址:https://huggingface.co/papers/2401.01885
- 项目地址:https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
研究者表示,他们是第一个研究如何为人际对话生成逼真面部、身体和手部动作的团队。与之前的研究相比,研究者基于 VQ 和扩散的方法合成了更逼真、更多样的动作。
方法概览
研究者从记录的多视角数据中提取潜在表情代码来表示面部,并用运动骨架中的关节角度来表示身体姿势。如图 3 所示,本文系统由两个生成模型组成,在输入二人对话音频的情况下,生成表情代码和身体姿势序列。然后,表情代码和身体姿势序列可以使用神经虚拟人渲染器逐帧渲染,该渲染器可以从给定的相机视图中生成带有面部、身体和手部的完整纹理头像。
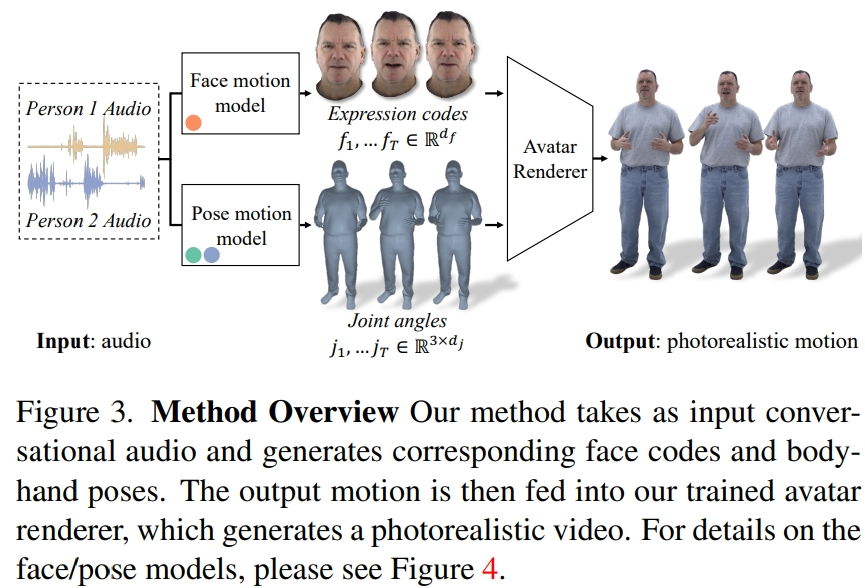
需要注意的是,身体和脸部的动态变化非常不同。首先,面部与输入音频的相关性很强,尤其是嘴唇的运动,而身体与语音的相关性较弱。这就导致在给定的语音输入中,肢体手势有着更加复杂的多样性。其次,由于在两个不同的空间中表示面部和身体,因此它们各自遵循不同的时间动态。因此,研究者用两个独立的运动模型来模拟面部和身体。这样,脸部模型就可以「主攻」与语音一致的脸部细节,而身体模型则可以更加专注于生成多样但合理的身体运动。
面部运动模型是一个扩散模型,以输入音频和由预先训练的唇部回归器生成的唇部顶点为条件(图 4a)。对于肢体运动模型,研究者发现仅以音频为条件的纯扩散模型产生的运动缺乏多样性,而且在在时间序列上显得不够协调。但是,当研究者以不同的引导姿势为条件时,质量就会提高。因此,他们将身体运动模型分为两部分:首先,自回归音频条件变换器预测 1fp 时的粗略引导姿势(图 4b),然后扩散模型利用这些粗略引导姿势来填充细粒度和高频运动(图 4c)。关于方法设置的更多细节请参阅原文。

实验及结果
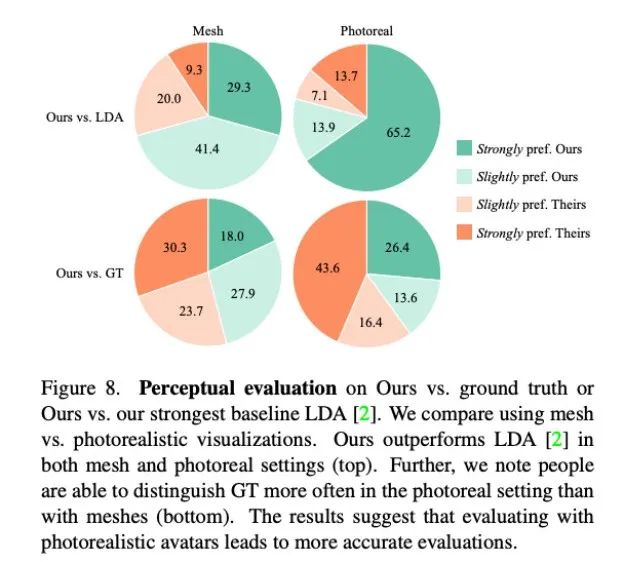
研究者根据真实数据定量评估了 Audio2Photoreal 有效生成逼真对话动作的能力。同时,还进行了感知评估,以证实定量结果,并衡量 Audio2Photoreal 在给定的对话环境中生成手势的恰当性。实验结果表明,当手势呈现在逼真的虚拟化身上而不是 3D 网格上时,评估者对微妙手势的感知更敏锐。
研究者将本文方法与 KNN、SHOW、LDA 这三种基线方法根据训练集中的随机运动序列进行了生成结果对比。并进行了消融实验,测试了没有音频或指导姿势的条件下、没有引导姿势但基于音频的条件下、没有音频但基于引导姿势的条件下 Audio2Photoreal 每个组件的有效性。
定量结果
表 1 显示,与之前的研究相比,本文方法在生成多样性最高的运动时,FD 分数最低。虽然随机具有与 GT 相匹配的良好多样性,但随机片段与相应的对话动态并不匹配,导致 FD_g 较高。
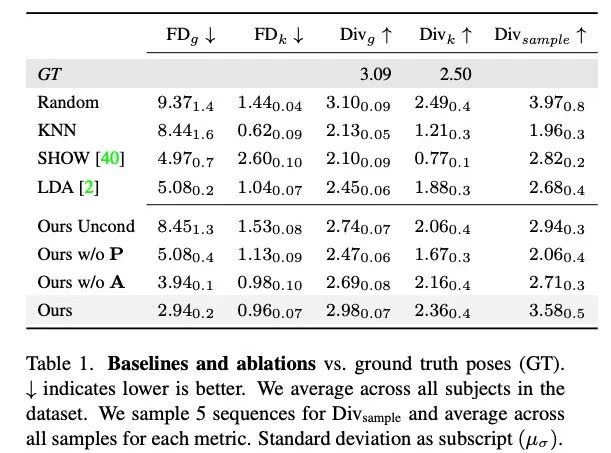
图 5 展示了本文方法所生成的引导姿势的多样性。通过基于 VQ 的变换器 P 采样,可以在相同音频输入的条件下生成风格迥异的姿势。

如图 6 所示,扩散模型会学习生成动态动作,其中的动作会与对话音频更加匹配。

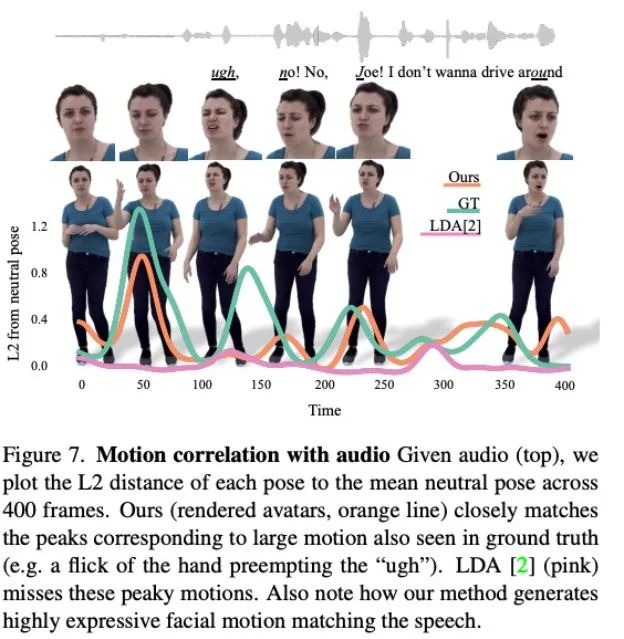
图 7 表现了 LDA 生成的运动缺乏活力,动作也较少。相比之下,本文方法合成的运动变化与实际情况更为吻合。
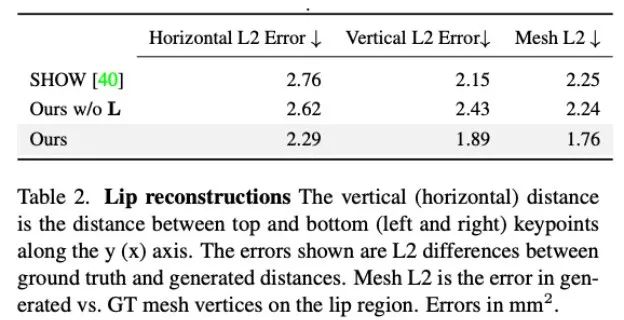
此外,研究者还分析了本文方法在生成嘴唇运动方面的准确度。如表 2 中的统计所示,Audio2Photoreal 显著优于基线方法 SHOW,以及在消融实验中移除预训练的嘴唇回归器后的表现。这一设计改善了说话时嘴形的同步问题,有效避免了不说话时口部出现随机张开和闭合的动作,使得模型能够实现更出色的的嘴唇动作重建,同时降低了面部网格顶点(网格 L2)的误差。
定性评估
由于对话中手势的连贯性难以被量化,研究者采用了定性方法做评估。他们在 MTurk 进行了两组 A/B 测试。具体来说,他们请测评人员观看本文方法与基线方法的生成结果或本文方法与真实情景的视频对,请他们评估哪个视频中的运动看起来更合理。
如图 8 所示,本文方法显著优于此前的基线方法 LDA,大约有 70% 的测评人员在网格和真实度方面更青睐 Audio2Photoreal。
如图 8 顶部图表所示,和 LDA 相比,评估人员对本文方法的评价从「略微更喜欢」转变为「强烈喜欢」。和真实情况相比,也呈现同样的评价。不过,在逼真程度方面,评估人员还是更认可真实情况,而不是 Audio2Photoreal。
更多技术细节,请阅读原论文。
























