













1. Rust线程实现理念
在大部分现代操作系统中,已执行程序的代码在一个 进程(process)中运行,操作系统则会负责管理多个进程。在程序内部,也可以拥有多个同时运行的独立部分。这些运行这些独立部分的功能被称为 线程(threads)。例如,web 服务器可以有多个线程以便可以同时响应多个请求。

将程序中的计算拆分进多个线程可以改善性能,因为程序可以同时进行多个任务,不过这也会增加复杂性。因为线程是同时运行的,所以无法预先保证不同线程中的代码的执行顺序。这会导致诸如此类的问题:
- 竞态条件(Race conditions),多个线程以不一致的顺序访问数据或资源。
- 死锁(Deadlocks),两个线程相互等待对方,这会阻止两者继续运行。
- 只会发生在特定情况且难以稳定重现和修复的 bug。
Rust 尝试减轻使用线程的负面影响。不过在多线程上下文中编程仍需格外小心,同时其所要求的代码结构也不同于运行于单线程的程序。
编程语言有一些不同的方法来实现线程,而且很多操作系统提供了创建新线程的 API。Rust 标准库使用 1:1 线程实现,这代表程序的每一个语言级线程使用一个系统线程。
2.使用spawn创建新线程
为了创建一个新线程,需要调用 thread::spawn 函数并传递一个闭包, 并在其中包含希望在新线程运行的代码。看下面的例子:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}注意当 Rust 程序的主线程结束时,新线程也会结束,而不管其是否执行完毕。这个程序的输出可能每次都略有不同,不过它大体上看起来像这样:
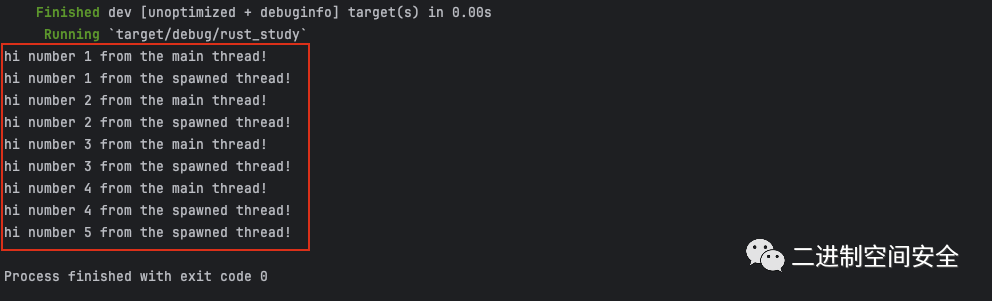
thread::sleep 调用强制线程停止执行一小段时间,这会允许其他不同的线程运行。这些线程可能会轮流运行,不过并不保证如此:这依赖操作系统如何调度线程。在这里,主线程首先打印,即便新创建线程的打印语句位于程序的开头,甚至即便我们告诉新建的线程打印直到 i 等于 9,它在主线程结束之前也只打印到了 5。
如果运行代码只看到了主线程的输出,或没有出现重叠打印的现象,尝试增大区间 (变量 i 的范围) 来增加操作系统切换线程的机会。
3.使用join等待所有线程结束
由于主线程结束,上面演示的代码大部分时候不光会提早结束新建线程,因为无法保证线程运行的顺序,甚至不能实际保证新建线程会被执行!
可以通过将 thread::spawn 的返回值储存在变量中来修复新建线程部分没有执行或者完全没有执行的问题。thread::spawn 的返回值类型是 JoinHandle。JoinHandle 是一个拥有所有权的值,当对其调用 join 方法时,它会等待其线程结束。
看下面的示例代码:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}通过调用 handle 的 join 会阻塞当前线程直到 handle 所代表的线程结束。阻塞(Blocking)线程意味着阻止该线程执行工作或退出。因为我们将 join 调用放在了主线程的 for 循环之后,编译这段代码后运行结果如下:
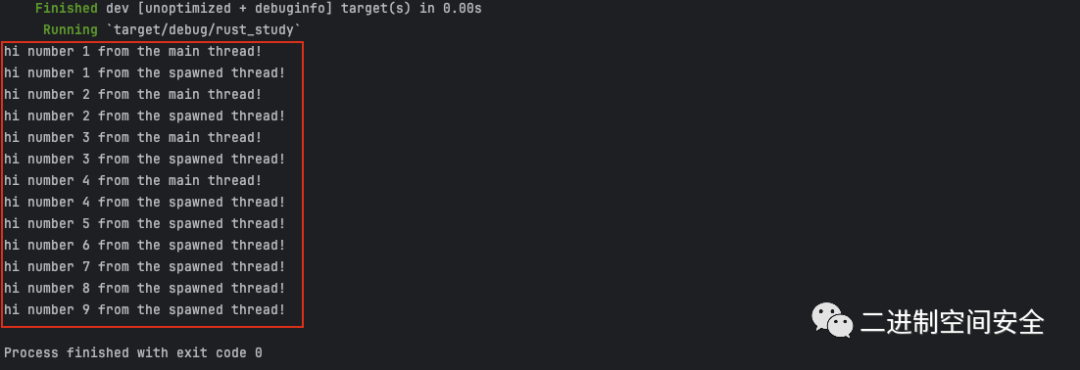
这两个线程仍然会交替执行,不过主线程会由于 handle.join() 调用会等待直到新建线程执行完毕。
不过如果将 handle.join() 移动到 main 中 for 循环之前会发生什么呢,看下面的代码:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}代码编译执行后结果如下:

主线程会等待直到新建线程执行完毕之后才开始执行 for 循环,所以输出将不会交替出现。
因此,将join放在代码的不同地方, 将会影响线程是否同时执行。
4.将move闭包与线程一起使用
move 关键字经常用于传递给 thread::spawn 的闭包,因为闭包会获取从环境中取得的值的所有权,因此会将这些值的所有权从一个线程传送到另一个线程。
为了在新建线程中使用来自于主线程的数据,需要新建线程的闭包获取它需要的值, 下面的代码展示了一个尝试在主线程中创建一个 vector 并用于新建线程的例子,不过这么写还不能工作, 代码如下:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}闭包使用了 v,所以闭包会捕获 v 并使其成为闭包环境的一部分。因为 thread::spawn 在一个新线程中运行这个闭包,所以可以在新线程中访问 v。然而当编译这个例子时,会得到如下错误:
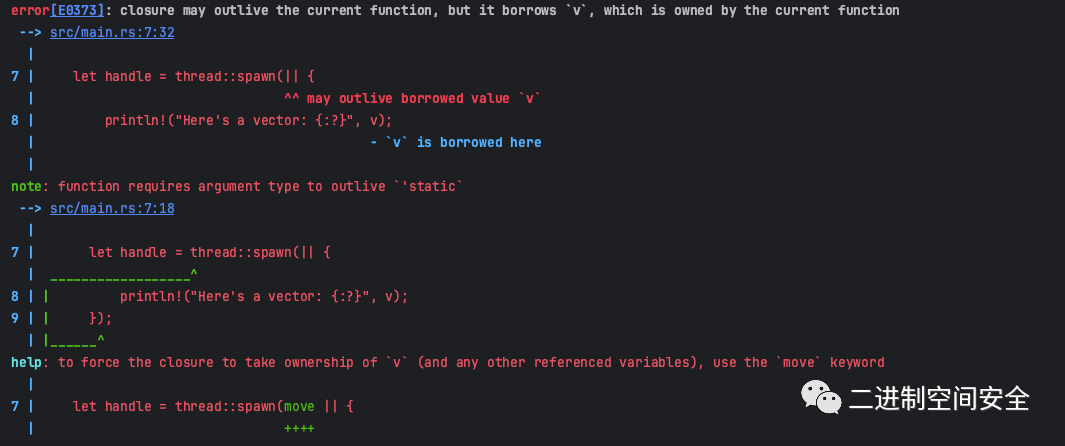
Rust 会 推断 如何捕获 v,因为 println! 只需要 v 的引用,闭包尝试借用 v。然而这有一个问题:Rust 不知道这个新建线程会执行多久,所以无法知晓对 v 的引用是否一直有效。
看一段比较极端情况的代码:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
drop(v); // 坏事儿了!
handle.join().unwrap();
}如果 Rust 允许这段代码运行,则新建线程则可能会立刻被转移到后台并完全没有机会运行。新建线程内部有一个 v 的引用,不过主线程立刻就使用drop丢弃了v。接着当新建线程开始执行,v 已不再有效,所以其引用也是无效的。
为了修复上面的编译错误, 我们可以根据编译器给予我们的help尝试修正一下,如图:

通过在闭包之前增加 move 关键字,强制闭包获取其使用的值的所有权,而不是任由 Rust 推断它应该借用值。
修正后的代码如下:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}编译运行试一下:

看起来没问题,那么以这个成功的经验, 修改那段极端情况的代码如下:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {:?}", v);
});
drop(v); // 坏事儿了!
handle.join().unwrap();
}再次编译一下看看结果如何:

Rust编译器依然没有放行, 这个修复行不通。
如果为闭包增加 move,将会把 v 移动进闭包的环境中, 因此将不能在主线程中对其调用 drop 了, Rust 的所有权规则又一次帮助我们杜绝了隐患。因为 Rust 是保守的并只会为线程借用 v,这意味着主线程理论上可能使新建线程的引用无效。通过告诉 Rust 将 v 的所有权移动到新建线程,我们向 Rust 保证主线程不会再使用 v。如果对其作出同样的move修改, 那么当在主线程中使用 v 时就会违反所有权规则。move 关键字覆盖了 Rust 默认保守的借用,但它不允许我们违反所有权规则。






















