太长不看版
这篇论文介绍了一项新的任务 —— 指向性遥感图像分割(RRSIS),以及一种新的方法 —— 旋转多尺度交互网络(RMSIN)。RRSIS 旨在根据文本描述实现遥感图像中目标对象的像素级定位。为了解决现有数据集规模和范围的限制,本文构建了一个新的大规模 RRSIS 数据集(RRSIS-D),其中涵盖了多种空间分辨率的图像和具有尺度和角度多样性的分割目标(已公开!)。
同时还提出了多尺度交互模块和旋转卷积(已开源!),以处理遥感图像的复杂性。实验证明,RMSIN 方法在 RRSIS 任务上表现优于当前最先进的方法,为未来的研究提供了有力的基线。(1080ti 即可跑!)

论文地址:https://arxiv.org/abs/2312.12470
代码地址:https://github.com/Lsan2401/RMSIN
研究背景和意义
指向性遥感图像分割(RRSIS)是一种结合了计算机视觉与自然语言处理两门学科的前沿技术。根据给定的文本描述,RRSIS 可以在遥感图像中对目标对象进行像素级定位。
然而,RRSIS 任务的发展受到现有数据集规模和范围有限的制约。由于遥感图像具有俯瞰拍摄的特殊视角,和自然图片存在巨大的语义差距;且其目标物体具有丰富的尺度和角度变化,这极大提高了数据集标注的难度,需要投入大量人力和时间成本。这些因素限制了现有数据集的规模和标注的精度,导致现存数据集无法满足模型将训练到关键任务的实际运用所需的精度水平。
此外,现有的基于自然图像指向性分割(RIS)方法应用于遥感图像时面临着局限性。如图 1 所示,遥感图像普遍存在多样的大尺度空间变化和多个方向出现的物体,这样巨大的语义差异使得训练于自然图像的 SOTA 方法在遥感图像上表现不佳。
当前的 RIS 方法通常着重于实现视觉和语言特征的对齐,这些方法在边界清晰的上下文中具有良好的表现,但在面对遥感图像的混乱和非结构化性质时精度明显下降,在 RRSIS 任务中性能差距明显。这些问题都呼唤一种更稳健、更广泛的针对遥感图像的方法。
针对上述问题,作者构建了一个全新的大规模 RRSIS 数据集 RRSIS-D,该数据集的规模是其前身的三倍,不仅涵盖了多种空间分辨率的图像,而且分割目标也具有显著的尺度和角度多样性。
同时,作者提出了旋转多尺度交互网络(RMSIN)。RMSIN 的结构包含多尺度交互模块和旋转卷积,以应对 RRSIS 的复杂性。

图1:遥感图像分割普遍存在的问题。
具体来说,该研究的贡献可总结为:
- 构建了新的指向性遥感图像分割 benchmark 数据集 RRSIS-D。RRSIS-D 基于 SAM 强大的分割功能,再进行手动校准,涵盖多种多样的空间分辨率和物体方向的数据。新数据集能够为传统 RIS 方法向遥感领域迁移应用提供基础。
- 提出了旋转多尺度交互网络(RMSIN),以应对遥感图像中普遍存在的多空间尺度和方向所带来的挑战。
- 设计了层内尺度交互模块和层间尺度交互模块来处理不同尺度内和跨尺度的细粒度信息。同时,作者在分割的解码器端引入了旋转自适应卷积来增强模型的鲁棒性,有效应对 RRSIS 中无处不在的旋转现象。
- 广泛的实验证明了本文中的 RMSIN 优于当前 SOTA 方法,在一系列评估指标上,持续表现出最佳性能,为之后的 RRSIS 的研究提供强有力的基线。
RRSIS-D 数据集
作者提出了一个专门指向遥感图像分割的大规模数据集 RRSIS-D。Segment Anything Model(SAM)实现了卓越的分割性能。在 SAM 的基础上,作者采用了一种半自动方法实现数据集的标注,利用边界框和 SAM 生成像素级掩码,从而在标注过程中节约成本。
数据集 RRSIS-D 由 17402 个图像 - 描述 - 掩码对组成,所有图像的分辨率统一为高 800px、宽 800px,包含 20 个遥感场景多个物体类别,图像描述由 7 种属性组成。图 2 列举了数据集掩码占图像总尺寸的比例(θ),并列举了具有代表性的数据集实例,可以看出分割目标涉及极大、极小的显著尺度变换的目标。丰富种类的图片使得数据集具有挑战性。
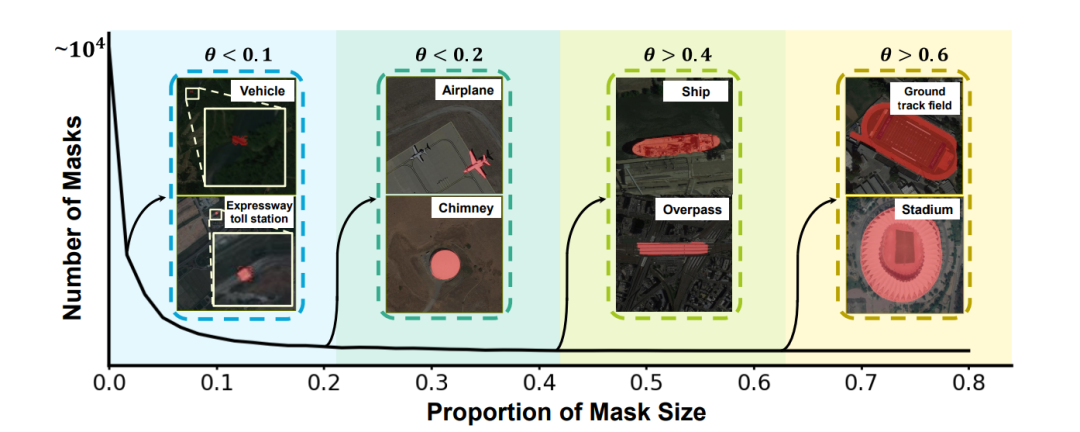
图2:列举了数据集掩码占图像总尺寸的比例。
方法
RMSIN 模型的流程如图 3 所示。对于给定输入图像 和描述
和描述  ,首先描述 E 通过文本 backbone
,首先描述 E 通过文本 backbone 转换为文本特征
转换为文本特征 。
。
同时,图像通过复合尺度交互编码器(Compounded Scale Interaction Encoder,CSIE)进行处理并与文本特征交互,生成具有充分语义的跨多个尺度的融合特征。CSIE 由尺度内交互模块(Intra-scale Interaction Module,IIM)和跨尺度交互模块(Cross-scale Interaction Module,CIM)组成,在编码器的每层,都会应用尺度内交互分支来增强局部视觉建模,而对称的视觉 - 语言融合分支则会对视觉和语言特征进行调整,以改进后续的图像特征提取。
随后,编码器每层的特征都会传递给 CIM,该模块通过多尺度注意(Multi-scale Attention)促进信息交互和空间关系优化。最后,作者提出了基于自适应旋转卷积(ARC)的定向感知解码器(OAD),通过对 CSIE 多个阶段的特征进行并行推理来生成分割掩码。

图3:RMSIN 模型的流程示意图。
尺度内交互模块(Intra-scale Interaction Module)
编码器每层通过尺度内交互模块(IIM)进一步挖掘每个尺度内的丰富信息,促进视觉和语言模式之间的交互。IIM 基于四个阶段的层次结构,可表示为 。通过文本 backbone 获取文本特征
。通过文本 backbone 获取文本特征 (其中 C 表示通道数)后,IIM 在阶段 i 的输出特征
(其中 C 表示通道数)后,IIM 在阶段 i 的输出特征 可描述为:
可描述为: .
.
其中, 是从视觉 backbone
是从视觉 backbone 和输入 I 中提取的。具体来说,在阶段 i 中,输入特征
和输入 I 中提取的。具体来说,在阶段 i 中,输入特征 经过降采样和 MLP 的组合以缩小尺度并统一特征维度,得到
经过降采样和 MLP 的组合以缩小尺度并统一特征维度,得到 。经过下采样的特征被送入两个分支,分别用于增强视觉先验和融合多模态信息。
。经过下采样的特征被送入两个分支,分别用于增强视觉先验和融合多模态信息。
多感受野分支(Various Receptive)
特征 通过 J 个不同卷积核大小的卷积分支进行变换,以产生具有不同感受野的特征,可表述为:
通过 J 个不同卷积核大小的卷积分支进行变换,以产生具有不同感受野的特征,可表述为: .
.
其中, 表示卷积的第 j 个分支,σ 表示 Sigmoid 函数。公式即表达利用不同的卷积设置来平衡所有像素之间的权重
表示卷积的第 j 个分支,σ 表示 Sigmoid 函数。公式即表达利用不同的卷积设置来平衡所有像素之间的权重 。权重通过以下方式来增强特征:
。权重通过以下方式来增强特征: .
.
输出由视觉门 α (Vision Gate) 调节后,作为原始图像特征的局部细粒度信息的补充特征。视觉门的具体实现方法是:
 .
.
其中,LN (⋅) 为 1×1 卷积核大小的卷积,Tanh (⋅) 和 ReLU (⋅) 表示激活函数。
跨模态对齐分支(Cross-modal Alignment)
跨模态对齐分支是专为多模态特征对齐设计的,这是使模型能够理解自然语言的关键。具体来说,在输入 和语言特征
和语言特征 的情况下,首先使用
的情况下,首先使用 作为 Query,以
作为 Query,以 作为 Key 和 Value,实现缩放点积注意力,从而获得多模态特征:
作为 Key 和 Value,实现缩放点积注意力,从而获得多模态特征: ,
,
随后,将注意力 与
与 结合起来,得到语言引导的图像特征:
结合起来,得到语言引导的图像特征: ,
,
与 的输出操作类似,得到的输出由语言门 β(Language Gate) 调节并加到原始图像特征中,作为补充的语言特征。语言门 β 的结构与视觉门相同。因此,尺度内交互模块在 i 阶段的整体输出特性可以表示为:
的输出操作类似,得到的输出由语言门 β(Language Gate) 调节并加到原始图像特征中,作为补充的语言特征。语言门 β 的结构与视觉门相同。因此,尺度内交互模块在 i 阶段的整体输出特性可以表示为: .
.
跨尺度交互模块(Cross-scale Interaction Module)
基于通过尺度内特征交互获得在语言特征的引导下的局部多尺度特征,作者提出跨尺度交互模块以进一步加强粗粒度和细粒度特征间的交互,以应对遥感图像中的大尺度变化。具体来说,该模块将尺度内交互模块每层的输出,即之前提到的,作为输入,并执行多阶段交互。首先进行多尺度特征组合,将特征 在空间维度降采样到相同大小,并沿通道维度进行拼接,公式表达如下:
在空间维度降采样到相同大小,并沿通道维度进行拼接,公式表达如下: ,
,
 .
.
其中, 表示
表示 降采样后的新特征,downsample (⋅) 通过 Average Pooling 实现;
降采样后的新特征,downsample (⋅) 通过 Average Pooling 实现; 表示沿通道维度拼接的多尺度特征,即通过
表示沿通道维度拼接的多尺度特征,即通过 操作在通道维度拼接
操作在通道维度拼接  得到的多尺度特征。多尺度特征
得到的多尺度特征。多尺度特征 随后被输入到不同的感受野以实现深度多尺度交互,通过大小和步长不同的被调整到不同的尺度,其定义如下:
随后被输入到不同的感受野以实现深度多尺度交互,通过大小和步长不同的被调整到不同的尺度,其定义如下:
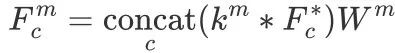
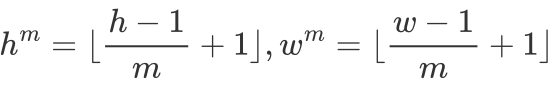
其中, 是调整的尺度数,
是调整的尺度数, 是第 m 个深度卷积的卷积核大小,
是第 m 个深度卷积的卷积核大小, 和
和  是
是 的高度和权重。以此得到
的高度和权重。以此得到 集合,就可以在空间维度上对所有元素进行扁平化处理,并将它们拼接成一个序列的多尺度感知特征
集合,就可以在空间维度上对所有元素进行扁平化处理,并将它们拼接成一个序列的多尺度感知特征 。以原特征
。以原特征 作为 Query,以多尺度感知特征
作为 Query,以多尺度感知特征 作为 Key 和 Value 执行跨尺度注意力:
作为 Key 和 Value 执行跨尺度注意力:

为了更好地保留局部细节,在跨尺度注意力输出中并行加入局部关系补偿,得到跨尺度注意力的最终输出: ,
,
其中,DWConv (⋅) 表示深度卷积,Hardswish (⋅) 为激活函数,以增强多尺度局部信息的提取。
最终,对于来自 的每个部分,都会执行来自
的每个部分,都会执行来自 相应部分的感知门正则化,以获得跨尺度交互的权重。该权重被视为尺度内特征模块输出的辅助残差。计算公式如下:
相应部分的感知门正则化,以获得跨尺度交互的权重。该权重被视为尺度内特征模块输出的辅助残差。计算公式如下:
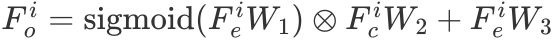
其中 。感知门的输出被用于后续解码器的最终掩码预测。
。感知门的输出被用于后续解码器的最终掩码预测。
自适应旋转动态卷积
考虑到遥感图像中的目标实例通常会呈现不同的方向,使用静态的水平卷积核生成掩码可能会导致精度缺失。受旋转物体检测的启发,作者提出使用自适应旋转动态卷积的分割解码器中,以实现更好的掩码预测。
自适应旋转卷积从输入特征中捕捉角度信息,并动态地重参数化卷积核权重参数,以过滤冗余特征。具体来说,它提取方向特征,并根据输入预测 n 个角度 和相应的权重
和相应的权重 。对于输入 Χ,θ,λ 的预测值为:
。对于输入 Χ,θ,λ 的预测值为: ,
,
由于静态卷积核权重可以看作是从特征映射齐次方程的二维核空间以特定方向采样点采样得到的值。因此,卷积核的旋转就是旋转 - 重采样的过程。具体来说,卷积核权重 根据预测的角度重参数化(Rotate Block)如下所示:
根据预测的角度重参数化(Rotate Block)如下所示:
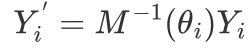
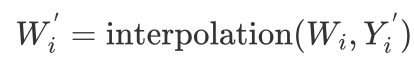
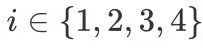
其中, 是原始卷积核采样点的坐标,
是原始卷积核采样点的坐标, 是围绕坐标原点进行旋转仿射变换的旋转矩阵的逆矩阵,interpolation (⋅) 通过双线性插值实现。最后,用得到的卷积核对特征进行过滤,并进行加权求和运算,以生成方向感知特征:
是围绕坐标原点进行旋转仿射变换的旋转矩阵的逆矩阵,interpolation (⋅) 通过双线性插值实现。最后,用得到的卷积核对特征进行过滤,并进行加权求和运算,以生成方向感知特征:
则自顶向下的掩码预测整体过程可总结如下:
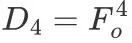
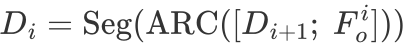
,
其中,Seg (⋅) 指的是包括 3 ×3 卷积层、Batch Normalization 层和 ReLU 激活函数的非线性模块,以增强分割特征空间的非线性。而 Proj (⋅) 为线性变换函数,用于将最终特征 映射到二分类的掩码。值得注意的是,
映射到二分类的掩码。值得注意的是, 输入自适应旋转动态卷积 ARC 中获得优化特征
输入自适应旋转动态卷积 ARC 中获得优化特征  ,以利用特征空间中的方向信息,从而消除冗余,提高边界细节的准确性。
,以利用特征空间中的方向信息,从而消除冗余,提高边界细节的准确性。
实验
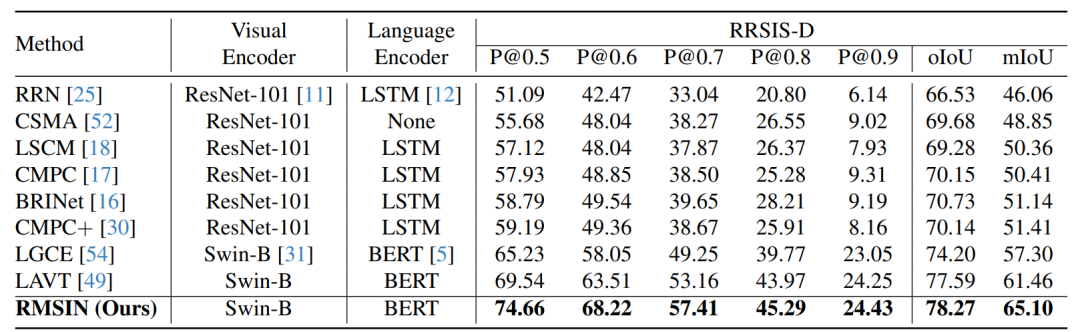
在实验中,作者在 RRSIS-D 数据集上比较了 RMSIN 与现有最先进的自然图像参考图像分割方法的性能。为了进行公平比较,作者遵循了这些方法的原始实现细节。
在验证集中,RMSIN 在每个指标上都优于所有比较方法。值得注意的是,与最近表现最好的 LAVT 方法相比,RMSIN 将 mIoU 提高了 3.54%。在处理非常小或旋转物体等复杂情况时,这种显著提升尤为明显,在 P@0.5、P@0.6 和 P@0.7 中分别提高了 5.12%、4.71% 和 4.25%。这些结果突出表明,RMSIN 能够捕捉到详细的局部信息和特定方向信息,从而实现更准确的分割。
消融
作者在 RRSIS-D 上进行了各种消融实验,以评估 RMSIN 的网络中关键组件的功效。


可视化
为了直观了解 RMSIN ,作者将预测结果与基线进行了定性比较。如图 4 所示,RMSIN 在根据表情精确识别各种比例的目标方面表现出了卓越的能力。此外,它还能在嘈杂的背景中定位微小尺度的物体,并稳健地预测不同角度出现的物体。与此相反,基线模型生成的预测遮罩却存在缺陷,包括部分缺失和明显偏移。

图4:RMSIN 的预测结果与基线进行定性比较。
在图 5 中,作者对在 ARC 和 CSIE 的消融作用下,RMSIN 在训练过程中生成的特征图进行了可视化。很明显,在比例交互和旋转卷积的帮助下,RMSIN 可以准确捕捉边界信息。有了 CSIE 的比例交互和 ARC 的方向提取,RMSIN 可以更敏锐地聚焦于所指的目标。与第一行相比,CSIE 提供了更精确的深层语义,而 ARC 则提供了空间先验,这对旋转物体分割非常重要。

图5:在 ARC 和 CSIE 的消融作用下,RMSIN 在训练过程中生成的特征图。
结论
在本文中,作者提出了旋转多尺度交互网络(RMSIN),这是一种解决 RRSIS 中复杂空间尺度和方向问题的新型解决方案。RMSIN 中引入的 「内尺度交互模块」和 「跨尺度交互模块」 专门应对航空图像中不同空间尺度的挑战。此外,RMSIN 还集成了自适应旋转卷积功能,为有效处理此类图像的不同方向特征提供了强大的解决方案。在新开发的综合性 RRSIS-D 数据集上进行的广泛验证证明了 RMSIN 的卓越性能。