1、资源 Controller 主要作用
我们知道 k8s 里重要概念之一就是 声明式 API,比如 kubectl apply 就是声明式 API的实现。
效果就是资源对象的运行状态要与我们声明的一致。比如kubectl apply 一个 deployment 的 yml,他要求的状态就是: 该 deployment 成功运行。
那么问题来了,k8s 是如何 "监视" 资源对象,以确保其始终保持我们声明的状态的呢?答案就是 -- Controller。除了组件中的 kube-controller-manager,我们可以编写自己的 Controller,也叫自定义控制器(为了方便下文统称为自定义 Controller)。
接下来,我们就来剖析一下 Controller 背后的"秘密"
2、流程大览
我们先看看社区给出的 Controller 的架构图:
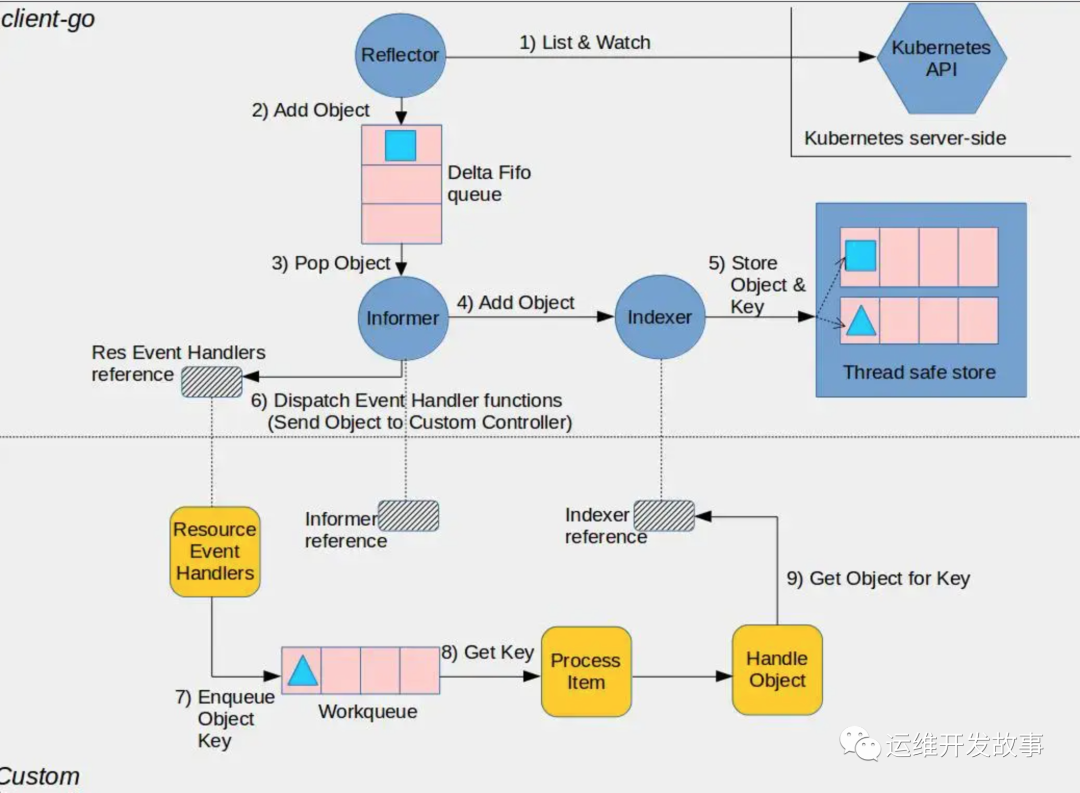
其中有几个主要对象(结构体) -- Reflector、Informer、Indexer。Reflector 和 Indexer 我们会在之后的文章中会一一讲解 。
本文主要是讲解一下 Informer。
从图中可以看到主要有9个步骤,这里我将9个步骤合并成3个大步骤:
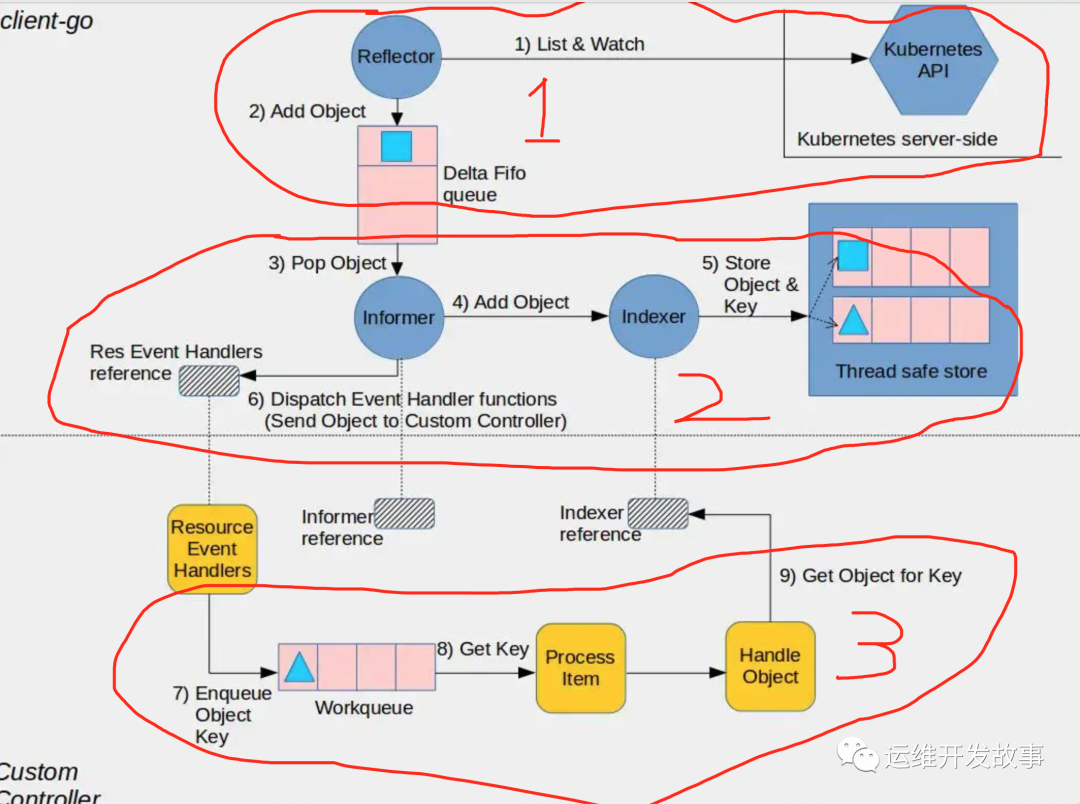
(画的有点丑-__- !!!)
大步骤1: Reflector 将资源对象的事件添加进 Delta FIFO queue 中。
这里先提前介绍一下 Delta FIFO queue。所谓 Delta 就是变化的意思,什么的变化呢?就是资源对象的变化。
即 资源对象的变化都会被添加到 Delta FIFO queue 中!这样是不是就很好理解了。
大步骤2: Informer 将 Delta FIFO queue 中的对象数据 添加到本地 cache 中。
补充一下这个本地 cache 缓存的就是监听资源对象的最新版。就是缓存的当前集群里面的资源信息。
大步骤3: 使用 workqueue 处理业务逻辑。
3、步骤分析
咱们结合社区给的编写的 自定义Controller用例 来做源码分析。这里使用的版本是 client-go v0.20.5。
用例中用到的是普通 informer,介绍的也是普通 informer。但很更多用的是sharedInformer,比如 manager、SharedInformerFactory 都是对普通 informer 的一个再封装,本质的东西是一样的。感兴趣的话,后面再出介绍 sharedInformer、manager 的文章。
大步骤1
我们看到架构图中间有一个分界线,将流程分割为上下两半, 而上半部主要包括大步骤 1、2。
这两个步骤其实是连在一起的,其入口代码就是这一行 : informer.Run(),可以先不管这。
我们先看用例中Informer的初始化入口代码。
NewIndexerInformer 的代码如下:
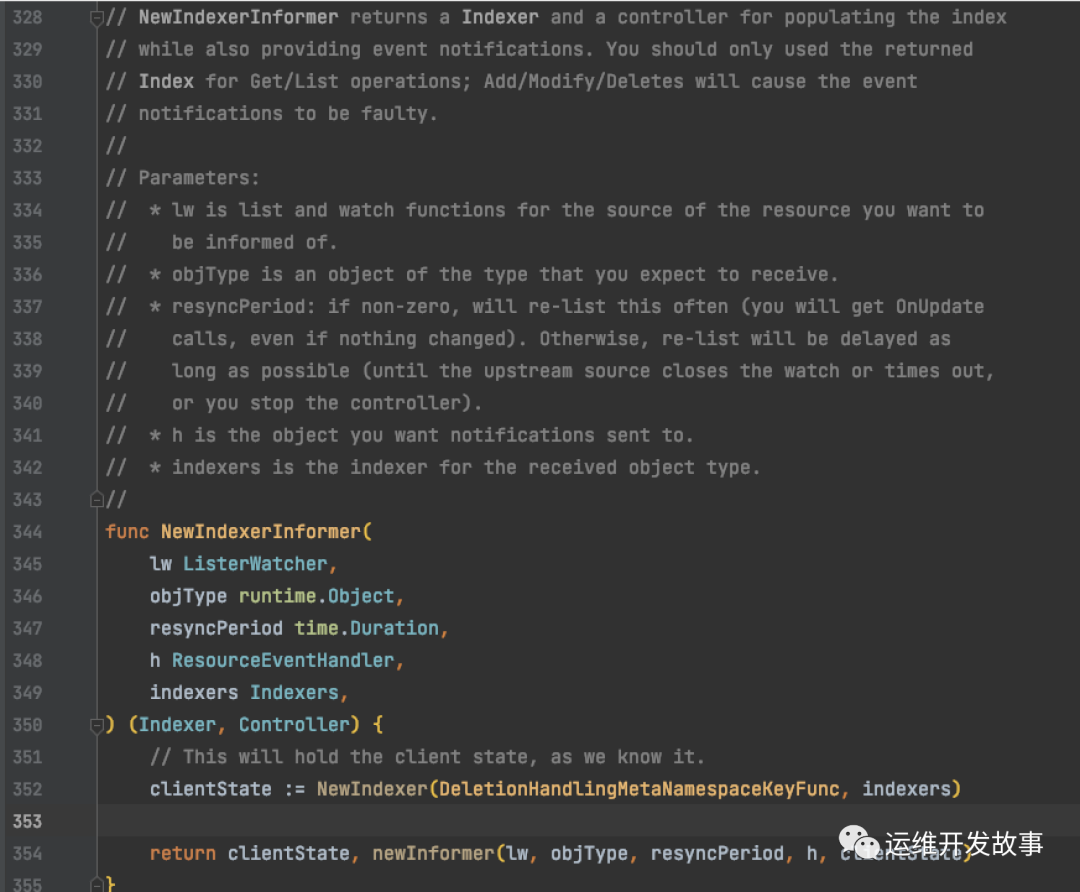
再真正的Informer初始化,就是 newInformer :
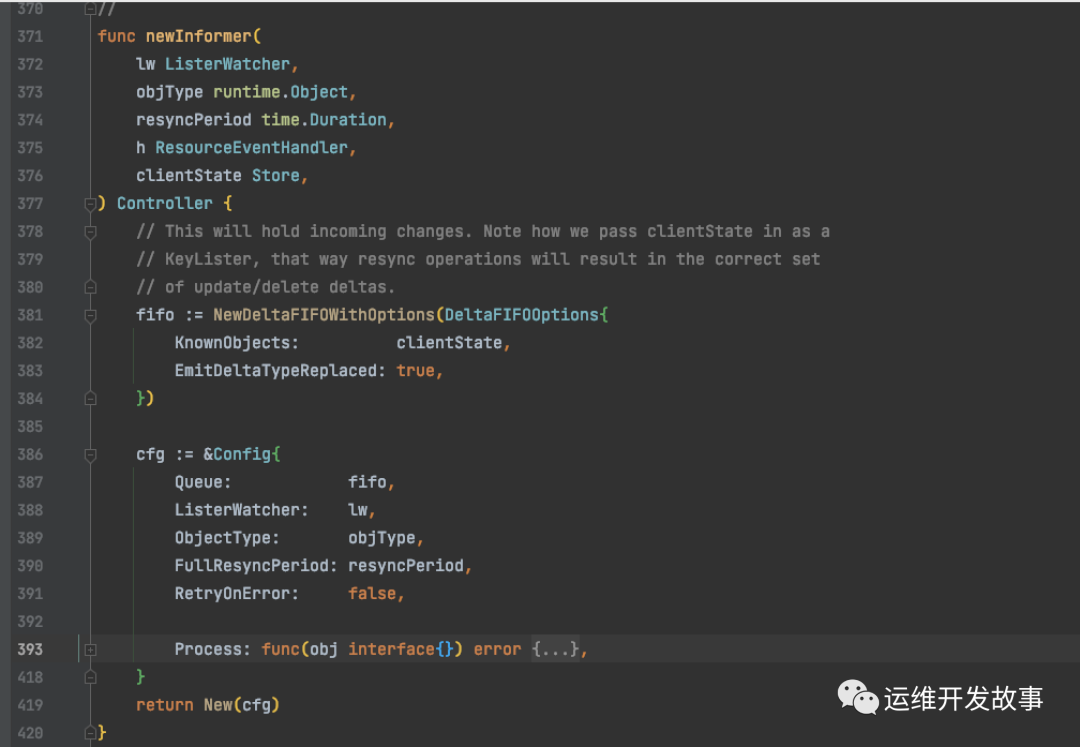
注意第381行 就是 Delta FIFO 的初始化,架构图中的 Delta FIFO queue 就是在这实例化的。
我们发现 newInformer 返回的 是一个 low-level Controller 接口。这个接口抽象的很简单,就三个方法:
Run(stopCh <-chan struct{}):
运行逻辑。HasSynced() bool :
数据同步完成与否LastSyncResourceVersion() string:
资源最近一次的ResourceVersion接下来我们看看三个方法是如何在 controller 中看到这实现的。
咱们直接跳转到 419 行里面的代码,low-level Controller 的初始化, 可以很方便就看到了 Run 方法的实现:
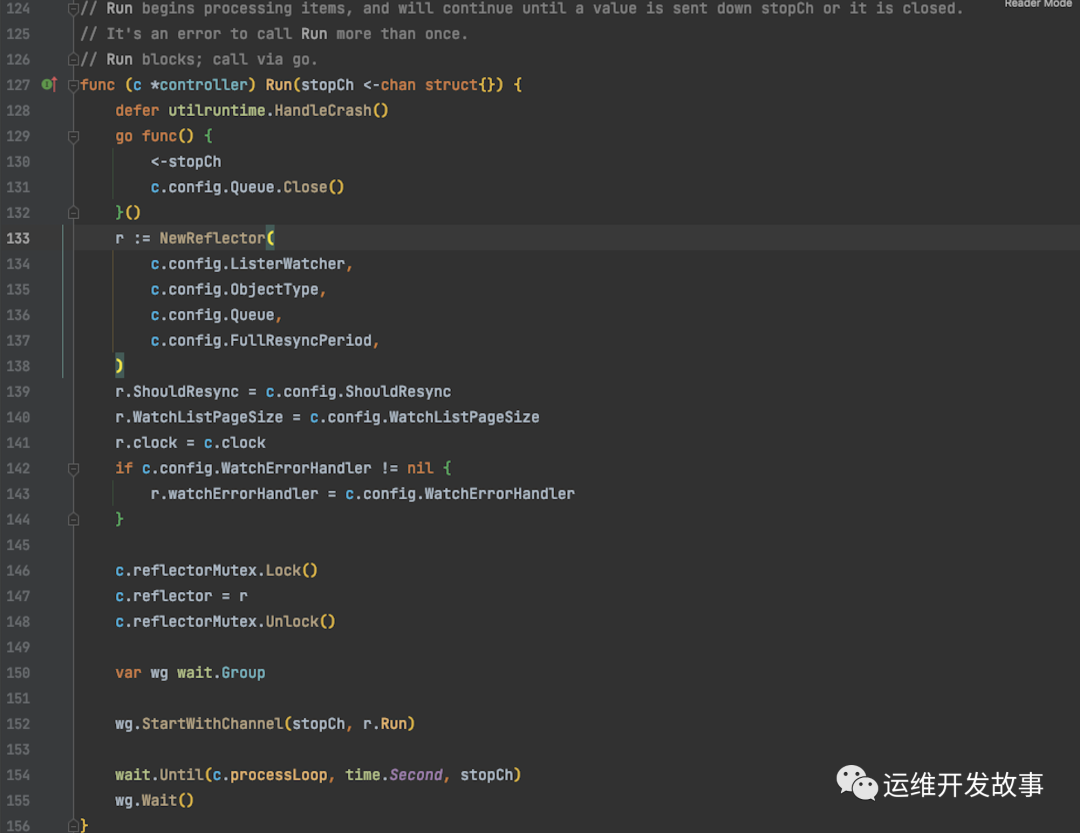
大部分代码是 Reflector 的初始化。
第152行 启动了一个协程,*r.Run* 就是 Reflector 的执行逻辑:List & Watch 资源对象,然后 Add object to Delta FIFO queue 。
咱们点击跳转,直接跳到 ListAndWatch 方法中, 虽然这儿的代码又多又乱(忍不住吐槽),但它要的做的事很简单,就四件事。这里我们就把重点代码拷贝出来说。
第一件事
用你初始化好的 cache.ListWatch 对象 的ListFunc拉取资源对象,然后将对象同步到 Delta FIFO queue:
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
......
......
list, paginatedResult, err = pager.List(context.Background(), options)
if isExpiredError(err) || isTooLargeResourceVersionError(err) {
r.setIsLastSyncResourceVersionUnavailable(true)
// 拉取资源列表
list, paginatedResult, err = pager.List(context.Background(), metav1.ListOptions{ResourceVersion: r.relistResourceVersion()})
}
.....
resourceVersion = listMetaInterface.GetResourceVersion()
.....
items, err := meta.ExtractList(list) // 转换成对象
......
if err := r.syncWith(items, resourceVersion); err != nil { // 将拉取到资源对象都添加到 Delta FIFO queue
return fmt.Errorf("unable to sync list result: %v", err)
}
......
r.setLastSyncResourceVersion(resourceVersion) // 设置最近一次的版本
......
}这里再简单说明一下,r.syncWith(items, resourceVersion) 主要是通过 Delta FIFO queue 中的 Replace() 来同步资源。 其中有一个关键的逻辑如下:
if !f.populated {
f.populated = true
f.initialPopulationCount = len(list) + queuedDeletions
}f.populated =true 就是确定资源对象进入队列的动作已经发生;f.initialPopulationCount 就是确定已经有多少对象在队列中了。
然后我们看 informer HasSynced() 的底层逻辑:
func (f *DeltaFIFO) HasSynced() bool {
f.lock.Lock()
defer f.lock.Unlock()
return f.populated && f.initialPopulationCount == 0
}而 f.initialPopulationCount-- 发生在下文的 pop 中。
LastSyncResourceVersion() string 返回的版本,就是r.setLastSyncResourceVersion(resourceVersion) 设置的。
第二件事
再次同步资源。
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()用例代码 中 cache.NewIndexerInformer() 会设置一个 resyncPeriod 参数就是在这起作用。
设置的是 0,所以这个协程会永远阻塞在 case<-resyncCh。
这的详细逻辑会放在之后讲 Delta FIFO queue 的时候再讲,简单理解就是将 indexer 缓存的数据用同步到 Delta FIFO queue 中。
第三件事
用你初始化好的 cache.ListWatch 对象的 WatchFunc watch 对象。
这里的 watch 功能是底层就是 etcd 的 watch 特性功能,感兴趣的同学可以自己了解一下,这里就不展开说明了。
w, err := r.listerWatcher.Watch(options)
if err != nil {
if utilnet.IsConnectionRefused(err) {
<-r.initConnBackoffManager.Backoff().C()
continue
}
return err
}
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
......
......
}第四件事
将watch到的对象,加入到Delta FIFO queue中。
// watchHandler watches w and keeps *resourceVersion up to date.
func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
....
....
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
....
....
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Deleted:
// TODO: Will any consumers need access to the "last known
// state", which is passed in event.Object? If so, may need
// to change this.
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
}
......
r.setLastSyncResourceVersion(newResourceVersion) // 设置最近一次的版本
......
......
}再简单归纳一下,就两件事:
- 一开始,拉取资源列表然后加入到Delta FIFO queue
- watch 资源对象的变化,加入到Delta FIFO queue
大步骤2
Indexerer 其实算是一个内存数据库的抽象接口。其中Store当然就代表的存储,其他的就是索引相关的。
// client-go/tools/cache/store.go
type cache struct {
// cacheStorage bears the burden of thread safety for the cache
cacheStorage ThreadSafeStore
// keyFunc is used to make the key for objects stored in and retrieved from items, and
// should be deterministic.
keyFunc KeyFunc
}cache 就是接口的实现,就是一个缓存。索引肯定是用作搜索的,其使用咱们下文在 作死的优化 那一节可以看到。
然后我们退回看 Run 方法截图的第154 行代码,看看第二大步骤的逻辑。
wait.Until 就是一个定时器,简化成下面的代码:
func Util(stopCh <-chan struct{}) {
dur := 1 * time.Second
timer := time.NewTimer(dur)
defer timer.Stop()
for {
select {
case <-stopCh:
return
case <-t.C():
f()
timer.Reset(dur)
}
}
}执行的逻辑就是 c.processLoop:
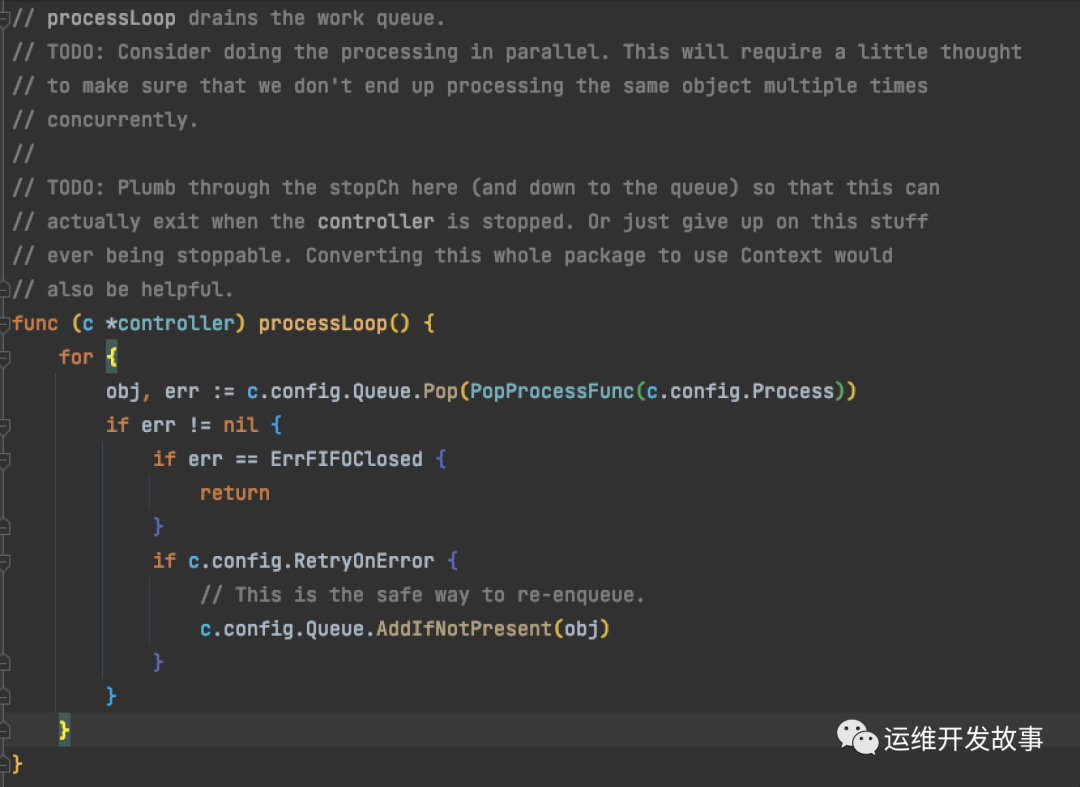
其实代码很容易理解,就是将队列 (Delta FIFO queue)的item 弹出,然后调用处理函数执行ResourceEventHandler中的方法。
先看跳转到 Pop 代码:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
......
......
id := f.queue[0]
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount-- // 同步数据减1
}
......
item, ok := f.items[id]
......
err := process(item)
......
}它的内容其实比较简单,这里只罗列出了最主要的逻辑,相信大伙儿能看明白。而且也看到了上文提到确定同步的关键逻辑 f.initialPopulationCount--
也就是说只有 Delta FIFO queue 中的所有数据都同步到了 Indexer 中,informer 的数据同步才算完成。
然后咱们再来看 process ,就是 newInformer截图 图中我们第393行的 Process ,展开的方法:
Process: func(obj interface{}) error {
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Replaced, Added, Updated:
if old, exists, err := clientState.Get(d.Object); err == nil && exists {
if err := clientState.Update(d.Object); err != nil {
return err
}
h.OnUpdate(old, d.Object)
} else {
if err := clientState.Add(d.Object); err != nil {
return err
}
h.OnAdd(d.Object)
}
case Deleted:
if err := clientState.Delete(d.Object); err != nil {
return err
}
h.OnDelete(d.Object)
}
}
return nil
}我们看 Process 匿名函数的行参,obj 就是 Pop 出的对象。根据 Delta类型d.Type 来判断对对象的处理方式。clientState 就是 Indexer,h 就是 ResourceEventHandler。
所以 Pop出来的对象,马上就进入了 Indexer中,然后再调用 ResourceEventHandler 对应的方法,这里我们就是将 object 的 key 加入到 workqueue 中。
它各种方法的对应的操作就是 这段代码。
大步骤3
最后就是我们自己的应用程序,来处理各种资源事件(Add、Update、Delete)。由于Workqueue的存在,就简化成处理队列里面的元素。
我们直接可以看这个processNextItem 函数。
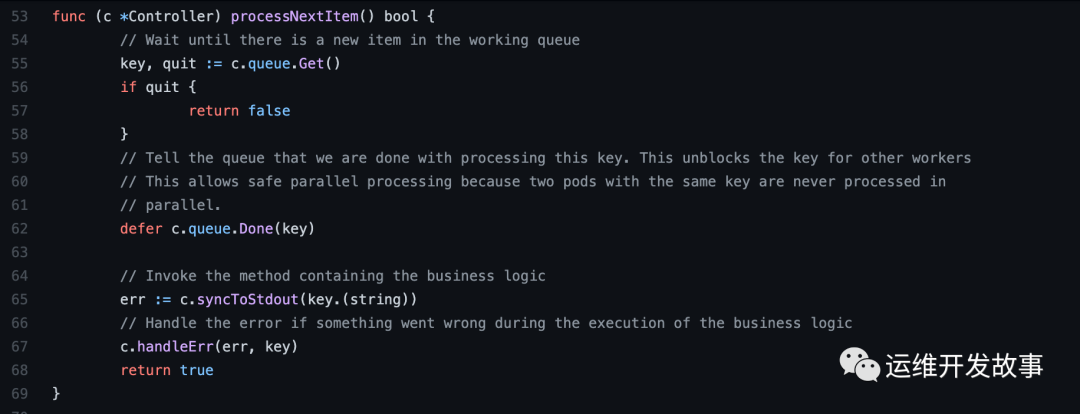
第55行,获取队列里面的数据。
第65行,就是我们处理对象的业务逻辑。syncToStdout 只是打印一些日志, 但其中 obj, exists, err := c.indexer.GetByKey(key) 这行代码很关键,就是从 indexer 中获取资源对象。有了它我们就能处理各种业务逻辑,比如我自己工作一般就是将与ResourceEventHandler定义的变化(AddFunc、UpdateFunc、DeleteFunc 你可以只有AddFunc)的对象写回我们自己的云平台。
类似代码如下(syncToStdout 换成了 action):
func (d *Deployment) action(key string) error {
obj, exists, err := d.indexer.GetByKey(key)
if err != nil {
return fmt.Errorf("fetching object with key %s from store failed with %w", key, err)
}
ns, deploymentName, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
if exists {
deployment, ok := obj.(*apps_v1.Deployment) // 一定要断言资源类型,这里类型要同 list & watch 方法中的一致。github的例子是pod,这里用的是deployment
if !ok {
return fmt.Errorf("type asset fault")
}
post(deployment) // 将资源传回的伪代码
}
return nil
}到这,3大步骤就结束了。
4、补充一个知识:
第三大步骤主要就是对 workqueue 的调用。而 workqueue 有三大类:
- 普通队列
- 延迟队列
- 限速队列
延迟队列是对普通队列的封装。而限速队列是对延迟对列的封装,外加一个限速器。
我们一般使用限速队列,方便我们在处理错误的时候重试。
处理完后,还要记得从队列中移除正在处理的 key
defer c.queue.Done(key)重试与移除在 用例代码 中写的非常清楚,一定不要漏掉这两块重要的逻辑。
作死的“优化”
我们可能会发现 workqueue 有点多余。我们完全可以直接在ResourceEventHandler中处理业务逻辑嘛!代码如下:
func NewPodWithOutWorkQueue(ctx context.Context, clientset *kubernetes.Clientset) {
//workQueue := workqueue.NewDelayingQueue()
namespace := meta_v1.NamespaceAll
listWatcher := &cache.ListWatch{
ListFunc: func(options meta_v1.ListOptions) (runtime2.Object, error) {
//options.LabelSelector = requireLabel.String()
return clientset.CoreV1().Pods(namespace).List(ctx, options)
},
WatchFunc: func(options meta_v1.ListOptions) (watch.Interface, error) {
//options.LabelSelector = requireLabel.String()
return clientset.CoreV1().Pods(namespace).Watch(ctx, options)
},
}
indexer, informer := cache.NewIndexerInformer(listWatcher, &core_v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
fmt.Println("add: ", key)
}
},
DeleteFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
fmt.Println("delete: ", key)
}
},
}, cache.Indexers{
cache.NamespaceIndex: cache.MetaNamespaceIndexFunc,
})
go informer.Run(ctx.Done())
go GetIndexer(indexer)
}
func GetIndexer(idx cache.Indexer) {
for {
time.Sleep( 3 * time.Second)
fmt.Println("GetIndexers:", idx.ListIndexFuncValues(cache.NamespaceIndex))
}
}这里我们还借机查看了Indexer里面的信息。
其中 GetIndexer 就会打印以 namespace 聚合数据。可以简单理解成下面的 sql 语句select namespace from xx_table。
为什么说是作死呢?我们有些小伙伴就是这样写的,以为不依赖一个组件就是“优化”,但却没有思考过为什么官方用例、 manager 中都会用到 workqueue。
所以这就要引申一个问题 为什么要用 workqueue ?原因如下:
- 在不依赖 Delta FIFO queue 的情况下,将资源事件变得有序。
- workqueue 也可以当作缓存看。将要处理的事件以 key 的方式先缓存在 workqueue 中。
缓存的作用相信很多人都清楚:解决两个组件处理速度不匹配的问题,如 cpu 和 硬盘之间经常是用 内存做缓存。
我们的业务处理逻辑大概率肯定是慢于事件的生成的,而且还延迟队列类型做选择方便失败后重试。
加个煎蛋
这可以算个番外系列,不感兴趣的朋友可以直接跳过。
有些同学其实已经发现,我们完全不可以不用那么多队列的(Delta FIFO queue,Workqueue),甚至还用了个小数据库(Indexer)!
我们可不可以直接Watch对象?即相当于直接调用 etcd 的 watch API。答案是可以的。
我们借鉴一下这里的代码。
实现一个pod的watch, 代码如下:
func NewPodOnlyWithWatch(ctx context.Context, clientset *kubernetes.Clientset) {
onlyWatch := &cache.ListWatch{
WatchFunc: func(options meta_v1.ListOptions) (watch.Interface, error) {
//options.LabelSelector = requireLabel.String()
//options.ResourceVersion = ""
return clientset.CoreV1().Pods("devops").Watch(ctx, meta_v1.ListOptions{})
},
}
watcher, err := watch2.NewRetryWatcher("1", onlyWatch)
if err != nil {
panic(err)
}
// Give the watcher a chance to get to sending events (blocking)
time.Sleep(10 * time.Millisecond)
for {
select {
case event, ok := <-watcher.ResultChan():
if !ok {
fmt.Println("ResultChan closed")
return
}
//fmt.Println("get event")
if pod, ok := event.Object.(*core_v1.Pod); ok {
switch event.Type {
case watch.Added:
fmt.Printf("新增事件:%s/%s\n", pod.Namespace, pod.Name)
case watch.Deleted:
fmt.Printf("删除事件:%s/%s\n", pod.Namespace, pod.Name)
case watch.Modified:
fmt.Printf("更新事件:%s/%s\n", pod.Namespace, pod.Name)
default:
fmt.Printf("%s事件:%s\n", event.Type, pod.Name)
}
}
case <-watcher.Done():
fmt.Println("watcher down")
return
}
}
}但不建议直接watcher。其中之一就是:从业务视角会看到的重复性事件。即资源对象的一个更新动作,收到多个事件。
5、总结
我们常说的Controller 他最核心的能力就是能监控到资源的任何变化,也就是 声明式 概念中保证状态的关键技术 -- Informer,流程是:
- Reflector 将对象加入到Delta FIFO queue中。
- 然后 informer 将其 pop 出,加入到 Indexer中,以及 resourceEventHandler。
- 最后就是我们自己的业务逻辑, 即:我们自己先到workqueue中,拿到 key,然后用 key 去Indexer 中换取对象,最后处理对象。
然后我们又通过 一个错误的*优化* 的例子,讲清楚了 workqueue 的重要性。
我们还可以再 geek 一点,选择直接watch对象变化的事件,但个人不建议这样做。
这一篇文章主要是介绍了 资源事件通过 informer 扭转到 ResourceEventHandler 中的大体流程,并没有讲很多细节的部分。
因为我们还需要掌握一些关键的组件:Delta FIFO queue、Indexer、workqueue
当这些都清楚了后,再来了解流程的细节,那就非常轻松了。
当然了除了知道了上面的内容,我们还应该掌握 sharedInformer 以及写 Controller 的“神器” -- controller-runtime 再封装的 manager。
如果大家感兴趣的话再后面的文章再作详细介绍。当了解完了这些后,相信 Controller 中的任何技术细节问题都难不倒你了。