大家好,我是小米,一个热爱技术分享的小伙伴。今天,我们将深入探讨一个在编程中经常用到但却常常被忽视的话题——正则表达式。正则表达式是一个强大的文本匹配工具,然而在使用它时,我们也要注意一些性能上的问题,特别是在处理大量数据时。本文将带你一起深入了解正则表达式的性能优化和一些使用技巧。
什么是正则表达式?
正则表达式是一种用于描述字符串模式的表达式,广泛应用于文本搜索、匹配和替换。通过一些特殊字符和语法规则,我们可以定义一种模式,然后用来匹配输入的文本。
正则表达式引擎
正则表达式引擎根据匹配原理可以分为DFA(Deterministic Finite Automaton)自动机和NFA(Nondeterministic Finite Automaton)自动机。
DFA 是一种确定型有限自动机,它在任何给定的时间点只能处于有限数量的状态之一。而 NFA 是一种非确定型有限自动机,它在某个状态下,有可能有多个状态可以选择。
在实际编程中,常用的正则表达式引擎往往是基于NFA的。
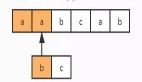
NFA自动机的回溯问题
尽管NFA自动机在理论上更加灵活,但在实际匹配中,NFA自动机常常会遇到回溯的问题。回溯是指当一个匹配失败时,引擎会退回到前一个状态重新尝试匹配。这种回溯机制可能导致性能下降,尤其是在处理大量数据时。
如何避免回溯问题?
为了避免回溯问题,我们可以采用一些优化手段。以下是几种常见的优化技巧:
1、贪婪模式
在正则表达式中,默认情况下是贪婪模式,即匹配尽可能多的字符。在一些情况下,这可能会导致不必要的回溯。我们可以使用问号(?)来将贪婪模式转换为懒惰模式,从而减少回溯的可能性。

在这个例子中,贪婪模式会匹配整个字符串,然后回溯,找到最后一个 "b"。为了避免这种情况,我们可以使用懒惰模式。
2、懒惰模式
懒惰模式与贪婪模式相反,它尽可能少地匹配字符。在某些情况下,懒惰模式能够有效减少回溯,提高匹配效率。

这样,它会匹配到第一个 "b",而不是整个字符串。这可以减少回溯的次数,提高匹配效率。
3、独占模式
除了贪婪模式和懒惰模式外,还有一种叫做独占模式。独占模式会尽可能匹配更长的字符串,但不会回溯。在正则表达式中,可以使用 \G 锚点来表示上一次匹配的结束位置。这样,匹配将从上一次匹配的结束位置开始,不会回溯。

独占模式在某些情况下可以提高性能,但要小心使用,因为它可能导致意外的行为。
正则表达式优化
在实际编码中,我们可以通过一些优化策略来提高正则表达式的性能,特别是在处理大量数据时。以下是一些常见的优化方法:
1、少用贪婪模式,多用独占模式
贪婪模式虽然在某些情况下是必要的,但在不需要的情况下最好避免使用。多使用独占模式,能够有效减少回溯。
2、减少分支选择
正则表达式中的分支选择(使用 |)可能导致引擎不得不尝试多个路径。在可能的情况下,减少分支选择可以减少回溯的发生,提高匹配速度。

可以考虑重写为:

这样就避免了不必要的分支选择。
3、减少捕获嵌套
捕获嵌套指的是正则表达式中多个捕获组的嵌套使用。嵌套较深的捕获组可能导致性能下降,因为引擎需要跟踪多个捕获组的信息。

可以考虑简化为:

这样可以减少嵌套捕获组的数量。
4、正向否定预查
正向否定预查是一种强大的工具,可以在不进行实际匹配的情况下判断字符串的某一部分是否不符合特定模式。例如,我们想匹配不包含"xyz"的字符串:

这样,如果字符串中包含"xyz",整个表达式将不匹配,避免了回溯的发生。
5、条件匹配
条件匹配是一种根据特定条件选择不同匹配路径的方式。这可以通过 (?(condition)true-pattern|false-pattern) 实现。例如,我们想匹配奇数个"a",偶数个"b"的字符串:

这样,我们可以避免回溯,确保性能的稳定。
6、编译正则表达式
在实际使用中,将正则表达式编译成可重用的对象可能有助于提高性能。编译后的正则表达式可以在多次使用时避免重新解析,节省时间。

通过以上的优化策略,我们可以在保证正则表达式功能的基础上,尽可能提高匹配的效率,特别是在处理大规模数据时更为明显。
END
总结一下,正则表达式是编程中非常常见的工具,但在使用时我们也要注意其性能问题。通过选择合适的模式和优化策略,可以在不降低功能的情况下提高匹配的效率。希望大家在实际应用中能够灵活运用这些技巧,写出高性能的正则表达式。