













大语言模型的幻觉问题被解决了!
近日,来自斯坦福的研究人员发布了WikiChat——被称为首个几乎不产生幻觉的聊天机器人!
论文发表在EMNLP 2023,并且在Github上开源了代码:

论文地址:https://aclanthology.org/2023.findings-emnlp.157.pdf
项目代码:https://github.com/stanford-oval/WikiChat
作者表示自己的最佳模型在新的基准测试中获得了97.3%的事实准确性,而相比之下,GPT-4的得分仅为66.1%。
在「recent」和「tail」两个知识子集中,这个差距甚至更大。
另外,作者还发现了检索增强生成(RAG)的几个缺点,并添加了几个重要步骤,以进一步减轻幻觉,并改进「对话性」指标。

通过这些优化,WikiChat在事实性方面比微调后的SOTA RAG模型Atlas高出8.5%,
在相关性、信息性、自然性、非重复性和时间正确性方面也大大领先。
最后,作者将基于GPT-4的WikiChat提炼成7B参数的LLaMA,这个模型在事实准确性方面仍然能拿到91.1%的高分,
并且运行速度提高了6.5倍,能效更好,可以本地部署。
大模型+维基百科,一起击败幻觉
众所周知,LLM的幻觉问题由来已久、根深蒂固,
而且曾给各家的大语言模型都造成过不同程度的影响。
基于LLM使用概率来推断输出的原理,幻觉这个问题很难彻底解决,
研究人员们为此投入大量的心血,小编也是很期待这个WikiChat的表现!
WikiChat,顾名思义,就是基于维基百科的知识进行训练,听起来还挺靠谱的。
除了论文和代码,研究团队还部署了可以直接对话的demo供大家测试,好文明!

Demo地址:https://wikichat.genie.stanford.edu/
于是小编迫不及待地要试一试WikiChat的实力。
WikiChat首先进行了自我介绍,表示自己会记录对话用于研究,
另外,WikiChat有以下三种模式:

默认状态是平衡输出速度和准确性,我们可以在右边的设置中调节。
WikiChat还额外添加了TTS功能,输出是个温柔的女声。
好了,让我们赶紧「Ask her about anything on Wikipedia」!

——开个玩笑,既然你不会中文,那小编这点英文水平,只能献丑了......
(注意上面的这句中文不要点击语音输出,有可能导致整个聊天卡住无法恢复)
下面,我们首先问一个常识性问题:Sam Altman是OpenAI的CEO吗?

其实小编想测试她知不知道Altman被开除,然后又王者归来这件事,
不过这一句「在2020年离开YC,全职加入OpenAI」,貌似就有事实性的错误。
小编接下来使用游戏信息进行测试:介绍一下「原神」中的「宵宫」。

这个回答确实没什么问题,卡池时间和配音演员也正确,
既然提到了配音演员,那顺便问一下中文CV是谁:

这......不知道她为什么产生了这样的幻觉?实际上维基百科中是有相关信息的:

那我们提醒她反思一下:

好家伙,给出了另一个错误答案,小编想了一下,应该说的是游戏中另一位角色的CV(负责《神女劈观》中的戏腔部分,知名度较高)。
那么测试一下,知名度比较高的角色。
小编选择了在维基百科上有单独条目的雷电将军:

这下连卡池时间都有事实性错误,——而维基百科中的相关描述是没有问题的。

WikiChat对于自己一直心心念念的配音演员,倒是没有回答错误。
小编于是不死心地又测试了一遍之前的问题:

WikiChat也是不死心地给出了和之前同样的回答,并且在要求反思之后,变成了「道歉机器人」。
把模式调整到事实性优先:

WikiChat给出回答的速度要慢了很多,但还是只能道歉。
小编于是换了另一位有单独百科条目的角色:

除了第一句,后面就开始满嘴跑火车了。
最后,来问一下配音演员的问题(维基百科的单独条目中包含此信息):

......你这个聊天机器人是什么情况,认准了Juhuahua了是吗?
测试到此结束,小编不知如何总结,有可能是我的问题有问题吧。
比如我问题的相关信息,在英语维基百科的语料中重要性很小。
不论如何,WikiChat在一些问题上的表现确实还不错,比如宵宫那个问题,换成ChatGPT,就几乎没有任何沾边的事实。
这说明研究人员确实采取了一些有效的优化方法,来解决LLM的幻觉问题。
WikiChat架构
这项工作的事实性基础是信息检索(IR),它基于聊天机器人的响应、以及从可信语料库中检索到的信息,然后生成方法利用检索到的数据生成响应。

上图展示了WikiChat的组件,以及一段示例对话(关于即将上映的电影)。
生成响应所采取的步骤包括:
1. 生成从维基百科检索的查询,
2. 总结和过滤检索到的段落,
3. 从LLM生成响应,
4. 从LLM响应中提取声明,
5. 使用检索到的证据对LLM响应中的声明进行事实核查,
6. 起草响应,
7. 完善响应。
研究人员使用用户话语来检索LLM可能不知道的信息,要求LLM做出回应,并对其进行事实检查。
阻止LLM产生幻觉并不容易。一般情况下,当IR没有检索到任何相关信息,或知识语料库中没有相关信息时,LLM会产生幻觉来弥补不足。
因此,WikiChat会汇总和过滤检索到的信息,而不是直接生成响应。
这里分别对LLM生成的每个声明进行事实核查,并在必要时教系统说「我不知道」。
教LLM理解时间背景:例如,文章中的将来时态可能是指对话时的过去事件。
最重要的是,不能通过放弃这些必要的步骤来过早地优化速度,而是依靠模型蒸馏来减少延迟,直到达到高质量。
上图中管道的每个阶段都是使用上下文学习实现的。
生成的管道不特定于任何语料库。虽然本文将管道应用于维基百科以创建WikiChat,但它适用于任何自由文本语料库,包括个人和公司机密信息。
该管道也不特定于任何LLM,作者在本文中将其应用于三个不同的LLM。
策划正确且与对话上下文相关的信息
LLM能够解释用户话语,制定检索范围之外的响应,或者需要聚合来自多个来源的信息或得出结论,比如:
用户:你认为苹果会继续成为科技行业的重要参与者吗?
GPT-4:是的,......苹果拥有良好的创新记录、忠实的客户群和稳健的财务状况。全球市值最高的公司,市值超过2万亿美元。继续探索增强现实、人工智能、自动驾驶汽车等新技术。这将帮助他们在竞争中保持领先地位。
但我们不能完全相信LLM,而是需要对它们的输出进行事实检查。此外,LLM不知道最近发生的事件。
在与用户的对话中,WikiChat会识别何时需要访问外部信息。这可能是因为最后一个用户话语包含直接问题(例如「斯蒂芬·库里是谁?」),或者需要其他信息才能做出全面的回答(例如「我真的很喜欢斯蒂芬·库里」)。
第1阶段,WikiChat生成一个搜索查询,该查询通过提示捕获用户的兴趣(如下图所示)。作者发现,现有的系统尤其难以适应时间环境。
WikiChat在查询旁边生成用户需求的推断时间。查询时间可以是最近、year=yyyy或none之一,分别表示检索到的信息应尽可能近、特定年份或时间不重要。

将查询发送到信息检索系统,从语料库中获取相关段落,并根据时态信息对排名靠前的结果进行重新排序,得到Npassages。
第2阶段,由于这些段落可能包含相关和不相关部分的混合,WikiChat会提取检索到的段落的相关部分,并将它们总结为要点,同时过滤掉不相关的部分(如下图所示)。

第3阶段,提示LLM生成对对话历史记录的响应。这种回应通常包含有趣且相关的知识,但本质上是不可靠的。

第4阶段,LLM响应被分解为多种声明(如下图),此阶段解析共同引用以减少歧义,并解析相对时间信息(如「当前」和「去年」),以使所有声明自包含。

然后使用IR从知识语料库中检索Nevidence段落,以便每个声明作为证据,并使用基于时间的重新排名来更好地处理时间敏感的主题。
第5阶段,验证提示(如下图)使用思维链提示,将每个声明分配给以下三类之一:检索到的证据是否支持该声明、反驳该声明,或者证据中是否没有足够的信息来做出此决定。只有有证据支持的主张才会被保留。

使用收集到的信息来形成响应
实验表明,在满足所有会话标准的情况下一次性编写最终响应,对于上下文学习具有挑战性,尤其是有限的上下文长度,使得很难提供足够的多轮对话,作为少量示例来涵盖所有必要的方面。因此,这里采用两步法:
第6阶段,WikiChat根据给定的要点列表和对话历史记录生成响应草稿。
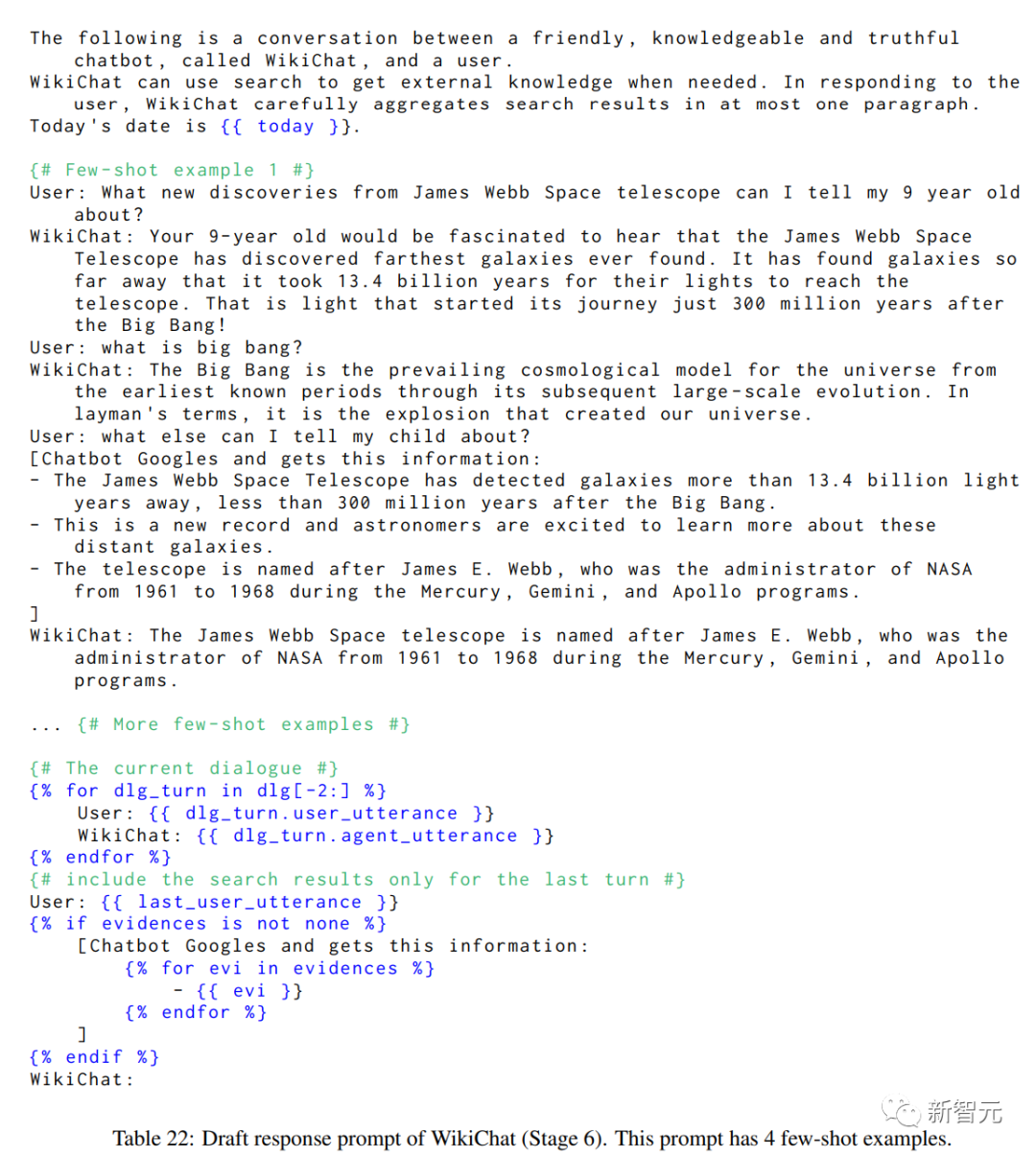
第7阶段,生成反馈并进行优化——基于相关性、自然性、非重复性和时间正确性的响应。

反馈包含模型对每个标准的推理,以及每个标准的分数介于0到100之间,细化以此反馈为条件。
改进是以这种反馈和分数为条件的,作为一个思维链。
最后,我们来看一下WikiChat的效果:

上表展示了WikiChat的评估结果和模拟对话的基线。事实和时间准确性是百分比,其他指标是介于1和5之间的整数的平均值。
事实准确性来自人类评估,其他指标来自小样本GPT-4。所有指标都是越高越好。






























