本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人总结
本文对商用车、乘用车主流自动驾驶技术分传感器配置、系统架构、感知、预测、规划控制等模块进行了分析总结。分析了商用车、乘用车对于自动驾驶技术需求的异同。并结合代表性科技公司如特斯拉、百度、毫末智行、小鹏等对当前自动驾驶系统主要技术进行了分析总结。
典型乘用车商用车自动驾驶技术方案分析:赢彻,毫末智行,特斯拉,百度Apollo。
当前世界范围内自动驾驶公司虽然历经退市、裁员风波,受到技术完备性、安全性、盈利模式等多方面质疑,但仍是各车企、科技公司角逐的热门方向。不过,当前全社会及资本对自动驾驶的关注也已从前两年的尝鲜、新奇、未来属性转变为了对自动驾驶商业模式何时能大规模落地,其盈利模式应该怎么搭建、怎么推广的思考。而自动驾驶落地、盈利模式又与承载自动驾驶方案的车俩类型息息相关,不同类型自动驾驶车型其落地、营运模式差别很大。
1.商用车、乘用车区别
按车俩用途分,当前自动驾驶公司可分乘用车自动驾驶和商用车自动驾驶两大类。乘用车自动驾驶以robotaxi和前装量产为主要目标,客户群体较明确,自动驾驶方案通用性更强。乘用车自动驾驶赛道科技公司较多,目前处于第一梯队的有华为、小鹏、百度Apollo、AutoX、文远知行、滴滴、小马智行、Momenta、毫末智行等,乘用车主机厂自研自动驾驶的有一汽、东风、广汽、极氪等。乘用车自动驾驶方案目前基本确定以BEV+Transformer,重感知、轻地图方案为主,部分特殊场景如高速远距离感知考虑目标级后融合方案作为BEV远距感知缺陷的补充。商用车由于其营运属性复杂,目标客户不固定,其中既有物流运输公司,也有个人车主,且商用车车型种类非常之多,工况差别也较大,因此商用车自动驾驶方案更偏定制。商用车自动驾驶赛道的有智加、挚途、赢彻、图森未来、千挂科技、三一海星智驾、陕汽、德创未来等。千挂科技、挚途能查到公开资料较少,挚途内部技术开发人员称也有预研BEV+多任务学习方案,但目前还没量产上车。智加据CICV报告及其他演讲资料,推测其自动驾驶方案既有BEV方案,也有传统后融合方案。图森未来当前主要布局高速物流,方案以BEV为主,其他商用车赛道自动驾驶公司技术方案均以第一代多传感器目标级后融合方案为主,整体上技术栈落后乘用车近一代。
2.商用车、乘用车自动驾驶方案分析目标选择
为简要介绍当前自动驾驶技术方案构成与趋势,本文精选了三个代表性的自动驾驶公司介绍其技术方案及其商用化布局,其中乘用车自动驾驶方案选择了极具代表性的特斯拉和毫末智行,特斯拉技术方案资料完善,是典型的第二代BEV+Transformer为主的自动驾驶方案。毫末智行技术预研超前,属于最早一批在量产自动驾驶方案中引入基于大模型的通用自动驾驶控制器DriveGPT、部分端到端技术的科技公司(上海人工智能实验室在端到端、部分端到端自动驾驶技术研究方面较为超强,感兴趣读者可以UniAD为线索进行查阅)。
商用车自动驾驶方案本文选择了赢彻,赢彻具体资料参考其于2022年9月发布的《自动驾驶卡车量产白皮书》,但该材料具体方案欠缺,大部分方案只是常识性介绍,可参考性不大,但赢彻材料胜在完整性较高,所以本文以赢彻为例简要介绍下商用车自动驾驶系统方案。赢彻重卡自动驾驶满配采用7V3L5R(V代表相机,L代表激光雷达,R代表毫米波,7V3L5R代表车辆配备了7个相机,3个激光雷达,5个毫米波雷达),但这种方案目前缺少挂车角度测量传感器,基本不能进行倒车控制相关的应用开发,因此不适合实际大多数园区落地场景,因为园区实际落地场景基本上都包含倒车场景(进出仓库、装卸货厂房等)。此外,受商用车车型、尺寸限制,赢彻方案相机重叠区域较小,至少在视觉上难以实现BEV感知框架。
3.商用车、乘用车自动驾驶方案分析
本文将分控制器、传感器配置,系统架构,感知、定位模块,规控模块四个部分进行介绍,同时也会介绍一些当前较为前沿且实车效果较好的学术方案,如UniAD。
3.1 传感器配置

图1 赢彻自动驾驶重卡采用3激光雷达,7摄像头,5毫米波雷达(7V3L5R)传感器配置
赢彻传感器采用7V3L5R配置(图1),较适合干线物流智能驾驶辅助,赢彻也在推广其自动驾驶方案时侧重其在高速、干线上的表现,其线下经常举办干线智驾体验活动。但如上文所说赢彻这套传感器方案不适合园区L4级自动驾驶落地,也不适合BEV感知框架,更像是传统基于目标级后融合的传感器配置方案,根据实际商用车特点,若要比较符合BEV框架,其大概要用到11V的方案。而若要适应商用车大多数园区落地场景,最小传感器配置应为3V4L4R(采用后融合方案)或11V2L4R(采用BEV方案),这两个方案里均考虑了对主挂夹角的测量(使用1激光雷达)。赢彻当前自动驾驶方案硬件成本初步估计在5-7万之间。乘用车由于车型尺寸较固定,且相对较小,其传感器配置相对较统一,业界周知的特斯拉是采用8V纯视觉的方案(图2)。根据毫末智行2023年10月第九届毫末AI Day资料,毫末目前包括跨层记忆泊车、高速/城市NOH、全场景避障、全场景辅助功能的最高配的自动驾驶方案采用11V1L1R12S(11相机,1激光雷达可选,1个毫米波,12个超声波)的传感器配置(图3)。据毫末方面称该套方案包括控制器总成本可控制在1万元以内,这相比商用车,或者说后融合方案相比BEV方案即第一代自动驾驶方案相较于第二代自动驾驶方案成本具有巨大优势,这也是为什么广大乘用车车企都不惜重金研发第二代自动驾驶方案的原因。
其他感知方案,如小鹏G6传感器方案为11V2L5R12S,问界M5 EV智驾版采用11V1L3R12S方案。总体上,自动驾驶传感器均以相机为主,一般7V-11V,纯视觉方案较少,以相机+毫米波(1-5R)+激光雷达(1-3L)多传感器融合为主其中基于BEV+Transformer技术框架的自动驾驶方案可减少激光雷达到1颗或完全不需要激光雷达,在成本上具有较大优势。
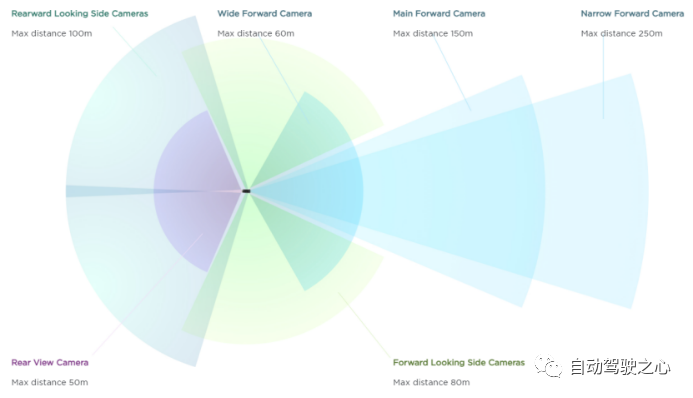
图2 特斯拉纯视觉(9V)传感器方案

图3 毫末智行高配自动驾驶传感器方案及功能
3.2 控制器方案

图4 左:赢彻控制器效果图;中:特斯拉HW4.0控制器实物图;右:毫末智行8000元级控制器效果图
图4为赢彻、特斯拉、毫末智行三家当前自动驾驶控制器半实物效果图(特斯拉为实物图)。特斯拉HW4.0控制器包含20个CPU核心3个NPU,信息娱乐模块APU和GPU集成在了一块PCB板上。其控制器提供两块FSD芯片,其中一块可以作为备份算力。信息娱乐和智能驾驶分别部署在两个处理器上,实现了功能隔离和安全保障。从特斯拉控制器CPU配置可以看出当前特斯拉自动驾驶系统对CPU的算力需求仍比较大。根据笔者实际开发经验,即使intel 8700 CPU,操作系统使用ubuntu,在处理4路激光雷达,4路以上相机,3路以上毫米波,再加上当前较多依赖CPU算力的SLAM算法,其CPU占用便会达到90%以上,系统也会卡顿,因此目前CPU算力也是自动驾驶系统必须关注的性能参数之一,当前Nvidia的Orin 254TOPS算力SOC自带12个A78核,其中11核可用,CPU算力228K DMIPS,目前基本满足7V4L3R传感器配置下的功能开发。
毫末智行毫末控制器基于高通Snapdragon Ride平台,采用SA8540P SoC+SA9000的组合,其中SOC芯片8540包括CPU+GPU,深度学习异构芯片9000。控制器支持接入6路千兆以太网,12路800万像素摄像头,5路毫米波雷达,3路激光雷达,单片功耗75w,单板算力360Tops,4板联合支持升级到1440TOPS. 安全冗余芯片为英飞凌TC397,可以做 L1/L2级别的降级控制,也可以满足当前L3以及后续L4/L5等全场景自动驾驶功能的实现。

图5 赢彻自动驾驶控制器架构
综合各家量产自动驾驶控制器硬件配置、软件架构,以赢彻控制架构(图5)为例,可得出当前量产自动驾驶控制器一般具备以下特征:
量产自动驾驶控制一般包括通用计算域(CPU),模型加速域(NPU,GPU等支持深度学习模型加速的运算处理单元),安区冗余控制域,及各模块间的通信模块(一般为交换机芯片)。如图6为天准科技(TZTEK)一款面向L2+/L3的自动驾驶域控制器,其通用计算域采用国产E3+X9U处理器,模型加速域采用地平线J5 SOC,J5、E3、X9U各模块间通过一颗RTL9068 和一颗 RTL9072 交换机进行连接,该控制器同样支持安区冗余控制功能。
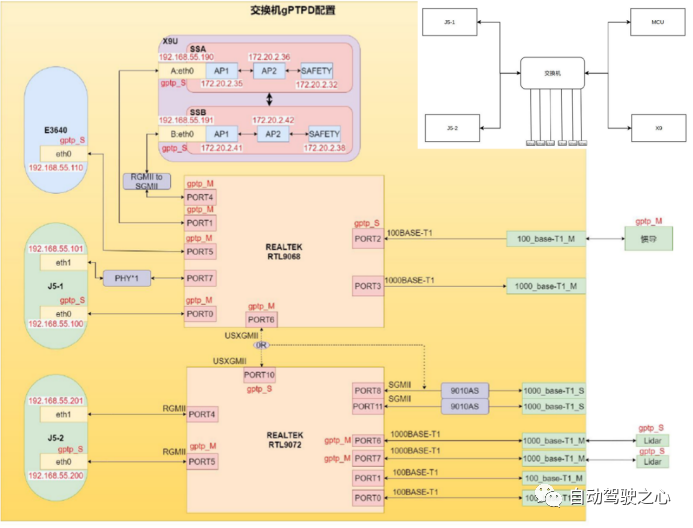
图6 天准L2+/L3全国产自动驾驶控制器(右上角为连接拓扑图)
3.3 系统架构
当前自动驾驶系统由于大算力、高吞吐量、多平台适应需求增强,逐步在借鉴云计算领域较为成熟的框架或技术,如硬件虚拟化、容器化,但这些技术一般为基础支撑技术,所以在各大科技公司的自动驾驶系统一般不会着重介绍,但包括华为、百度在内的大批公司都已经在使用相关技术以提升自动驾驶系统多平台适应能力,实现算力与硬件分离,整车软件系统服务化,提高系统功能或服务动态部署能力。
赢彻科技的自动驾驶系统架构较为典型(图7),其自动驾驶系统采用硬件层、系统软件层、应用软件层三层架构。硬件层即包括物理层的控制器、传感器实体、车端执行器等部分。系统软件层则提供中间件支持,不同算力平台的硬件虚拟化,不同理想传感器抽象及车辆抽象,并且提供包括进程监控、数据记录等在内的安全管理服务。应用层则负责实现感知、定位、规划、控制等上层功能。
赢彻科技自动驾驶系统采用第二代自动驾驶方案,传感器采用7V3L5R配置,感知系统采用基于BEV框架的多任务感知模型,地图与定位系统采用惯导等硬件融合定位和基于算法的多特征融合定位方法,具有重感知轻地图的特征。决策控制也引入了结合神经网络和模型预测控制的方法。
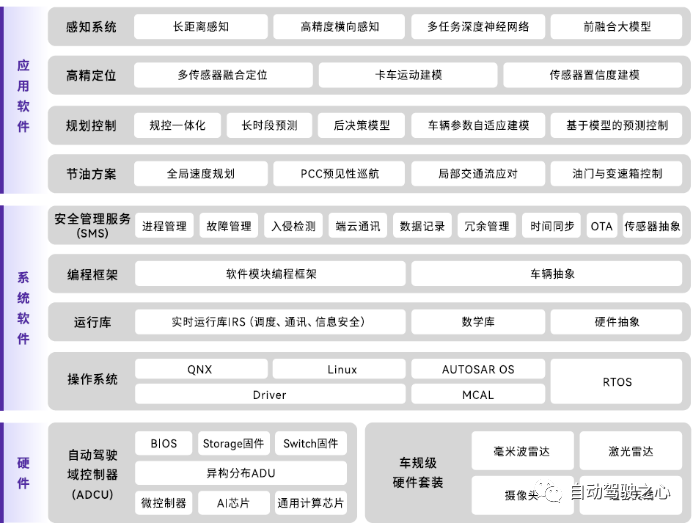
图7 赢彻科技自动驾驶系统架构
总体上赢彻自动驾驶系统架构虽然已较为完善,但仍没有解决不同业务系统环境依赖和干扰的问题。理想的自动驾驶系统架构应如图8所示,架构采用分布式云计算框架,基于硬件虚拟化和传感器抽象,实现功能开发和底层软硬件分离、算力和硬件分离。为实现自动驾驶功能不同平台快速移植、适配、部署及自动化刷写、部署,自动驾驶各业务模块采用基于容器化的开发方法,以实现批量部署、自动化运维、各业务系统服务更新、OTA。

图8 理想自动驾驶量产框架
自动驾驶底层系统框架其实本质解决的问题类似,无非实现软硬件分离,算力硬件分离,以及解决各业务系统环境依赖和干扰的问题,因此其系统框架是具有共通性的,但自动驾驶应用层算法的系统架构则各家方案里区别较大,有传统的目标级后融合框架,也有当前使用最为广泛的多任务学习BEV框架,也有较为前沿的端到端或部分端到端自动驾驶框架。
目标级后融合框架最为经典,实现也较为容易,各模块间耦合较松,感知模块融合相机、激光雷达、毫米波雷达检测或聚类算法,输出目标动静态类别、目标物类型、位置、速度等信息,送入预测模块对动态目标的轨迹、意图进行预测,决策规划模块接收预测结果、感知结果、定位、高精度地图信息,根据目标信息和局部环境信息输出位置、速度规划,控制模块根据输入的轨迹速度,控制线控底盘执行器实现轨迹、速度跟踪,最终达成任务关于位置和姿态的要求,目前后融合框架由于成本较高、性能一般,只有极少数公司或有特殊场景需求的军方单位在使用,如慧拓、千挂、陕汽、小米等。
特斯拉作为第二代多任务BEV学习的自动驾驶框架变革的发起者(2021年),其技术框架较为典型,当下仍具有较大参考价值(图9)。2021年特斯拉自动驾驶以多任务感知模型为基础,后接基于动态交互树的无碰撞轨迹生成算法,再基于规则和优化的方法从舒适性、人类偏好角度出发对轨迹进行优选,再通过控制器进行轨迹跟踪。该框架的主要贡献是实现了基于共享backbone进行目标检测、车道线预测等多任务感知模型的实车。

图9 特斯拉2021公布的基于共享backbone多任务感知的自动驾驶技术框架
特斯拉在2022-2023又进一步公布了其第二代基于BEV的自动驾驶技术框架(图10),该框架取消了传统自动驾驶运动预测相关模块,而以Occupancy预测即一般障碍物占用预测(体素占用预测)模块取代。该技术为后续各科技公司、研究机构最先进的自动驾驶框架都提供了参考,如2023年CVPR Best Paper中也将occupancy作为部分端到端自动驾驶框架规控模块的输入特征之一,并在数据集上取得了SOTA的成绩,实车也取得了不错的效果。
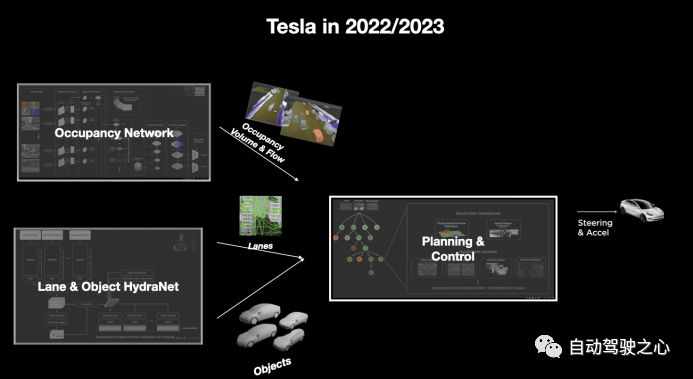
图10 特斯拉2022/2023采用Occupancy预测模型的自动驾驶系统技术框架
而随着大模型技术在行业内的应用加深,也有如毫末智行、百度、上海人工智能实验室等先行者对基于大模型的通用自动驾驶框架、端到端或部分端到端自动驾驶框架技术进行了探索,图11为毫末智行DriveGPT的技术框架,其先将不同视角的相机图像通过基于share backbone提取特征,再通过transformer模型生成BEV视角下的时空融合BEV特征(4D Encoder),后续Decoder通过语义地图重建、3D目标检测、运动预测等基于transformer的多任务感知头输出环境感知结果,系统再结合自动驾驶任务目标、车辆CAN反馈的车辆状态信息输入基于提示词和具有背景知识的大语言模型LLM和驾驶策略生成模型生成车辆的控制序列,最后通过大量的人类驾驶数据训练DriveGPT模型实现模型性能的提高。最终实现效果是基于DriveGPT不仅可以生成车辆的控制序列,也可以同步以自然语言的形式输出系统是基于哪些交通元素或事件生成的当前控制序列,该思路在UniAD工作中也有所体现。
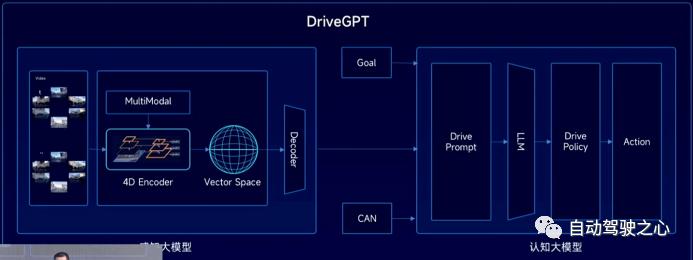
图11 毫末智行通用自动驾驶控制系统框架-DriveGPT
3.4 感知、建图与定位
当前自动驾驶方案感知部分共同点很多,一般都是share backbone后接多任务感知头,share backbone网络以RegNet/ResNet+FPN类网络居多,FPN主要是为了输出不同尺度特征图,增强后续模型对于尺度不同目标的适应能力。赢彻多任务感知框架信息有限只有基本框架(图12),特斯拉感知框架则展示了其多任务感知模型的主要技术。
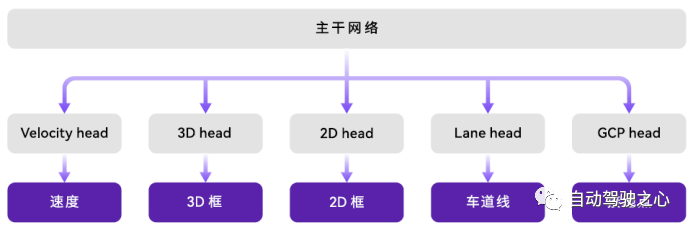
图12 赢彻多任务感知框架

图13 特斯拉HydraNets多任务感知模型架构
特斯拉多任务感知模型-HydraNets(图13)的share backbone使用了RegNet,RegNet是一种新型的神经网络,由何恺明团队提出,RegNet相对于ResNet的优势在于其设计更加简单易懂,同时可以应对高计算量的情况。RegNet在性能上表现突出,比如在ImageNet数据集上,RegNet在所有复杂度指标下,都有了较大的改进。在类似的条件下,性能优于EfficientNet,在GPU上的速度还提高了5倍。
特斯拉多任务感知模型的Neck网络采用了BiFPN(Bidirectional Feature Pyramid Network)网络,BiFPN是一种特征金字塔网络,可以实现简单而快速的多尺度特征融合。BiFPN结合了EfficientNet的模型缩放技术,可以用于检测器的backbone等网络。
Decoder Trunk接受来自Neck网络输出的不同尺度特征后,根据不同的任务,有不同的任务Head。Decoder通常包含upsampling部分和通常使用基于卷积层的模型如ResNet/RegNet的Trunk部分,当然当前即2023年多任务感知模型的decoder部分均已采用基于Transformer的网络模型。decoder之后cls、reg和attr是多任务head。cls head负责图像目标检测、分类。reg head负责预测图像中物体的位置。attr head负责检测和分类物体的属性,例如颜色、形状和大小。HydraNets中不同任务heads可以单独微调,具有较高灵活性。
2022年末时,特斯拉在HydraNets基础上增加了一般障碍物预测模型即Occupancy Network(图14),模型输入为多视角的相机图像序列,同样经过share backbone网络,模型输出时空间体素的占用概率即Occupancy Volume,体素占用趋势预测即Occupancy Flow,该方法无需识别障碍物,可以有效应对一般障碍物、异性障碍物情况,实际测试效果较好,目前国内各车企也均已跟进。

图14 特斯拉Occupancy Network模型

图15 小鹏汽车的XNet感知框架
同样国内具有代表性的自动驾驶技术汽车公司-小鹏汽车的感知架构XNet(图14),也采用了类似特斯拉的架构,区别是,
(1)小鹏XNet针对动静态目标采用了两种模型进行多种类目标的识别,没有像不同类别采用多个任务head。此外,小鹏多任务感知模型输入为图像,意味着XNet之外还有激光雷达、毫米波信息的融合,以增加尺寸、速度估计的准确度,所以小鹏技术架构是视觉BEV+激光雷达、毫米波雷达多传感器融合的技术框架。当然还存在另一种可能性,即BEV框架下处理的路径长度一般在100m,对于150m以上的感知需求需要通过其他传感器进行特殊处理(如与BEV感知结果进行目标级后融合),如远距激光雷达、毫米波雷达、长焦相机等。
(2)XNet1.0大概率还没有增加Occupancy预测模型,使用Occupancy模型意味着后续规控的技术框架也会有较大的变动。因为Occupancy的输出结果(图16)与获取目标种类、速度等信息的感知方法输出结果相差较大,其更利于无碰撞轨迹的生成,而不利于传统规控方法。

图16 Occupancy模型输出体素占用结果
国内目前毫末智行对于新技术的跟进速度较快,但其自动驾驶方案量产进度一直表现不佳。毫末智行感知方案相较于XNet更接近特斯拉总体感知方案,特斯拉当前推测其FSD已是完全基于无高精地图的方案,毫末智行在其AI Day上的相关材料(图17)也表明毫末智行的感知框架在进行目标感知和运动预测同时,也在进行语义地图的实时重建。毫末感知方案采用了视觉图像和激光雷达点云融合生成BEV特征的方案,其首先对激光雷达数据进行体素化处理,相当于对数据进行降采样,然后再通过点云特征处理的经典模型pointPilars模型提取点云特征,然后和基于BEV Transformer处理的视觉BEV特征相加后作为某些某时刻输入,通过构建多个历史时刻的输入丰富模型对于上下文关联特征的学习,从而优化模型模板检测、长时长语义地图生成及运动预测的输出,输出模型均采用基于transformer的decoder模型实现输入到目标输出特征的映射学习。

图17 毫末智行感知、地图生成多任务模型
建图、定位方面方面,目前国内多数车企还是以高精地图方案为主,赢彻自动驾驶已量产方案极大概率完全依赖高精度地图,可能采用图商地图盒子方案提供主要干线地图信息。华为、毫末、元戎启行有资料介绍其基于无图的智驾方案,无图智驾方案也是目前各大公司竞争的焦点,主要体现再智驾开城的速度上,一般对于高精地图依赖越小,其智驾方案开城速度则越快。但鉴于在线高精地图实时生成技术仍未普及,为了确保安全与智驾功能道路覆盖率,目前所有已量产的智驾方案仍对高精地图依赖较重,高速、干线、主要城区路段仍以高精地图为主,只有在特定功能,如代客泊车、自动泊车等小区域场景下才会使用实时建图的方案,或者以实时生成的地图作为高精地图的补充,以避免高精地图和实际道路不符的情况,如B站有测评视频显示小鹏在开启城区领航时不能识别道路边沿,或出现车身即将剐蹭桥梁支撑柱等情况,这表明当前小鹏自动驾驶还是以高精地图为主,并没有通过实时地图生成技术对高精地图进行修正,而相比较华为ADS系统则能够很大程度避免此类情况,也证明了华为在基于高精地图进行规控的同时还会基于在线生成的地图对规控进行调整。特斯拉FSD则是目前唯一完全不基于高精地图的智驾方案。
特斯拉在线地图生成主要包括车道线生成(识别)模型和车道线拓扑结构预测两部分。模型基本结构与感知部分模型近似,均为原始图像输入接share backbone,即RegNet,再接FPN以产生不同尺度特征图,之后再接基于transformer的decoder以实现车道线生成,车道线拓扑结构预测。
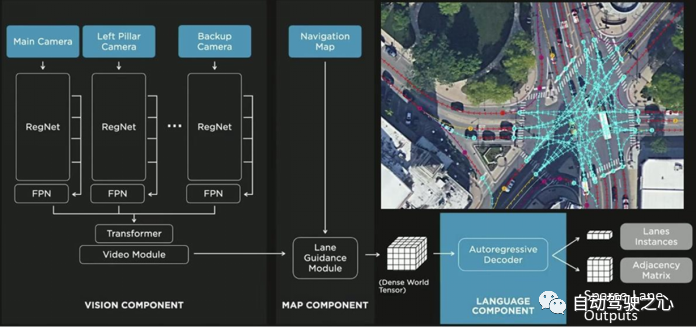
图18 特斯拉车道线生成、道路拓扑结构预测方法
在生成车道线后,在动态交互场景仍不足以支撑决策系统,如在路口处需要避让行人,在车道合并(fork)处需要执行汇车操作等,因此还需要对车道线的拓扑结构语义进行识别或预测(图19)。特斯拉对每一个车道线片段Vector序列,通过由粗略到精细的两个级联预测head预测特定功能车道线起始位置,再通过拓扑结构预测head预测当前后继车道线片段是start(起点),continue(延续点),fork(合并点),还是end(终止点),生成该车道线片段的拓扑语义描述序列即“Language of Lanes”。
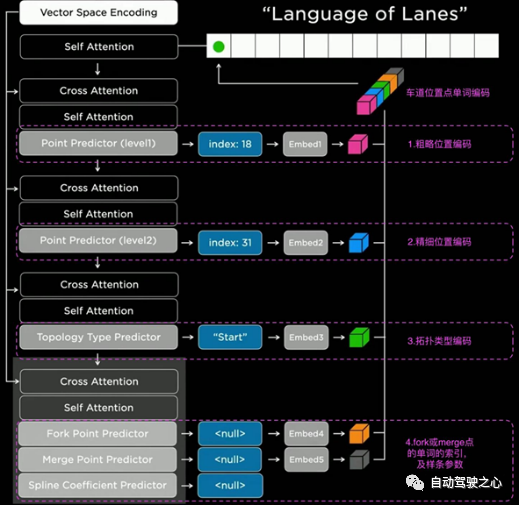
图19 特斯拉道路拓扑预测/识别的LANGUAGE COMPONENT模块
百度Apollo 团队2022年也介绍了其基于在线感知和多源地图融合的在线地图生成技术,其通过车端感知输出道路可行使区域分割、地图要素实例、地图要素分割、地图要素矢量化等结果,结合多源地图如高精地图、众源地图,实现实时在线地图实时生成,以避免高精地图更新慢、部分路段高精地图与实际不符等情况。其主要技术栈也是基于BEV Transformer方法对视觉、激光雷达输入进行特征提取,再通过基于Decoder模型学习生成相应的地图元素。
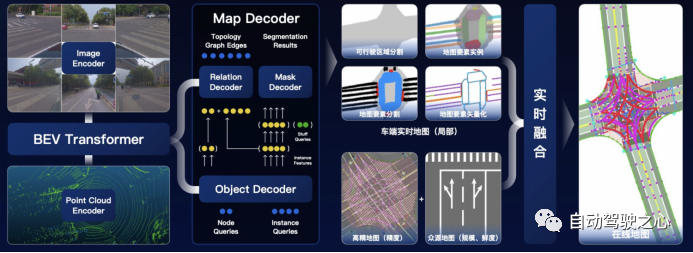
图20 百度基于车端感知数据和多源地图融合的在线地图生成技术(2022年)
自动驾驶定位技术目前各家方案相似,均是在GNSS+IMU+轮速计基础上,增加基于特征定位或SLAM,实现多源融合定位。根据赢彻定位系统基本框架(图21),其采用了基于特征和GNSS/IMU的融合定位方法,一般车企也都采用类似方法。GNSS(GPS、北斗)可以提供绝对位置定位,但在遮挡环境下如隧道内、厂房内存在信号不稳定或丢失问题。基于IMU、轮速计、特征定位则会随着定位时长误差会产生累计,因此一般定位系统均需要定期基于GNSS定位校准总体定位准确度,在GNSS信号不好位置采用基于惯导和特征融合的定位。毫末智行OverlapTransformer 即是面向LiDAR-Based Place Recognition的基于特征和transformer模型的定位方法(图22)。
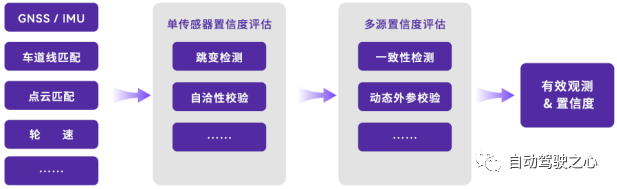
图21 赢彻定位系统基本框架

图22 毫末智行面向激光雷达位置识别的OverlapTransformer模型
目前感知和建图、定位的界限变得更加模糊,部分在线HDMap生成模型和感知模型共用一种框架,而Occupancy的出现则提供了另一种对于异形未知障碍物处理的方法,总体上感知、建图、定位具有以下三个趋势:
(1). 统一BEV框架,基于share backbone的多任务感知、端到端地图生成等模型,基于transformer的编码器-解码器架构是目前千亿车企自动驾驶通解。
(2). 一般障碍物预测即Occupancy占用预测正在取代传统轨迹、语义预测,成为感知模块重要部分。
(3). 重感知、轻地图、实时地图生成方案因为无需高精度地图,灵活度更高,成为毫末、特斯拉、华为等头部车企自动驾驶系统首选方案。
3.5 决策规划与控制
截至到2022年,规控系统一直都是优化、搜索方法占主导地位,路径搜索有A* ,D* , 混合A* 等,轨迹生成有EM Planner、Lattice Planner、贝塞尔曲线等。后面随着大模型技术和端到端/部分端到端技术的发展,规控系统在原有优化、搜索方法基础上也引入了更多基于transformer大模型方法、部分端到端方法。
赢彻据称采用了规划控制一体化架构(图23左侧),采用基于模型控制的方法实现卡车横纵向控制,采用神经网络对交通参与者的行为进行长时预测(图23右上)。架构中也提到了通过模型辨识方法来获得车辆加速度响应、转向响应等车辆特性描述模型,规控系统在感知结果、车辆模型基础上进行车辆横向位置、纵向速度的控制。
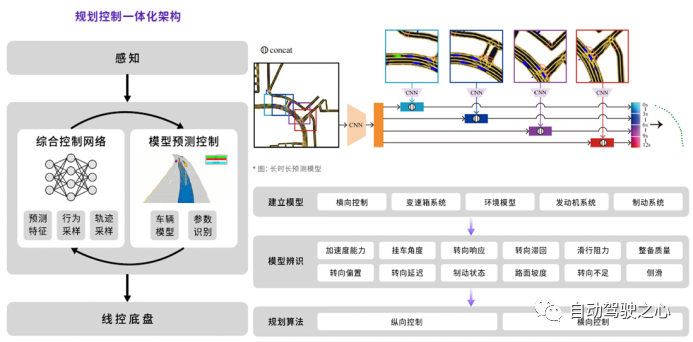
图23 赢彻规控系统架构
特斯拉第一代FSD的规划与控制部分接收感知模块动静态信息,Occupancy信息,采用一种动态交互式行为树加轨迹优化方法生成满足避障,舒适等约束的轨迹,再将生成轨迹输入轨迹评分模块,从碰撞、舒适性、以及人类偏好角度对轨迹进行优选(图25)。
一般自动驾驶对于轨迹的表征包括8个维度,即:
位置,Heading, 速度,横纵向加速度,横纵向jerk(位置的3阶导)。
传统多物体联合轨迹优化方法需要找到自车和他车、行人等各自的轨迹,使得所有物体都能尽可能的抵达goal,同时横纵向jerk尽可能小(舒适度),并满足所有轨迹最近距离大于安全距离约束,及早到约束和迟到约束(早到约束是指车辆不能在交叉口的前方等待,以避免阻塞交通。迟到约束是指车辆不能太晚进入交叉口,以避免与其他车辆发生碰撞)。特斯拉尝试了基于欧式距离启发式A* 和基于欧式距离加导航的A* 传统方法,所能实现最短规划耗时为50ms(20Hz),即图24中的A,B方法,右侧同时可视化了A,B方法的搜索结果。20Hz很难满足高速场景自动驾驶需求,为此,特斯拉采用了结合交互式MCTS(蒙特卡洛树搜索)和神经网络的方法,即图24中的C,算法迭代次数相较传统方法下降了两个数量级。一次轨迹生成约100us,推测其规划部分总用时小于10ms,可以满足各种驾驶场景下实时性需求。特斯拉具体做法如下:
(1). 根据道路拓扑选定目标点(goal),或者根据自然人驾驶数据先验得到goal点概率分布;
(2). 根据goal点,生成候选轨迹(优化算法+神经网络);
(3). 沿着候选轨迹rollout,得到终点状态,再基于碰撞检测、舒适性分析、介入概率以及与人类驾驶轨迹相似度给节点打分(图25底部),选择满足约束的最优轨迹。

图24 特斯拉路径路径搜索求解的三种方法

图24 特斯拉基于MCTS和Neural Planner的轨迹生成、选择方法
特斯拉控制算法没有看到相关介绍,推测应该以传统算法为主,如基于模型的MPC、串级PID等。总体上特斯拉方法更贴近量产和落地,但在最新技术的应用上,特斯拉并非响应最快的,当然特斯拉最新的FSD V12据称从感知到规控模块基本完全采用神经网络模型实现,但国内其实也有一些在新技术和自动驾驶结合方面探索的更为激进一些,如毫末智行、百度等。图11展示了毫末智行结合LLM即大语言模型实现的从驾驶场景自然语言推理,到车辆控制信号输出的通用的可解释自动驾驶控制器DriveGPT,该架构包含两个核心模型即多模态感知大模型(图25)、驾驶常识认知大语言模型(图26)。DriveGPT基于通用语义感知大模型提供的“万物识别”能力,通过构建驾驶语言(Drive Language)来描述驾驶环境和驾驶意图,再结合导航引导信息以及自车历史动作,并借助外部大语言模型LLM的海量知识来辅助给出并解释驾驶决策。
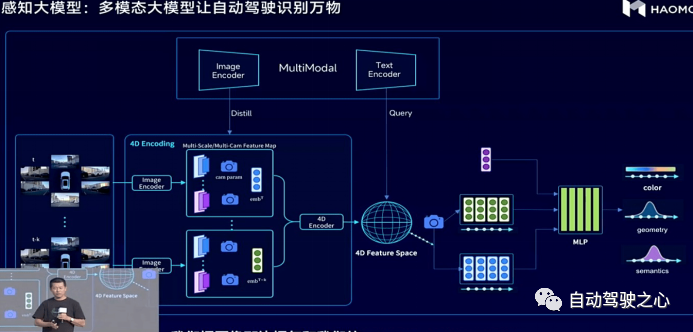
图25 毫末智行的多模态感知大模型

图26 毫末智行驾驶常识认知大语言模型

图27 DriveGPT驾驶场景理解、驾驶行为解释测试效果
图27给出了一个实际驾驶场景DriveGPT测试,通过感知大模型实现道路元素的分割和识别,然后通过大语言LLM模型推理当前场景的特征,各个车辆动作的含义。毫末通过引入大语言模型来解释驾驶环境,让AI自己解释自己的驾驶决策。通过构建自动驾驶描述数据,来对大语言模型进行微调,让大语言模型能够像驾校教练或者陪练一样,对驾驶行为做出更详细的解释。
国内也有一些结合传统方法和感知神经网络模型、规控神经网络模型的探索(图28),如小鹏的XPlanner,感知模型输出道路元素分割、识别结果,加上导航信息输入神经网络规划器以生成轨迹规划,最后再结合规则知识对轨迹进行选择或优化,最后输出到车辆控制模块。
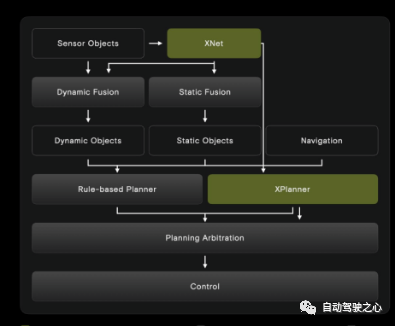
图28 小鹏汽车的XPlanner架构(图中绿色为神经网络模型,灰色为基于规则的模块)
总结,当前规控方案的特点如下:
(1). 目前多数规控方案结合端到端神经网络方法、基于知识的决策树或其他搜索、优化方法来简化建模等理论复杂度,并提升模型性能-数据量和数据质量关联度。
(2). BEV框架+大模型+人反馈强化学习(RLHF)+图像推理、自然语义理解 能够构建一种数据依赖较强的新一代自动驾驶规控架构。
3.6 部分端到端感知、规控一体模型
通过端到端方式实现更复杂的控制技巧学习其实早在19年谷歌就尝试过,在“Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection”一文中,Sergey Levine等人即提出一种基于机器人视觉输入和执行机构控制量到多目标抓取成功率的端到端学习框架(图29),当时业内戏称“机器人农场”,实际上也取得不错的效果,后续相关的工作还有Dex-Net 1.0/2.0系列工作,但这些工作由于本身应用场景单一,数据量较小,而且不同机器人间机构、作业任务又差异很大,因此很难获得大量高质量数据以助力模型表征能力突破,影响较小,基本仅限于机器人行业从业者之间。而自动驾驶,尤其是乘用车自动驾驶,由于其具有规模极大、驾驶任务高度相似,自动驾驶车辆结构及传感器配置又比较相似,再加上资本的关注,恰恰解决了上述机器人场景的所有痛点,因此以特斯拉为代表的科技公司,才能完成数据-模型飞轮的闭环,在全社会形成广泛的影响。
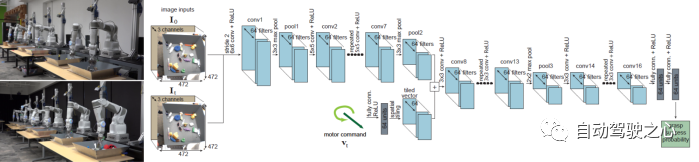
图29 谷歌机器人农场(左)和基于深度学习模型的感知输入、控制量输入到抓取成功率评价的端到端学习框架(右)
UniAD也是在这样的背景下诞生的,UniAD的诞生实际上具有比较多的突破,UniAD是近十年来CVPR唯一一篇来自中国的Best Paper。UniAD并非完全端到端的感知-控制量的框架,其人为设计了包括TrackFormer、MapFormer、MotionFormer、OccFormer等在内的多个中间过程,其最终Planner模块接收的输入也包括Track、Motion的Query特征,以及OccFormer输出的占用网格,同时Planner也接受自然语言控制指令的输入,如图中的“turn left”,模型最终输出的为最优的免碰撞轨迹。

图30 UniAD总体框架,最右侧引出图为Planner内部的框架原理图
UniAD与经典序贯模型不同在于,经典序贯模型各个模块有自己的评价指标,如目标检测模型优化目标包括类别准确率及IOU等,追踪模型优化目标包括MOTA、Mostly Tracked tracklets (MT)等,预测模块评价指标包括minADE、minFDE等,轨迹生成模块同时要考虑安全、舒适性(速度,加速度,及加速度一阶导等)等指标,控制部分需要考虑轨迹跟踪实时性、收敛速度等,因此各模块都会按照自己的评价指标对模型进行优化、改进,而UniAD不强调各个模块的评价指标最优,UniAD集成了感知、预测和规划等关键任务,并将这些任务整合到一个基于 Transformer 的端到端网络框架中,建立了一个由任务最终目标和Track、Map、Occ及控制指令构成的优化函数,通过标注数据优化各个模块的模型参数,这样模型就是始终以最终目标为优化对象而进行训练的。UniAD框架是业界首个将全栈关键任务整合到一个深度神经网络中的自动驾驶模型。实际基于不同方法、原理的端到端的自动驾驶技术工作其实也比较多(图31,End-to-end Autonomous Driving: Challenges and Frontiers),其中包括基于模仿学习方法(CNN E2E)、强化学习方法(Drive in A Day)等的工作,UniAD属于模块化端到端规划方法。

图31 端到端自动驾驶相关工作。图中按顺序列出了关键的里程碑工作,蓝色字体标识了不同类方法(Imitation Learning, Reinforcement Learning etc.)。其中代表性工作用粗体、插图进行了展示。顶部为CARLA Autonomous Driving Leaderboard中的Driving Score的评分,nuPlan Score类似。
4.总结
4.1 三代自动驾驶系统特点分析总结
三代自动驾驶系统在之前文章已系统介绍过了(B站,ID:不优秀博仕Hanker,文章题目:三代自动驾驶系统及主流科技公司自动驾驶技术方案简介),因为总结里要分析三代自动驾驶系统的优缺点,因此这里简要回顾下三代自动驾驶系统。第一代自动驾驶技术以后融合感知技术,高精度地图,基于惯导、GPS定位系统,预测模块,基于优化、搜索的规控等组成。第二代自动驾驶技术在第一代自动驾驶方案基础上,算法框架统一为BEV框架,感知采用了基于共享主干网(share backbone)的Transformer多任务感知模型,在输出目标感知的同时,几乎所有框架也都包含Occupancy预测,同时基于本地实时地图生成方法降低了系统对高精度地图的依赖,规控部分仍以搜索和优化方法为主。第三代自动驾驶系统和第二代框架相同,均是基于BEV框架,但感知、规控算法开始采用端到端的方式,并在训练通用自动驾驶控制器的同时,利用大规模语料数据训练模型的自动驾驶场景描述能力,实现系统在输出控制量的同时解释系统为什么要执行对应的操作,即对驾驶行为进行解释。代表性工作如前文介绍的DriveGPT。第一代自动驾驶系统主要模型参数量约百万级,算力需求在100TOPS量级;第二代自动驾驶系统主要模型规模突破千万级,部分基于Transformer的模型参数量接近亿级,算力需求约200-500TOPS;第三代自动驾驶系统由于引入大模型技术,初步估算参算量会达到百亿、千亿水平,算力需求最终则会达到2000TOPS。

图32 三代自动驾驶系统特征,当前主要科技公司自动驾驶系统架构估计,及三代自动驾驶系统对应模型参数与硬件需求估计。
第一代后融合串联自动驾驶系统具有以下问题:
(1).目标检测、行驶区域分割等模型均独立训练,存在特征提取重复问题;
(2).感知、定位、预测、规控等各模块针对不同的目标优化,而非最终驾驶目标;
(3).感知、预测、规控前后串连,会导致误差累积、传递。
(4).传统二维视角由于透视效应,物体可能出现遮挡和比例问题。
(5).时序信息缺少,遮挡处理、速度估计难度大。
第二代基于BEV多任务学习的自动驾驶系统的出现解决了特征重复提取、视角不统一、激光雷达和高精度地图依赖问题,但仍没有解决系统各模块未基于最终驾驶目标进行各模块优化问题,总体上第二代自动驾驶系统具有以下特点:
(1).检测、分割、障碍物预测等多个任务共享模型主干,特征复用、多任务并行出结果,容易扩展到额外任务,提升效率;
(2).BEV 3D视角,跨摄像头融合容易,时序融合容易,易预测、补全遮挡目标;
(3).模型结构单一,易优化,多平台部署难度小;
(4).纯视觉BEV方案在功能不降级前提下,可极大降成本,个人根据实际系统开发经验,单传感器配置一项即可降本至少20%。
(5).地图方面根据元戎启行数据,采用在线生成地图(SD Map具备道路几何拓扑、车道等信息,总体精度5-10cm,支持隧道、桥梁等路况),对比HD Map,在线SD Map成本为 100RMB每年,HD Map成本则在1000RMB每年;
(6).降低激光雷达依赖后,自动驾驶系统整体易支持国产域控平台,如前文提到的天准双J5域控,即可支持11V2L4R的BEV方案;
第三代端到端或部分端到端自动驾驶系统根据chatGPT的经验看,大概率是最优解,可能未来也是不同场景自动驾驶公司根据通用模型训练针对性的智驾DriveGPT。第三代自动驾驶系统两种类型具有以下特点:
(1).完全端到端
- 直接从感知输入中学习驾驶策略;
- 结构简单,在模拟器中表现良好;
- 现实世界中缺乏可解释性。
(2).部分端到端
- 引入实时地图生成、一般障碍物预测等中间任务,以协助规划;
- 引入自然语言驾驶场景推理,提高可解释性;
- 以最终任务协调所有子模块任务以实现安全、高效的驾驶任务学习。
4.2 基于自动驾驶各模块的分析总结
- (1).在系统硬件架构上,多核CPU,GPU,深度学习/神经网络单元,安全冗余芯片为控制器四个必要组成部分。
- (2).感知和地图:基于BEV+Transformer构建共享主干多任务感知模型,实现目标检测、运动预测、地图实时生成的重感知轻地图方案是未来2-3年内自动驾驶量产的核心框架。
- (3).定位:基于消费级导航地图、定位设备,融合多传感器特征定位是降低基于高精度地图和高精度惯导成本的重要方式。
- (4).规划:结合语言、知识大模型,结合端到端自动驾驶大模型和基于强化学习的反馈学习机制,构建能以自然语言方式实时描述、推理驾驶场景,能够基于驾驶目标整体优化的方案是未来重要方向。
- (5).控制:基于模型预测控制,基于模型作为先验,基于实际驾驶数据的无模型强化学习控制可能是解决多场景自适应控制的方向。
- (6.)算法架构:含部分人为设计的中间过程,结合自然语言场景理解,基于人反馈强化学习(RLHF)大模型架构的伪端到端自动驾驶框架会是未来重要方向。

原文链接:https://mp.weixin.qq.com/s/h4UCkF2sasuYZ5PExAIiGw