













AI 模型功能越来越强大,结构也越来越复杂,它们的速度也成为了衡量先进程度的标准之一。
如果 AI 是一辆豪华跑车,那么 LoRA 微调技术就是让它加速的涡轮增压器。LoRA 强大到什么地步?它可以让模型的处理速度提升 300%。还记得 LCM-LoRA 的惊艳表现吗?其他模型的十步,它只需要一步就能达到相媲美的效果。
这是怎么做到的?Raphael G 的博客详细说明了 LoRA 如何在提高模型推理效率和速度方面取得显著成效,并介绍了这一技术实现的改进及其对 AI 模型性能的重大影响。以下为机器之心对本篇博客不改变原意的编译和整理。

原博客链接:https://huggingface.co/raphael-gl
我们已经能够大大加快基于公共扩散模型的公共 LoRA 在 Hub 中的推理速度,这能够节省大量的计算资源,并带给用户更快更好的使用体验。
要对给定模型进行推理,有两个步骤:
1. 预热阶段,包括下载模型和设置服务 ——25 秒。
2. 然后是推理工作本身 ——10 秒。
经过改进,预热时间能够从 25 秒缩短到 3 秒。现在,我们只需不到 5 个 A10G GPU 就能为数百个不同的 LoRA 提供推理服务,而对用户请求的响应时间则从 35 秒减少到 13 秒。
下面让我们进一步讨论如何利用 Diffusers 库中最近开发的一些功能,通过单个服务以动态方式为许多不同的 LoRA 提供服务。
什么是 LoRA
LoRA 是一种微调技术,属于「参数高效微调」(parameter-efficient fine-tuning,PEFT)方法系列,该方法致力于在微调过程减少受影响可训练参数的数量。它在提高微调速度的同时,还能减少微调检查点的大小。
LoRA 的方法并不是通过对模型的所有权重进行微小改动来微调模型,而是冻结大部分层,只在注意力模块中训练少数特定层。此外,我们通过在原始权重上添加两个较小矩阵的乘积来避免触及这些层的参数。这些小矩阵的权重会在微调过程中更新,然后保存到磁盘中。这意味着所有模型的原始参数都被保留下来,使用者可以用自适应方法在其上加载 LoRA 权重。
LoRA(Low-Rank Adaptation,低秩自适应)的名称来源于上文提到的小矩阵。有关该方法的更多信息,可以参阅下方博客或原论文。

- 相关博客链接:https://huggingface.co/blog/lora
- 论文链接 https://arxiv.org/abs/2106.09685
下图显示了两个较小的橙色矩阵,它们被保存为 LoRA 适配器的一部分。接下来,我们可以加载 LoRA 适配器,并将其与蓝色基础模型合并,得到黄色微调模型。最重要的是,我们还可以卸载适配器,这样就可以在任何时候返回到原始基础模型。
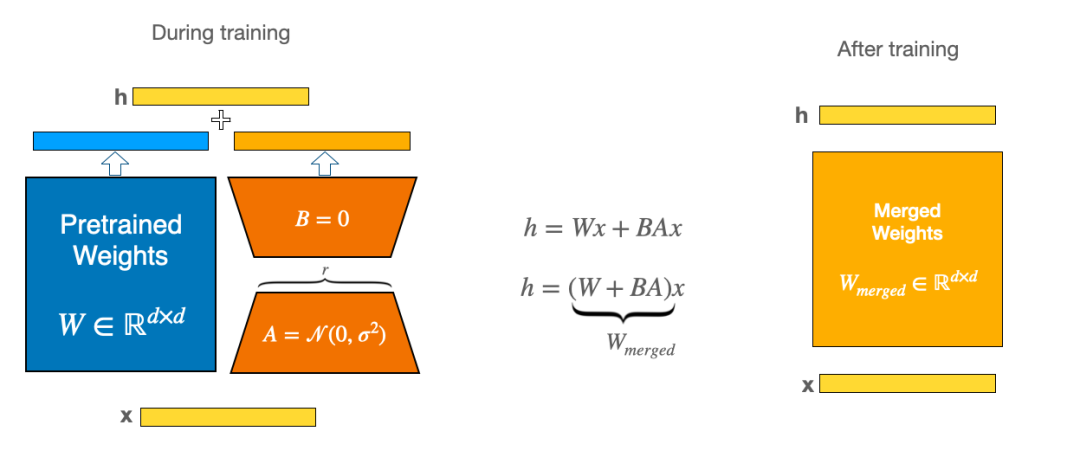
换句话说,LoRA 适配器就像是基础模型的附加组件,可以按需添加和卸载。由于 A 级和 B 级较小,与模型尺寸相比,它非常轻便。因此,加载速度要比加载整个基础模型快得多。
例如,被广泛用作许多 LoRA 适配器基础模型的 Stable Diffusion XL Base 1.0 模型 repo,我们会发现它的大小约为 7 GB。然而,像这样的典型 LoRA 适配器仅占用 24 MB 空间。
在 Hub 上,蓝色基本模型的数量远远少于黄色模型。如果能从蓝色快速切换到黄色,反之亦然,那么我们就有办法为许多不同的黄色模型提供服务,并且只需少数不同的蓝色部署。
LoRA 的优势
Hub 上拥有约 2500 个不同的公共 LoRA,其中绝大多数(约 92%)基于 Stable Diffusion XL Base 1.0 模型。
在这种共享机制之前,要为所有这些模型(例如上文图中所有黄色合并矩阵)部署专用服务,并至少占用一个新的 GPU。启动服务并准备好为特定模型的请求提供服务的时间约为 25 秒,此外还有推理时间,在 A10G 上以 25 个推理步骤进行 1024x1024 SDXL 推理扩散的时间约为 10 秒。如果一个适配器只是偶尔被请求,它的服务就会被停止,以释放被其他适配器抢占的资源。
如果你请求的 LoRA 不那么受欢迎,即使它是基于 SDXL 模型的,就像迄今为止在 Hub 上发现的绝大多数适配器一样,也需要 35 秒来预热并在第一次请求时获得响应。
不过,以上已成为过去时,现在请求时间从 35 秒缩短到 13 秒,因为适配器将只使用几个不同的「蓝色」基础模型(如 Diffusion 的两个重要模型)。即使你的适配器不那么火热,其「蓝色」服务也很有可能已经预热。换句话说,即使你不经常请求你的模型,也很有可能避免了 25 秒的预热时间。蓝色模型已经下载并准备就绪,我们要做的就是卸载之前的适配器并加载新的适配器,只需要 3 秒钟。
总的来说,尽管我们已经有办法在各个部署之间共享 GPU 以充分利用它们的计算能力,但相比之下仍然需要更少的 GPU 来支持所有不同的模型。在 2 分钟内,大约有 10 个不同的 LoRA 权重被请求。我们只需使用 1 到 2 个 GPU(如果有请求突发,可能会更多)就能为所有这些模型提供服务,而无需启动 10 个部署并让它们保持运行。
实现
我们在推理 API 中实现了 LoRA 共享。当在平台上对一个模型发起请求时,我们首先判断这是否是一个 LoRA,然后确定 LoRA 的基础模型,并将请求路由到一个能够服务该模型的共同的后端服务器群。
推理请求通过保持基础模型运行状态,并即时加载 / 卸载 LoRA 来服务。这样,你就可以重复使用相同的计算资源来同时服务多个不同的模型。
LoRA 的结构
在 Hub 中,LoRA 可通过两个属性来识别:

LoRA 会有一个 base_model 属性,这是 LoRA 建立的基础模型,用于执行推理过程中使用。由于不仅 LoRA 拥有这样的属性(任何复制的模型都会有一个),所以它还需要一个 lora 标签来正确识别。
数据展示
每次推理多花 2 到 4 秒钟,我们就能为很多不同的 LoRA 提供服务。不过在 A10G GPU 上,推理时间大大缩短,而适配器加载时间变化不大,因此 LoRA 的加载 / 卸载成本相对更高。
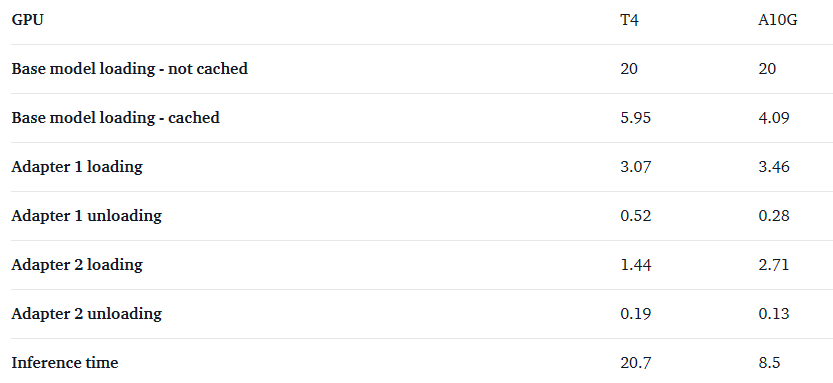
所有数字的单位为秒。
批处理如何?
最近有一篇非常有趣的论文,介绍了如何通过在 LoRA 模型上执行批量推理来提高吞吐量。简而言之,所有推理请求都将被批量收集,与通用基础模型相关的计算将一次性完成,然后再计算剩余的特定适配器产品。

论文链接 https://arxiv.org/pdf/2311.03285.pdf
我们没有采用这种技术。相反,我们坚持单个顺序推理请求。因为我们观察到对于扩散器来说,吞吐量不会随着批处理规模的增加而显著提高。在我们执行的简单图像生成基准测试中,当批量大小为 8 时,吞吐量只增加了 25%,而延迟却增加了 6 倍。
关于加载 / 卸载 LoRA 的内容,请阅读博客原文。



















