













2023年的大语言模型(LLM),让几乎所有人都燃起了热情。
现在大多数人都知道LLM是什么,以及可以做什么。
人们讨论着它的优缺点,畅想着它的未来,
向往着真正的AGI,又有点担忧自己的命运。
围绕开源与闭源的公开辩论也吸引了广泛的受众。
2023年的LLM开源社区都发生了什么?

下面,让我们跟随Hugging Face的研究员Clémentine Fourrier一起,
回顾一下开源LLM这跌宕起伏的一年。
如何训练大语言模型?
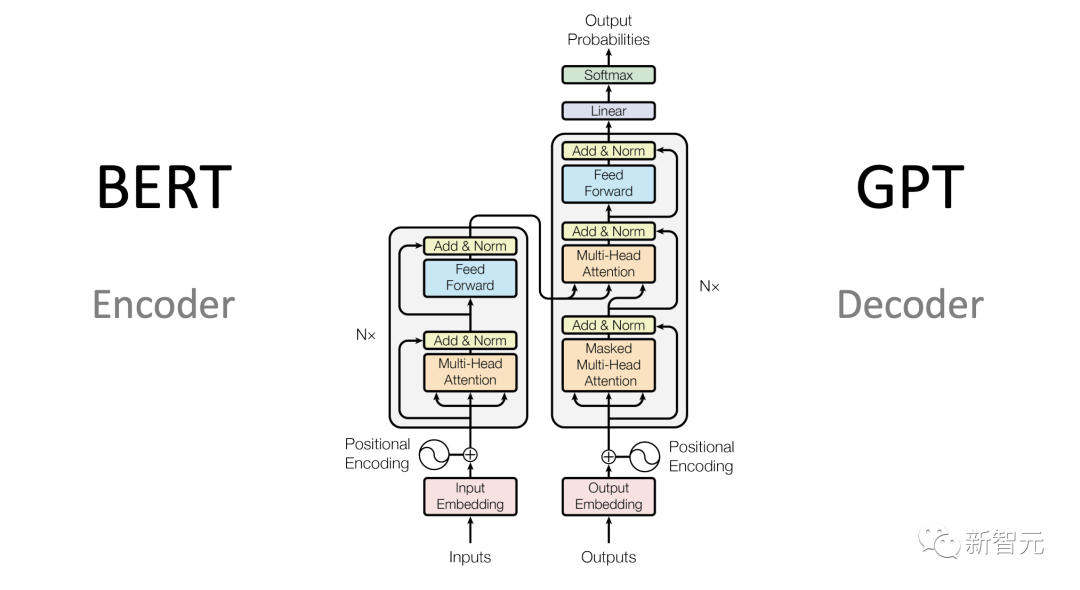
LLM的模型架构描述了具体实现和数学形状。模型是所有参数的列表,以及参数如何与输入交互。
目前,大多数高性能的LLM都是Transformer架构的变体。
LLM的训练数据集,包含训练模型所需的所有示例和文档。
大多数情况下是文本数据(自然语言、编程语言、或者其他可表达为文本的结构化数据)。
分词器(tokenizer)定义如何将训练数据集中的文本转换为数字(因为模型本质上是一个数学函数)。
文本被切分成称为tokens的子单元(可以是单词、子单词或字符)。
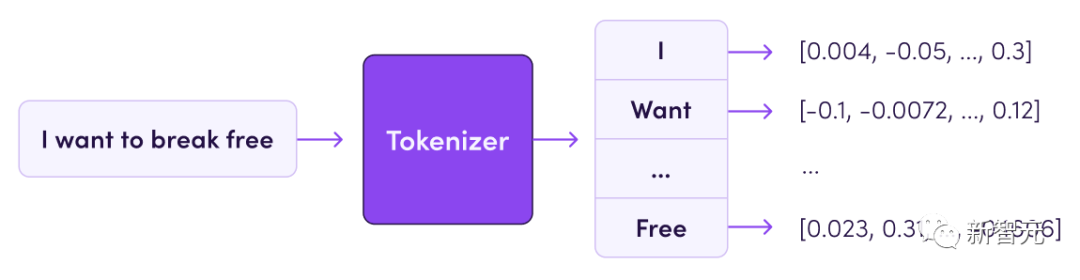
分词器的词汇量通常在32k到200k之间,而数据集的大小通常以它包含的tokens数量来衡量,当今的数据集可以达到几千亿到几万亿个tokens。
然后,使用超参数定义如何训练模型——每次迭代,参数应该改变多少?模型的更新速度应该有多快?
搞定这些后,剩下的就只需要:大量的算力,以及训练过程中进行监控。
训练的过程包括实例化架构(在硬件上创建矩阵),并使用超参数在训练数据集上运行训练算法。
最终得到的结果是一组模型权重,——大家讨论的大模型就是这个东西。
这组权重可以用来推理,对新的输入预测输出、生成文本等。
上面训练好的LLM也可以在之后通过微调(fine-tuning)来适应特定任务(尤其是对于开源模型)。
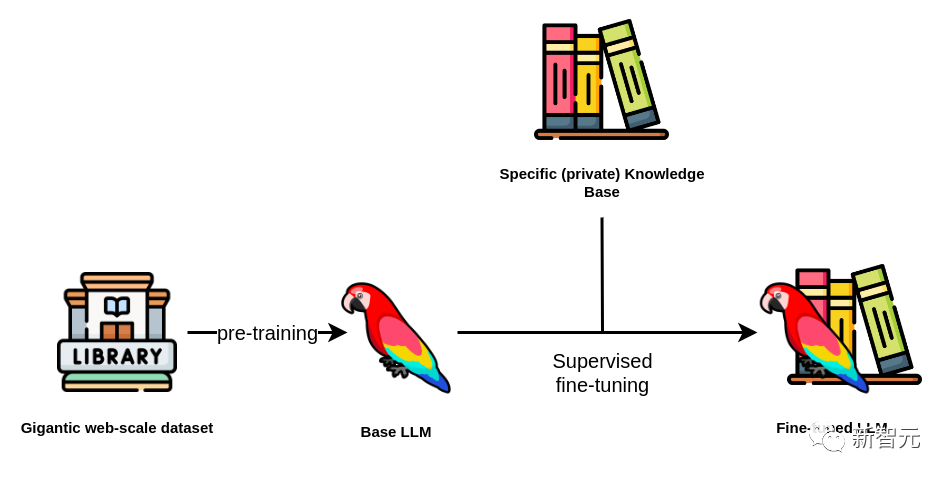
微调的过程是在不同的数据集(通常更专业、更小)上对模型进行额外的训练步骤,以针对特定应用程序进行优化。
比起从头开始训练一个大模型,微调的成本显然低得多——这也是开源LLM受到大家欢迎的原因之一。
从规模竞赛到数据竞赛
直到2022年初,机器学习的趋势是模型越大,性能就越好。
而且似乎模型的大小在超过某个阈值之后,能力会得到飞跃——有两个词语用来描述这个现象:emergent abilities和scaling laws 。

2022年发布的预训练开源模型大多遵循这种范式,下面举几个例子。
BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)是BigScience发布的一系列模型,由Hugging Face与法国组织GENCI和IDRIS合作,涉及来自60个国家和250个机构的1000名研究人员。这些模型使用decoder-only transformers,并进行了微小的修改。
系列中最大的模型有176B参数,使用350B的训练数据集,包括46种人类语言和13种编程语言,是迄今为止最大的开源多语言模型。
OPT(Open Pre-trained Transformer)系列模型由Meta发布,遵循GPT-3论文的技巧(特定权重初始化、预归一化),对注意力机制(交替密集和局部带状注意力层)进行了一些更改。
这个系列中最大的模型为175B,在180B的数据上进行训练,数据主要来自书籍、社交、新闻、维基百科和互联网上的其他信息。
OPT的性能与GPT-3相当,使用编码优化来降低计算密集度。
GLM-130B(通用语言模型)由清华大学和Zhipu.AI发布。它使用完整的transformer架构,并进行了一些更改(使用DeepNorm进行层后归一化、旋转嵌入)。
GLM-130B是在400B个中英文互联网数据(The Pile、Wudao Corpora和其他中文语料库)的标记上训练的,它的性能也与GPT-3相当。

此外,还有一些更小或更专业的开源LLM,主要用于研究目的。
比如Meta发布的Galactica系列;EleutherAI发布的GPT-NeoX-20B等。
尽管看起来越大的模型效果越好,但运行起来也越昂贵。
在执行推理时,模型需要加载到内存中,而100B参数的模型通常需要220GB的内存。
在2022年3月,DeepMind发表了一篇论文,研究了在给定计算预算下,用于训练的数据量与模型参数的最佳比率是多少。
换句话说,如果你只有固定的一笔钱可以花在模型训练上,那么模型大小和训练数据量应该是多少?
作者发现,总体而言,应该把更多的资源分配给训练数据。
他们自己的例子是一个叫做Chinchilla的70B模型,使用1.4T的训练数据。
2023的开源LLM
模型爆发
2023年开始,一大波模型涌现出来,每个月、每周、甚至每天都会有新的模型发布:
2月的LLaMA(Meta)、4月的Pythia(Eleuther AI)、MPT(MosaicML)、 5月的X-GEN(Salesforce)和Falcon(TIIUAE)、7月的Llama 2(Meta)、9月的Qwen(阿里巴巴)和Mistral(Mistral.AI),11月的Yi(01-ai),12月的DeciLM(Deci)、Phi-2(微软) 和SOLAR(Upstage)。
在Meta AI的LLaMA系列中,研究人员的目标是训练一组不同大小的模型,能够在给定的预算下具有最佳性能。
他们首次明确提出不仅要考虑训练预算,还要考虑推理成本,从而在更小的模型大小上达到更高的性能(权衡是训练计算效率)。
Llama 1系列中最大的模型是在1.4T数据上训练的65B参数模型,而较小的模型(6 B和13B)是在1T数据上训练的。

小型13B LLaMA模型在大多数基准测试中都优于GPT-3,而最大的LLaMA模型到达了当时的SOTA。不过,LLaMA是以非商业许可发布的,限制了社区的应用。
之后,MosaicML发布了MPT模型,具有允许商业用途的许可证,以及训练组合的细节。第一个MPT模型为7B ,随后是6月份的30B版本,均使用1T英语和代码数据进行训练。
在此之前,模型的训练数据是公开的,不过之后的模型就不再提供任何关于训练的信息,——不过最起码权重是开源的。
无处不在的对话模型
与2022年相比,2023年发布的几乎所有预训练模型都带有预训练版本和对话微调版本。
公众越来越多地使用这些聊天模型,并进行各种评估,还可以通过聊天的方式对模型进行微调。
指令微调(IFT)使用指令数据集,其中包含一组查询的提示和答案。这些数据集教会模型如何遵循指令,可以是人类的,也可以是LLM生成的。
使用LLM输出合成数据集,是完成指令和聊天微调的方法之一,通常被称为distillation ,表示从高性能模型中获取知识,来训练或微调较小的模型。
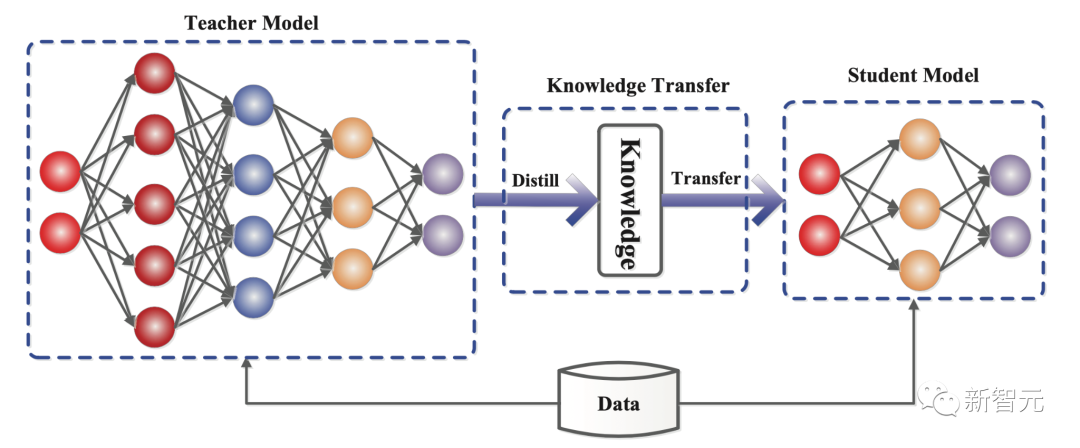
这两种方法都相对容易实现:只需要查找或生成相关数据集,然后使用与训练时相同的技术微调模型。
来自人类反馈的强化学习 (RLHF) 是一种特定方法,旨在调整模型预测的内容,与人类的喜好保持一致。
根据给定的提示,模型会生成几个可能的答案,人类对这些答案进行排名,排名用于训练所谓的偏好模型,然后使用偏好模型通过强化学习对语言模型进行微调。
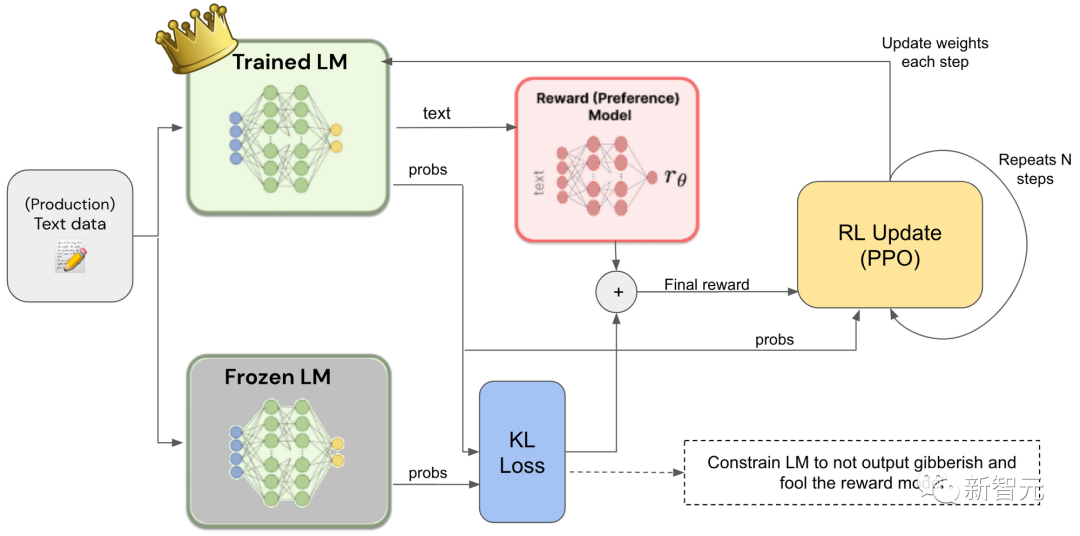
这是一种成本高昂的方法,主要用于调整模型以实现安全目标。
人们之后开发了一种成本较低的变体,使用高质量的LLM对模型输出进行排名,称为来自AI反馈的强化学习 (RLAIF)。
直接偏好优化 (DPO) 是RLHF的另一种变体,但不需要训练和使用单独的偏好模型。
DPO利用人类或AI给出的排名数据集,通过查看其原始策略和最佳策略之间的差异,来直接更新模型。
这使得优化过程变得简单很多,同时实现了差不多的最终性能。
社区在做什么?
在2023年初,已经发布了一些用于教学或聊天微调的数据集。
比如在人类偏好方面,OpenAI的WebGPT数据集、Anthropic的HH-RLHF数据集和OpenAI的Summarize。
指令数据集的例子包括BigScience的Public Pool of Prompts、Google的FLAN 1和2、AllenAI的Natural Instructions、Self Instruct(由不同隶属关系的研究人员生成自动指令的框架)、SuperNatural指令(微调数据的专家创建的指令基准)、Unnatural指令等。
今年1月,中国研究人员发布了人类ChatGPT指令语料库 (HC3),包含各种问题的人类与模型答案。
3月,斯坦福大学开放了Alpaca模型,是第一个遵循指令的LLaMA模型 (7B),还包括相关的数据集(使用LLM生成的52K指令)。
LAION(一个非营利性开源实验室)发布了开放指令通才(OIG)数据集,该数据集有43M条指令,既有数据增强创建,也有从其他预先存在的数据源编译而来的指令。
同月,LMSYS组织(加州大学伯克利分校)发布了Vicuna,也是一个LLaMA微调(13B),这次使用的是聊天数据——用户与ChatGPT之间的对话,由用户自己在ShareGPT上公开分享。
4月,BAIR(伯克利人工智能研究实验室)发布了Koala,一个聊天微调的LLaMA模型,使用了之前的几个数据集(Alpaca、HH-RLHF、WebGPT、ShareGPT),
DataBricks发布了Dolly数据集,包含15K手动生成指令。
5月,清华大学发布了UltraChat,一个包含指令的1.5M对话数据集,以及UltraLLaMA,一个对该数据集的微调。
Microsoft随后发布了GPT4-LLM数据集,用于使用GPT4生成指令,
6月,Microsoft研究分享了一种新方法Orca,通过使用大型模型的推理痕迹来构建指令数据集(解释它们的分步推理),
——社区用这种方法创建了Open Orca数据集,有数百万个条目, 并被用于微调许多模型(Llama、Mistral等)。
8月,中国非营利组织OpenBMB发布了UltraLM(LLaMA的高性能聊天微调),
9月,他们发布了相关的偏好数据集UltraFeedback,这是一个由GPT4比较的输入反馈数据集(带有注释)。
另外,清华大学的一个学生团队发布了OpenChat,一个使用新的RL微调策略的LLaMA微调模型。
10月,Hugging Face发布了Zephyr,这是一款在UltraChat和UltraFeedback上使用DPO和AIF的Mistral微调,Lmsys发布了LMSYS-Chat-1M,是与25个LLM的真实用户对话。
11月,NVIDIA发布了HelpSteer,一个对齐微调数据集,根据几个标准提供提示、相关模型响应和所述答案的等级,而Microsoft Research发布了Orca-2模型,是一个在新的合成推理数据集上微调的Llama 2。
开发方式
合并:极致定制
在典型的开源方式中,社区的里程碑之一是模型或数据合并。
模型合并是一种将不同模型的权重融合到单个模型中的方法,以将每个模型的各自优势组合在一个统一的单个模型中。
最简单的方法之一,是对一组共享通用架构的模型的参数进行平均,——不过需要考虑更复杂的参数组合,例如确定哪些参数对给定任务的影响最大(加权平均),或者在合并时考虑模型之间的参数干扰(并列合并)。
这些技术允许任何人轻松生成模型组合,并且由于现在大多数模型都是同一架构的变体,因此变得特别容易。
这就是为什么一些 LLM 排行榜上的模型会有奇怪的名字(比如llama2-zephyr-orca-ultra——表示llama2和zephyr 模型的合并,在orca和ultra数据集上进行了微调) 。
PEFT:指尖的个性化
有时,你可能没有足够的内存加载整个模型,以对其进行微调。但事实上,微调时可以不需要使用整个模型。
采用参数高效微调(PEFT),首先固定住一部分的预训练模型的参数,然后在其上添加许多新参数,称为适配器。
然后,对任务进行微调的只是(轻量级)适配器权重,比原始模型要小得多。
量化:模型无处不在
性能良好的大模型在运行时需要大量的内存,比如一个30B参数的模型可能需要超过66G的RAM才能加载,大多数个人开发者都未必拥有足够的硬件资源。
一个解决方案就是量化,通过改变模型参数的精度来减小模型的大小。
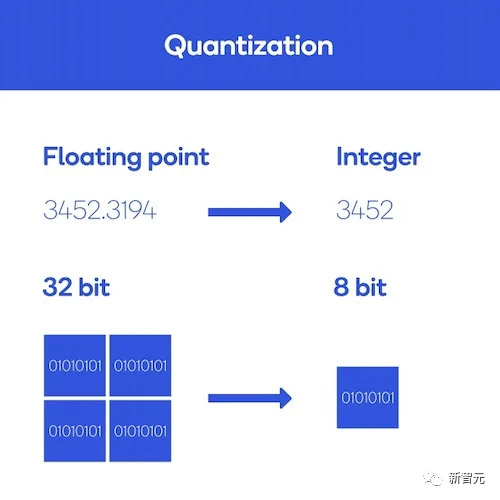
在计算机中,数字以给定的精度(如float32、float16、int8等)存储。
精度既指示数字类型(是浮点数还是整数)又指示数字的存储量:float32将浮点数存储在32位的内存空间中。精度越高,数字占用的物理内存就越多。
因此,如果降低精度,则会减少每个模型参数占用的内存,从而减小模型大小,这也意味着可以减少计算的实际精度。
而这种精度的损失带来的性能下降,实际上非常有限。
从一种精度到另一种精度的方法有很多种,每种方案都有自己的优点和缺点。常用的方法包括bitsandbytes、GPTQ和AWQ。





























