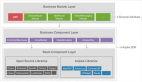
一、背景介绍
1、旧召回架构

上图左上侧部分是一般推荐系统流程,即先进行召回,再进行排序。左下侧部分是 OPPO 旧的召回架构,即先进行定向过滤,再经过截断策略,最后进行个性化召回。这里有两个问题,第一个是由于性能问题,不能做全量广告的个性化召回;第二个是由于个性化召回在截断策略的后面,这会导致个性化召回的效果受到影响。因此我们想通过工程和算法的改造,做到全量广告的个性化召回,提升平台整体的指标。另外,也希望能通过一个更好的多路召回机制,来提升整个广告播放的体验和生态。
2、新召回架构

上图左上侧部分是新的召回架构,最重要的变化是引入了 ANN,也就是近邻检索的能力。通过这个工程改造,支持了全量广告的个性化召回。
同时,我们重新设计了多路召回机制,即“单主路加多辅路”召回机制。单主路指的是主路用“面向最终目标的一致性召回”,这是一种 LTR 的方式。多辅路包括 ECPM 支路、冷启支路和一些其他支路。
ECPM 支路主要是为了弥补主路 LTR 不足。冷启动支路主要是对新广告进行冷启的扶持。
OPPO 通过“公平”和“效率”两方面进行冷启的扶持。“公平”方面,对于一些新广告,会有独立的流量供新广告进行随机的探索,这是一个公平的策略。“效率”方面,则通过算法找出未来有潜力的新广告,每一次请求都会有专门针对这些新广告的召回配额。通过这两种方式,提升新广告冷启的效果。
还有一些其他支路,主要是面向某一类特定的问题,或者是作为运营同学的中短期运营手段而存在的。通过切换架构及持续迭代,新召回架构带来了累积 15% 的 ARPU 提升,效果还是相当可观的。
接下来分享一下 OPPO 在主路召回模型上的一些业务实践和探索,主要从四个方面讲解:主路召回模型选型、离线评估指标建设、样本优化实践、模型优化探索。
二、主路召回模型选型
1、主路召回模型目标

首先介绍一下主路召回模型目标,我们将其拆解为三个方向:
- 一致性:首先,召回侧的打分标准要和下游保持一致(一致不等于一样)。同时,应满足激励相容的逻辑,即要与整个广告系统匹配,比如调价敏感性。
- 泛化性:指模型在未见过或者很少见过的数据上的效果。我们将其拆解为“共性”和“个性”。“共性”是指模型能不能学到普遍规律,以便推广到没有见过的数据上,比如推广到新广告、新用户上;“个性”是指模型能不能重视个体差异,尤其是数据很少的情况,比如长尾的广告和用户。
- 多样性:指降低召回的寡头效应,让下游链路见世面。大家可能在广告系统里面很少听到“信息茧房”的说法,但其实广告系统里也是存在“信息茧房”的。比如,如果精排见到的广告过于单一,那么精排可能对中长尾广告的预估偏差比较大。
2、从 Youtube 论文看召回选型

上面三个方向确定之后,接下来看一下有哪些可能的召回选型。
我们从 2016 年 Youtube 的经典论文看起,他们将推荐系统分成两个阶段,召回和排序。对于召回,他们以“点击且完播的概率”作为目标进行建模;对于排序,他们以“播放时长加权的点击率”为目标进行建模。
基于以上内容,可以推导出召回的三种可能选型:
- 精准值预估:召回和排序逻辑完全一样。比如,如果排序做回归,那召回也做回归。
- 排序学习:召回学习的是排序打分的分布。
- 分类学习:召回学习的是排序的竞得,或者用户的交互,比如用户点击的视频、广告等。
这三种选型本质上对应着两种方案,第一种叫做“精准值预估”,对应上面第一个选型;第二种叫做“集合选择”,对应上面的第二、三个选型。我们应该选择哪种方案呢?
3、精准值预估 vs 集合选择

首先明确我们对召回选型的诉求:第一,我们希望能够满足一段时期的快速迭代;第二,我们希望它的起点足够高。我们首先对这两种方案做了一些优缺点分析。
“精准值预估”建模的目标是 ECPM。其优势是可解释性很强,同时还天然具有调价敏感性。但是其缺点也很明显:首先,召回既要与精排保持一致,又面临大量未曝光的候选集,任务比较困难;其次,不同的 OCPC 类型分布差异巨大,双塔模型学习难度很大;最后,召回阶段对于精准 ECPM 的诉求不够强烈,因此任务的难度可能会超过实际的需求。
“集合选择”建模的目标是精排头部的广告。由于直接面向后链路建模,其一致性会很强。同时还天然具有自动合并下游优化项的能力。当然,它也有缺点:首先,预估值的可解释性比较弱;其次,为了和 ECPM 打分性质保持一致,还需要单独做一些优化(如调价敏感性)。
我们通过在线效果和优缺点对比,选择“集合选择”技术作为最终选型。
4、LTR 原型模型

上图左侧就是 LTR 原型模型。结构比较简单,就是典型的双塔模型。只是它的样本稍微特殊一点,一条 pairwise 样本由多条样本组成。其中正样本指的是精排头部的广告,负样本是由大盘曝光的广告里随机采样得到的。Loss 采用 Ranking Loss,这里就不细讲了。
三、离线评估指标建设
通过原型模型和一些特征层面的优化,第一版上线就取得了 6% 的 ARPU 提升。在第一版之后进一步做迭代,就需要离线评估指标来指导优化。
1、离线评估建设-整体

离线评估建设主要分了三个阶段。在第一阶段,为了快速上线,我们并没有专门去定制一个评估集,只是简单地将样本根据时间划分成训练集和测试集。这种方式的存在的问题是 AUC 太高了,达到了 0.98,很难进一步指导迭代。另外,由于召回是样本的艺术,当样本改变之后,实验之间的 AUC 是不可比的。总的来说,这个评估集难以指导我们持续优化,因此需要一个更一致、更稳定的评估集,就引出了第二阶段的方案。
2、离线评估建设-全库评估

第二阶段,是离线 Faiss 全库检索。此时,正样本是精排 Top K 的广告,负样本是大盘曝光的广告,指标是 GAUC 和 Recall。Recall 指的是精排头部的 Top K 跟实际打分的 Top N 的交集数量,然后除以 K 求平均,这其实衡量的是对精排 Top K 的召回效果。其中有两个超参,第一个是 K,一般需要根据业务实际情况去选择;第二个是 N,指的是模型的容错程度,理论上 N 越大,这个任务会越简单。我们离线发现 N 的选择需要与模型能力匹配,过于困难或过于简单都不利于模型的迭代。
第二阶段方案还存在一些小问题。首先是 Faiss 在保证精度的前提下,全库检索的效率还是比较低的。另外,由于当前方案只用到了随机的负样本,难以做更精细的效果分析。接下来介绍第三阶段的评估方案,分段采样评估。
3、离线评估建设-分段采样评估

分段采样评估与之前方案最大的区别是负样本做了拆分,拆成了 Easy、Medium 和 Hard 三部分。Easy 负样本是从大盘曝光广告中采样得到的;Medium 负样本是从当次请求进入粗排但没进入精排的广告中采样得到的;Hard 负样本是从精排尾部的广告中采样得到的。Positive 还是由精排的 Top K 广告组成。数量上我们要确保 Easy 远大于 Medium 远大于 Hard 远大于 Positive。评估指标没有变,还是 GAUC 和 Recall。由于拆分了负样本,更利于我们做一些精细化的分析。
四、样本优化实践
确定了评估方式之后,接下来就要去做一些样本的优化。

1、调价敏感模型

上文提到召回模型一定要具有调价敏感性,这里展开介绍一下什么叫调价敏感性。对于整个广告系统来说,广告的出价是广告主投放广告的一个很重要的抓手,会影响广告的竞争力。我们期望广告系统全链路对广告主的出价都应该敏感。这个敏感是指:如果广告主的出价提高了,那么所有环节对这个广告的打分都应该提高。之前我们的处理方式是直接把这个广告出价的分桶特征作为底层特征输入模型。但我们发现随着广告主出价的提升,它的打分只有 5% 是提升的,这种敏感性是远远不够的,因此我们构建了调价敏感性模型。
模型结构如上图左侧所示。整体看,其实就是在双塔模型的右侧,加了一个 bid_part 结构。这个结构本质上是由广告的出价 CPA 乘以个性化的权重得到 bid_logits。通过这种优化,广告的调价敏感性从原来的 5% 提升到了 90%,比较符合预期,同时在线 ARPU 也有 1% 左右的提升。
2、精排负反馈-Hard Negative

在调价敏感性问题解决后,接下来我们要做效果的优化。其实 Easy Negative 区分度已经比较好了,想要去提升效果,最简单的方法就是引入后链路的数据,比如加入 Medium Negative 和 Hard Negative 作为反馈机制。
前期系统数据上报只有 Hard 数据,所以就先加入 Hard Negative。加入 Hard Negative 之前我们的预期是离线效果肯定会有提升,另外召回的多样性也会有提升。这是因为以前样本只关注精排的头部数据,模型很有可能已经记忆住了,不需要很强的个性化就能够解决这个问题。而引入了 Hard Negative 之后,它就需要对不同的请求做一些个性化的理解。从上图右侧的离线指标上也可以看到,Recall 和在线效果都有所提升。其中广告多样性有巨幅提升,约 8%,这是我们非常想要看到的结果。
3、人工规则挖掘 Negative

通过加入 Hard Negative 整体取得了很大提升之后,加入 Medium Negative 应该是顺理成章的事情。因为这块数据系统还没上报,所以我们想通过人工规则挖掘一些 Medium Negative。通过分析,我们发现召回和精排的整体打分是一致的,但是存在两种极端的 case。第一种是召回很多,但是几乎从不竞得的广告。这些广告存在的原因是因为它们没有曝光,甚至没有进入到精排,因此他们很难成为负样本,模型就感知不到。第二种情况是召回的很少,但竞得率奇高无比,当然这种情况实在太少了,所以我们忽略了这种情况。
对于第一种情况,如上图左边这个热力图,横轴是竞得次数的分桶,纵轴是召回次数的分桶,都是从小到大。左下角圈起来的部分是召回很多,但是竞得很少的广告,占比不是很多,但值得试一试。实践发现离线在线效果只有微弱提升,并且人工挖掘样本的效率实在太低了。因此,我们考虑能否通过模型自发现去解决这个问题。
4、模型自发现 Medium Negative

之所以会想到这一点,是因为虽然 Easy Negative 整体区分度很好,但是里面还是存在一些比较难区分的样本,只是这些样本的占比比较低而已。因此,如果我们让每个正样本都采样海量的 Easy Negative 样本,模型是不是就能够自发性地学习到那些比较困难的负样本呢?是不是就类似于 Medium Negative 呢?从这一个角度看,这类似于对比学习。
为了达到这个目的,我们有两个方法。第一个方法就是直接往样本里加 Easy Negative,但问题是计算跟存储的成本都会线性增长;第二个方法就是直接在模型里做 in batch 负采样,这种方案没有计算和存储的成本,因此我们优先考虑这个方案。
Loss 也有两种方法,第一种是用 LTR Loss。但在我们的实现中,随着每条 pairwise 样本中样本数的增加,LTR Loss 的计算量会呈指数级增长,所以我们想优先考虑第二种方法:Pointwise Loss。这个 Loss 的计算量随着样本数的增加呈线性增长。同时,由于 Loss 计算量整体在模型训练时占比较小,对整体耗时影响不大。所以我们最终选择了 Pointwise Loss。
5、大规模多分类解决选型简介

确定了 Loss 的方案,具体应该用哪种 Loss 呢?在继续介绍之前,需要先讲解一下大规模多分类的背景知识。
召回可以定义成一个超大规模多分类的问题。它的负样本就是成千上万的广告,正样本就是精排 Top K 的广告。普通的多分类,其实就是做一个 softmax,其分母就是所有负样本的打分的累加。但对于大规模多分类来说,这样做会使分母的计算量过大,几乎是不可行的。针对此问题,业界有两种方法。
第一种方法是将多分类转化成二分类,如上图左侧部分。转化成二分类之后,其实是转化成了 NCE 问题。本质上是把以前模型的预估值 F(x,y) 修正成 G(x,y),中间多了一个 Log Q 的采样概率修正系数。但这个值不好求,比较偷懒的方式,是直接让 G(x,y) 近似等于 F(x,y),然后直接放到二分类 BCE Loss 里,这叫做 NEG,也就是 Negative Sampling。NCE 的好处是随着负样本的增加,从理论上能够逼近大规模多分类的效果。而这个 NEG 理论上是有偏差的。
第二种方法就是继续保持多分类的方式。和第一种方法很相似,区别是要把 G(x,y) 放到 softmax 的 Loss 里,同时负样本直接采样。与 NCE 一样,修正的 Sample Softmax 理论上能够逼近大规模多分类的效果,而不修正 Sample Softmax 则是有偏的。但是,由于其操作简单,未修正的 Sample Softmax 类方法也会有一些公司使用并取得收益。
6、模型自发现 Medium Negative

在确定使用 Pointwise Loss 方法后,我们先尝试了比较简单的 Negative Sampling。样本是 in batch 负采样,Loss 是 BCE Loss,最后将原来的 BPR Loss 加上这个 BCE Loss 做融合。通过离线实验发现,如果只使用 In Batch Negative Sampling,效果是明显下降的。但是如果融合 LTR 和 In Batch Negative Sampling,效果则有微弱提升。

我们觉得很疑惑,加了几百个样本,效果居然只是微弱提升,这是不符合预期的。因此我们继续采用了刚刚提到的 Sample Softmax 方法,还是在 In Batch 内负采样,Loss 是不修正的 Sample Softmax Loss,如上图右侧公式所示,这有点像 infoNCE,因此我们也参考 infoNCE 引入了温度系数的概念。效果如上图左下侧所示,如果只使用 In Batch Sample Softmax,那么效果跟旧的 LTR 基本持平。如果融合 LTR 和 In Batch Sample Softmax,效果则有大幅度的提升。进一步调整温度系数,提升则更加明显。使用调整过温度系数的版本后,ARPU 提升了将近 2%,符合预期。不过这里要稍微注意下,随着 In Batch 数量的增加,Medium 和 Hard 的效果会有一个 Trade Off。

对于 Sample Softmax 效果优于 NEG,我们是疑惑的,于是进行了一些搜索,发现在不少论文和文章里,也都有提到这个现象,看起来并非个例。因此大家后续对大规模分类问题,或许可以优先考虑 Sample Softmax 类方法。
7、场景联合训练独立服务

最后讲下联合训练,这本质上是个多场景的问题。
在 OPPO 场景,由于媒体属性、广告主意愿等原因,广告在不同媒体上的分布是有较大差异的。对此,我们有以下几种方案选型。
第一种方法是完全独立。每个媒体单独建模、训练、预估。但是多个模型优化和运维的成本比较高,另外也没办法学习媒体之间的共性。
第二种方法是完全统一。主要是负样本共用,联合训练,在服务的时候保持只用一个模型,但是媒体之间的差异性很难被体现出来。
还有一种方法是联合训练和独立建模。不同媒体的样本是独立的,但训练时还是联合训练。模型结构如上图左侧所示,不同的媒体都有一个属于自己的 ad tower,所有媒体共享 user tower,此时不同媒体的 ad embedding 是独立的。这种方式既能保持媒体的共性,也能学到媒体的个性,并且也能够统一地优化和迭代。这种方式在我们的一些小场景上取得了收益,目前正计划在大场景中推进。

上面是关于样本优化的简单介绍。可以看出,召回确实是样本的艺术,更具体的说,是负样本的艺术,我们很多工作都是围绕着负样本优化来做的。但是样本只能决定模型的上限,具体怎样去逼近这个上限,还需要做一些模型的优化。
五、模型优化探索
下面来到模型优化探索部分。主要包括两部分,第一部分是关于双塔交互的优化,第二部分是关于泛化性的优化。
1、双塔交互优化-整体

受计算复杂度约束,召回普遍使用双塔结构。但是双塔结构的缺点就是 user 和 item 交互太晚,导致信息损失比较大。针对此问题,业界有一些探索工作,简单归类如下。
第一类是双塔的交互时刻不变,提升交互向量的信息量,比如 SENet 或者并联双塔。另外一个是将双塔交互的时刻提前,比如 DAT、IntTower 和 MVKE。还有一种是模型不变,通过特征去交互,比如物理含义相同的特征,让其共享 embedding,这也是一种隐式的交互。接下来我们会从这三类里面分别挑一个我们在实践中取得收益的模型来具体介绍。
2、提升交互向量有效信息量-SENet

第一个是 SENet。SENet 最开始主要应用在图像领域,它是通过对特征做一些个性化的加权(有点类似于特征 attention),突出重要特征压制不重要特征,来缓解前文中提到的“交互向量信息损失过大”的问题。其结果如上图左侧所示,SENet 在我们的场景中取得了明显的收益。
更重要的是,我们发现 SENet 的特征权重和特征重要性高度正相关。后续我们很多特征效果或者重要性的分析,都直接将 SENet 的特征权重作为参考。
3、双塔交互时刻提前-DAT

第二个是美团的 DAT,中文名为对偶增强的双塔模型。它主要的优化点是把向量交互的时刻提前。优化内容主要包含两部分,第一个部分叫做 AMM,第二部分叫 CAL。
这里主要讲下 AMM。美团的双塔由 query 塔和 item 塔组成。在 query 塔新增一个增强向量,即上图绿色部分,期望跟 item 塔最后一层 embedding 尽可能相似。同理,在 item 塔也有一个增强向量,跟 query 塔最后一个输出 embedding 尽可能相似。通过这种方式,让双塔交互增强。
实验发现,加入 AMM 特征后,效果有明显的提升。同时,如果在 AMM 特征输入时,优选下特征,其提升将更加明显。这个优选特征的规则是:用户侧用相对泛化的特征,而 item 侧用更稀疏更具体的特征。我们猜测优选特征效果更好的原因是用户侧的增强向量其实不需要那么强的个性化。
4、底层特征隐式交互

最后一个就是特征的隐式交互。在双塔模型里的 user 塔和 item 塔往往存在一些物理含义相同的特征,共享这些特征的 embedding 比直接训练效果更好。在我们的场景里面也有这种特征,叫做语义标签特征。这种特征的挖掘方式如上图左侧所示,我们会提取广告的语义信息,并且输入到大模型里,打上一些标签。而这些广告的标签会根据广告与用户的交互行为被赋予用户,所以用户和广告身上都会有这些标签。我们在模型训练的时候,通过上图左下侧所示的方式,使 user 塔和 item 塔的语义标签共享 embedding table。实验发现,这种方案的离线指标有微弱提升。
5、泛化性优化

主路召回作为召回的核心组成部分,承担着解决“大部分问题”的任务。但由于广告、媒体、用户、时间上的一些细分粒度往往有差异,导致学习这些差异的共性和个性比较困难。具体来说,从广告的视角有新老广告;从媒体的视角有不同类型的媒体;从用户的视角有高活用户和低活用户;从时间的视角有日常、周末、节假日、双十一。本质上来说,这里需要解决的问题是“混合分布下的差异化精准建模”的问题。
关于这个问题,业界也有一些探索。有的是直接加强个性化的特征,比如 Youtube 的 BiasNet,就是直接用一个 Bias Tower 穿透到最底层;还有多专家方案,比如腾讯的 MVKE 和 Google 的 CDN;还有动态权重,比如快手的 POSO 和 PPNet;还有一些融合类的方法。接下来介绍我们在实践中取得了一定收益的两个方法,分别是 CDN 和 PPNet。
6、冷启动优化-CDN

首先介绍一下使用 CDN 的背景。最开始为了加速迭代,主路模型除了在主路召回上用,也在新广告召回支路去做冷启。这就要求主模型兼顾新广告的排序效果。但是在主路模型的训练集里,新广告的占比肯定是比较少的,同时新广告的特征跟老广告有明显的差异,所以新广告的一些信息和特征会被淹没,新广告的效果得不到保证。因此我们参考了 2023 年 Google 提出的 CDN 模型,期望优化新广告效果。
CDN 结构如上图左侧红框所示,本质上是把 item 特征拆成了记忆类特征和泛化类特征,然后通过两个 expert 去学习,最后通过一个 Gate 门控对这两个 expert 做加权融合。记忆类特征主要包括 item 的稀疏类特征,泛化类特征主要包括统计类特征。线上实验证明,新广告冷启效率有 10% 的增长,非常可观。
7、多场景优化-PPNet

下面介绍多场景优化,除了上文提到的样本层面的优化,还有模型层面的优化。
首先讲下背景。OPPO 有很多场景类型,比如文字信息流、视频流等等。在将这些场景联合训练的时候,如何兼顾其共性和个性呢?
我们参考了快手的 PPNet,实现方式如上图左侧红框所示。本质是通过个性化门控网络,对原始的模型,做一个动态的个性化加权,得到一个千媒千面的模型。通过这种方式,我们发现效果是有提升的。
但是有一点需要注意,如果直接将媒体的 ID 输入到 Gate 门控,提升是比较微弱的。如果通过专家知识对这些门控的输入做一些聚合,那么 PPNet 就开始显现它的威力了。聚合的方法是把属性相似,或用户行为相似的媒体聚合。最后,如果对不同的媒体采用不同的 batch norm(即 DBN),模型的性能会进一步提升。
六、展望

前文中介绍了今年 OPPO 召回的主要相关工作,接下来分享一些我们的展望。
首先,虽然当前 ECPM 支路比较简单,但是 ECPM 支路还是能够对 LTR 主路起到补充作用,因此我们后续还会在 ECPM 支路上做一些工作。
其次,现在广告推荐整体已经走向了广告商品化、创意智能化。在这个趋势下,召回和排序的分工也会发生一些变化。当然,召回辅助下游找到价值最高的广告,这一个定位是不变的。
以上就是本次分享的全部内容,谢谢。
七、问答环节
Q1:如果召回的算法太复杂的话,你们是怎么考虑的?
A1:我们不能要求召回算法复不复杂,因为这取决于你想解决的是什么类型的问题。举个例子,现在 OPPO 召回的定位是“单主路加多辅路”,主路要解决大部分的问题,那主路算法可能就复杂些。有些传统公司的召回是“多主路召回”,比如热度召回、统计召回、兴趣召回等等叠加,那每一个路召回可能都比较简单,算法也不需要太复杂。
Q2:让召回去学精排,会不会导致召回更加局限性呢?
A2:如果把局限理解为 SSB 问题,其实召回一直存在这个问题。之前的 gap 是从召回的全量候选到曝光候选。现在如果让召回去学精排,那现在的 gap 就是从全量候选到精排的 Top 部分广告。这种方式的 SSB 会缓解一些,SSB 问题是要长期去探索解决的。
Q3:离线评估指标 Recall 公式里的 N 和 K 是如何确定的?
A3:不同的场景中,N 和 K 的取值是不一样的。
K 得根据具体的业务场景来定。比如在信息流,一般我们就看几个广告,那 K 可能取 1-3;在下载商店,一次性会展示很多 APP,那 K 就会很大,甚至取上百个。
N 的取值则与模型效果和 K 有关,N 越大任务越简单。如果任务太简单,Recall 非常高,比如 0.99,那么任何优化都很难离线体现出效果;任务太难,Recall 非常小,那很多优化也可能无法体现出来,就像让小学生去参加高考,大家都 0 分。具体的 N 和 K 的组合,需要自行根据场景和模型调节。
Q4:在召回阶段样本设计时,简单和困难样本比例是怎么调控的?
A4:召回是在全量候选集里面找出用户可能感兴趣的广告,这就决定了在样本设计时,简单样本数量要远远大于困难样本数量。
简单和困难样本的比例,是通过实践去确定的。比如 Facebook 的论文中提到,简单和困难样本的比例值是 100 比 1。我们的场景没有那么悬殊,但也差不多。
Q5:召回离线评估为什么用 AUC?你们的召回离线评估和线上效果是一致的吗?
A5:在召回阶段,AUC 类似一个护栏指标,是为了确保召回里的排序整体没有大的分布问题。在此基础上,我们尽量提升 Recall。另外,我们大部分的离线指标和在线指标整体的趋势是一致的。当然,我们无法保证离线和在线提升的百分比是完全相同的。