一、问题描述
假设我们有这样一张表,且包含一条记录:
这个表实际上包含3个索引:
- 主键索引(且值包含一个block)
- 索引c1(且值包含一个block)
- 索引c2(且值包含一个block)
那么我们考虑如下的语句:
- A: update mytest set c1=11,c2=12,c3=13 where id=1(c1\c2\c3字段都不更改)
- B: update mytest set c1=11,c2=12,c3=14 where id=1(c1\c2字段不更改)
- C: update mytest set c1=12,c2=12,c3=14 where id=1(c2字段不更改)
那么问题如下:
- A 场景下各个索引的值是否更改,也就是实际的各个索引block是否更改。
- B 场景下索引c1和索引c2的数据是否更改,也就是实际的索引c1和索引c2的block是否更改。
- C 场景下索引c2的数据是否更改,也就是实际索引c2的block是否更改。
二、大概的半段方式和流程
对于update语句来讲,函数mysql_update对修改流程大概如下:
扫描数据,获取数据(rr_sequential),存储mysql格式的数据到record[0]中,其表示大概如下:
每个field都包含一个指向实际数据的指针。
保存获取的mysql格式的数据到record[1]中,然后使用语法解析后的信息填充获取的record[0]中的数据(fill_record_n_invoke_before_triggers->fill_record),这里就是使用c1=,c2=,c3=*填充数据,需要填充的数据和字段实际上保存在两个List中分别为Item_feild和Item_int类型的链表我们这里就叫做column_list和values_list,它们在bsion规则文件中使用如下表示:
下面使用语句update mytest set c1=11,c2=12,c3=13 where id=1来debug一下这个两个list,我们断点放到fill_record_n_invoke_before_triggers就可以了,
这样修改后record[0]中需要修改的字段的值就变为了本次update语句中的值。
过滤点1,比对record[0]和record[1] 中数据是否有差异,如果完全相同则不触发update,这里也就对应我们的场景A,因为前后记录的值一模一样,因此是不会做任何数据更改的,这里直接跳过了*。
到这里肯定是要修改数据的,因此对比record[0]和record[1]的记录,将需要修改的字段的值和字段号放入到数组m_prebuilt->upd_node->update中(calc_row_difference),其中主要是需要修改的new值和需要修改的field_no比对方式为:
- 长度是否更改了(len)
- 实际值更改了(memcmp比对结果)
确认修改的字段是否包含了二级索引。因为前面已经统计出来了需要更改的字段(row_upd的开头),那么这里对比的方式如下:
- 如果为delete语句显然肯定包含所有的二级索引
- 如果为update语句,根据前面数组中字段的号和字典中字段是否排序进行比对,因为二级索引的字段一定是排序的如果两个条件都不满足
如果两个条件都不满足,这说明没有任何二级索引在本次修改中需要修改,设置本次update的标记为UPD_NODE_NO_ORD_CHANGE,UPD_NODE_NO_ORD_CHANGE则代表不需要修改任何二级索引字段。注意这里还会转换为innodb的行格式(row_mysql_store_col_in_innobase_format)。
过滤点2,先修改主键,如果为UPD_NODE_NO_ORD_CHANGE update这不做二级索引更改,也就是不调用row_upd_sec_step函数,这是显然的,因为没有二级索引的字段需要更改(函数row_upd_clust_step中实现),这里对应了场景B,虽然 c3字段修改了数据,但是c1\c2字段前后的值一样,所以实际索引c1和索引c2不会更改,只修改主键索引。
如果需要更改二级索引,依次扫描字典中的每个二级索引循环开启。
过滤点3首选需要确认修改的二级索引字段是否在本索引中,如果修改的字段根本就没有在这个二级索引中,显然不需要修改本次循环的索引了。而这个判断在函数row_upd_changes_ord_field_binary中,方式为循环字典中本二级索引的每个字段判定,
- 如果本字段不在m_prebuilt->upd_node->update数组中,直接进行下一个字段,说明本字段不需要修改
- 如果本字段在m_prebuilt->upd_node->update数组中,这进行调用函数dfield_datas_are_binary_equal进行比较,也就是比较实际的值是否更改
这里实际上对应了我们的场景3,因为c2字段的值没有更改,因此索引c2不会做实际的更改,但是主键索引和索引c1需要更改值。
三、结论
从代码中我们可以看到,实际上在MySQL或者innodb中,实际上只会对有数据修改的索引进行实际的更改。那么前面提到的几个场景如下:
- A: update mytest set c1=11,c2=12,c3=13 where id=1(c1\c2\c3字段都不更改) 不做任何数据修改
- B: update mytest set c1=11,c2=12,c3=14 where id=1(c1\c2字段不更改) 只更改主键索引
- C: update mytest set c1=12,c2=12,c3=14 where id=1(c2字段不更改) 只更改主键索引和索引c1
四、验证
对于验证我们验证场景3,这里主要通过block的last_modify_lsn进行验证,因为一个block只要修改了数据,脏数据刷盘后其last_modify_lsn一定会修改,步骤如下:
初始化数据 这里mytest表为测试表,而mytest2表主要的作用是修改数据推进lsn:
(1) 记录当前lsn
由于是测试库show engine的lsn是静止的如下 Log sequence number 4806780238 Log flushed up to 4806780238 Pages flushed up to 4806780238 且 Modified db pages 0 没有脏页,都说明脏数据全部刷盘了。
(2) 查询各个索引对应block
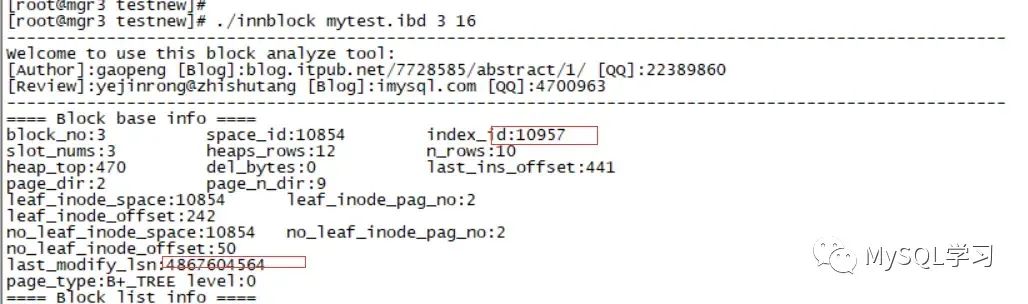
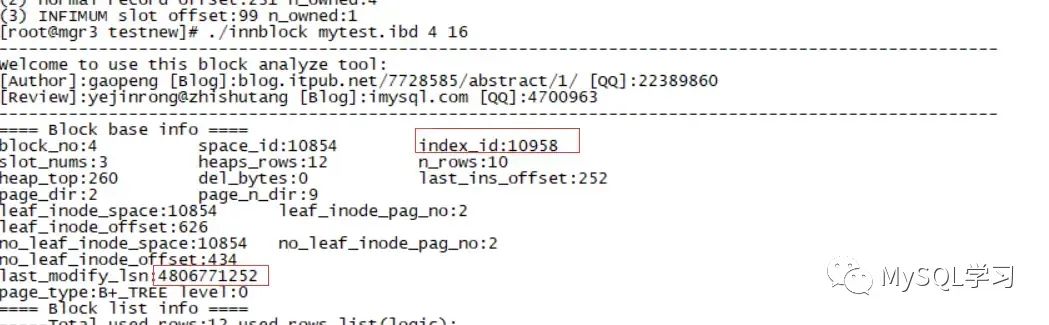
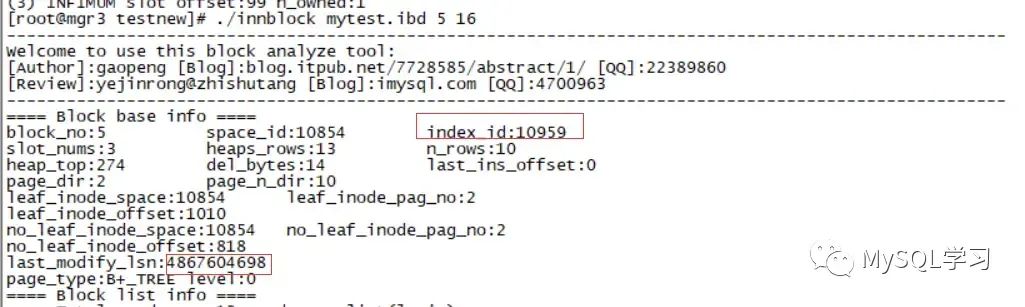
这里找到INDEX_ID 10957 主键,10958 c1 索引,10959 c2 索引。
这里我们发现 10957的block为3 ,10958的block为4,10959的block为5,下面分别获取他们的信息。
使用blockinfo工具查看当前mytest各个block的lsn:
- 10957 PRIMARY block 3:
- 10958 c1 block 4
- 10959 c2 block 5
这里我们就将3个page的last_modify_lsn获取到了大概在4806771200附近。
(3) mytest2表做一些数据修改推进lsn
(4) 再次查看系统的lsn
这个时候lsn变化了,但是脏数据已经刷脏。
(5) 对mytest表进行修改
修改这行记录 id c1 c2 c3 2 14 15 16
update t1 set c1=14,c2=115,c3=116 where id=2;
我们保持c1不变化,预期如下: index:10957 PRIMARY block 3:last_modify_lsn 在4867604378附近 index:10958 c1 block 4:last_modify_lsn 保持4806771252不变,因为前面的理论表名不会做修改 index:10959 c2 block 5:last_modify_lsn 在4867604378附近.
(6) 最终结果符合预期截图如下