本文经自动驾驶之心公众号授权转载,转载请联系出处。
MonoLSS: Learnable Sample Selection For Monocular 3D Detection
论文链接:https://arxiv.org/pdf/2312.14474.pdf
在自动驾驶领域,单目3D检测是一个关键任务,它在单个RGB图像中估计物体的3D属性(深度、尺寸和方向)。先前的工作以一种启发式的方式使用特征来学习3D属性,而没有考虑不适当的特征可能产生不良影响。在本文中,引入了样本选择,只有适合的样本才应该用于回归3D属性。为了自适应地选择样本,提出了一个可学习的样本选择(LSS)模块,该模块基于Gumbel-Softmax和相对距离样本划分。LSS模块在warmup策略下工作,提高了训练稳定性。此外,由于专用于3D属性样本选择的LSS模块依赖于目标级特征,进一步开发了一种名为MixUp3D的数据增强方法,用于丰富符合成像原理的3D属性样本而不引入歧义。作为两种正交的方法,LSS模块和MixUp3D可以独立或结合使用。充分的实验证明它们的联合使用可以产生协同效应,产生超越各自应用之和的改进。借助LSS模块和MixUp3D,无需额外数据,方法MonoLSS在KITTI 3D目标检测基准的所有三个类别(汽车、骑行者和行人)中均排名第一,并在Waymo数据集和KITTI-nuScenes跨数据集评估中取得了有竞争力的结果。
MonoLSS主要贡献:
论文强调,并非所有特征对学习3D属性都同样有效,并首先将其重新表述为样本选择问题。相应地,开发了一种新的可学习样本选择(LSS)模块,该模块可以自适应地选择样本。
为了丰富3D属性样本,设计了MixUp3D数据增强,它模拟了空间重叠,并显著提高了3D检测性能。
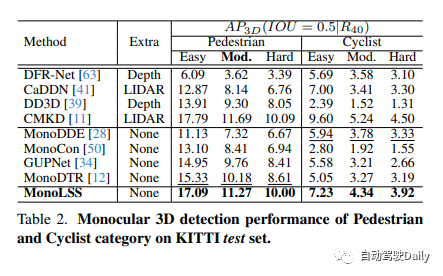
在不引入任何额外信息的情况下,MonoLSS在KITTI基准的所有三个类别中排名第一,在汽车类别的中等和中等水平上,超过了当前的最佳方法11.73%和12.19%。它还实现了Waymo数据集和KITTI nuScenes跨数据集评估的SOTA结果。
MonoLSS主要思路
MonoLSS框架如下图所示。首先,使用与ROI Align相结合的2D检测器来生成目标特征。然后,六个Head分别预测3D特性(深度、尺寸、方向和3D中心投影偏移)、深度不确定性和对数概率。最后,可学习样本选择(LSS)模块自适应地选择样本并进行损失计算。
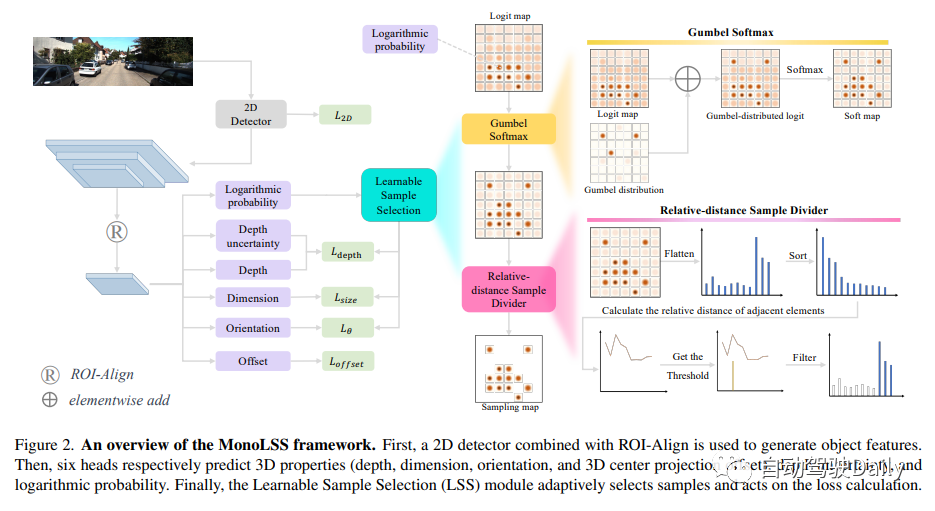
Learnable Sample Selection
假设U~Uniform(0,1),则可以使用逆变换采样通过计算G=−log(−log(U))来生成Gumbel分布G。通过用Gumbel分布独立地扰动对数概率,并使用argmax函数找到最大元素,Gumbel Max技巧实现了无需随机选择的概率采样。基于这项工作,Gumbel Softmax使用Softmax函数作为argmax的连续可微近似,并在重新参数化的帮助下实现了整体可微性。
GumbelTop-k通过在没有替换的情况下绘制大小为k的有序采样,将采样点的数量从Top-1扩展到Top-k,其中k是一个超参数。然而,相同的k并不适用于所有目标,例如,被遮挡的目标应该比正常目标具有更少的正样本。为此,我们设计了一个基于超参数相对距离的模块来自适应地划分样本。总之,作者提出了一个可学习样本选择(LSS)模块来解决三维属性学习中的样本选择问题,该模块由Gumbel Softmax和相对距离样本除法器组成。LSS模块的示意图如图2的右侧所示。
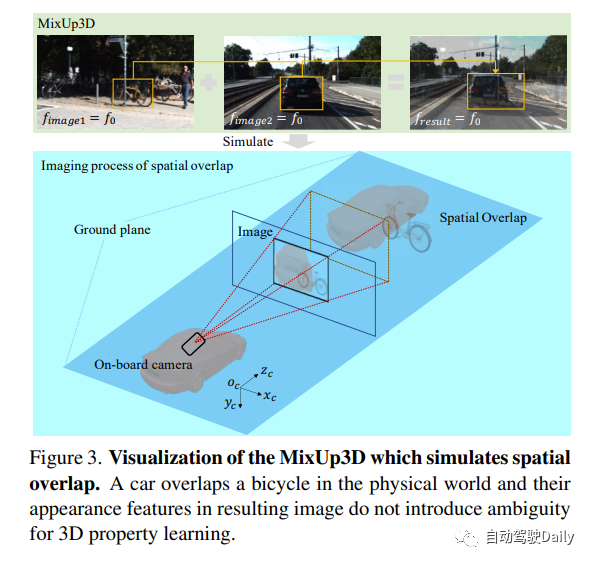
Mixup3D数据增强
由于严格的成像约束,数据增强方法在单目3D检测中受到限制。除了光度失真和水平翻转之外,大多数数据增强方法由于破坏了成像原理而引入了模糊特征。此外,由于LSS模块专注于目标级特性,因此不修改目标本身特性的方法对LSS模块来说并不足够有效。
由于MixUp的优势,可以增强目标的像素级特征。作者提出了MixUp3D,它为2D MixUp添加了物理约束,使新生成的图像基本上是空间重叠的合理成像。具体而言,MixUp3D仅违反物理世界中对象的碰撞约束,同时确保生成的图像符合成像原理,从而避免任何歧义!
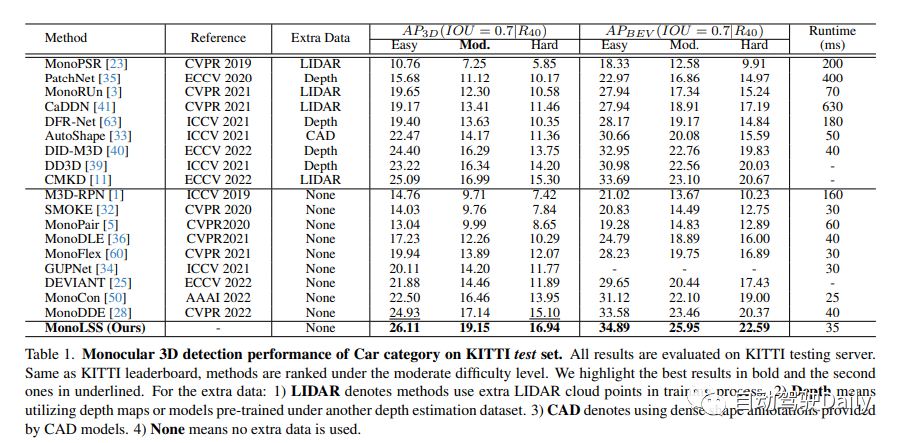
实验结果
KITTI测试集上汽车类的单目3D检测性能。与KITTI排行榜相同,方法排名在中等难度以下。我们以粗体突出显示最佳结果,以下划线突出显示第二个结果。对于额外的数据:1)LIDAR表示在训练过程中使用额外的LIDAR云点的方法。2) 深度是指利用在另一深度估计数据集下预先训练的深度图或模型。3) CAD表示使用由CAD模型提供的密集形状注释。4) 无表示不使用额外数据。
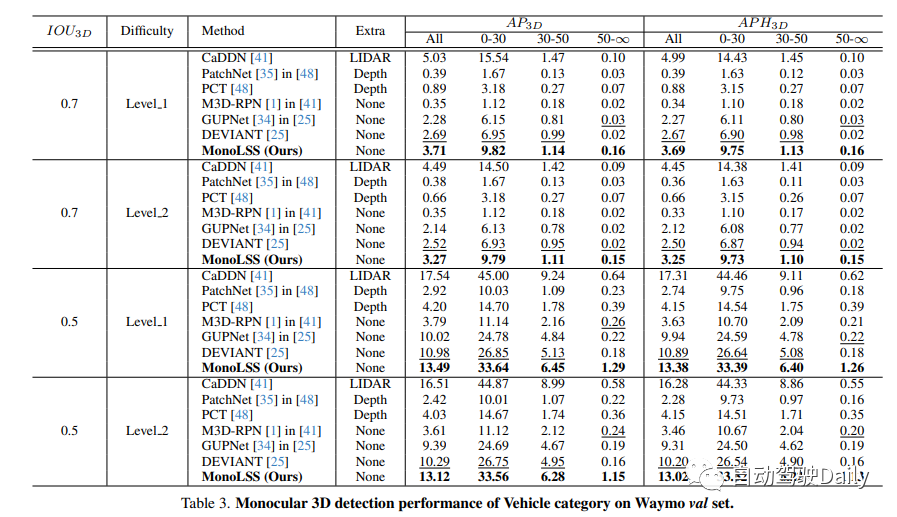
Wamyo上数据集测试结果:
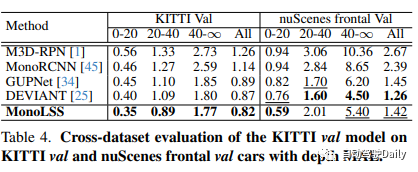
KITTI-val模型在深度为MAE的KITTI-val和nuScenes前脸val汽车上的跨数据集评估:

原文链接:https://mp.weixin.qq.com/s/X5_2ZZjABnvEi2Ki62oiwg