目前物理复制到了ro 开始刷120s apply_lsn 不推进的信息以后, 即使压力停下来也无法恢复, 为什么?
如下图所示:
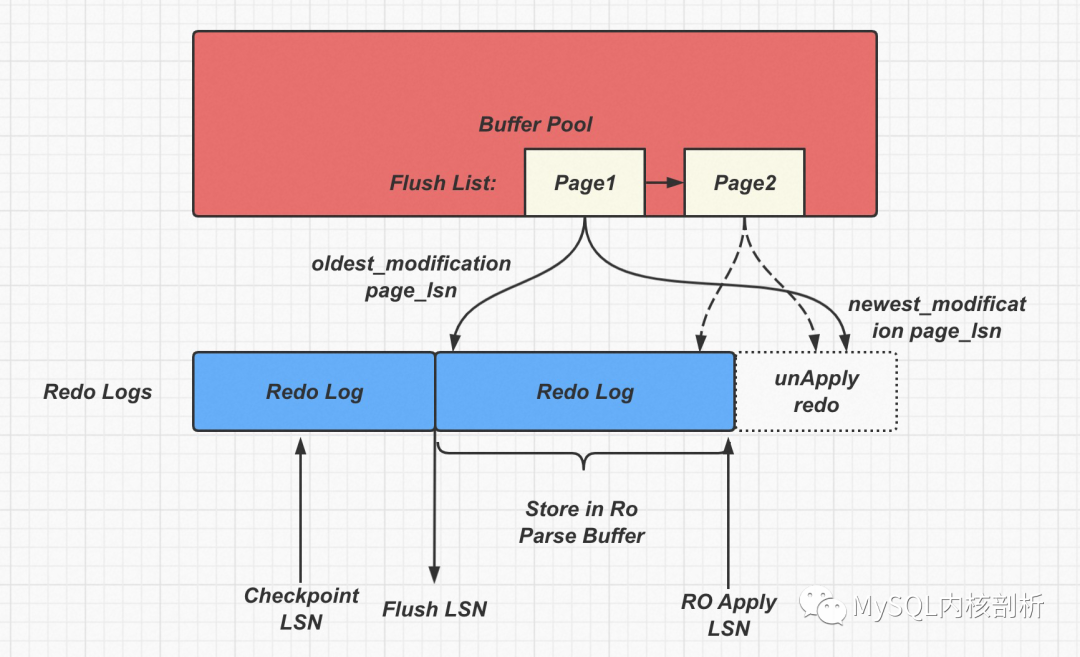
这里最极端的场景是如果rw 上面最老的page1, 也就是在flush list 上根据 oldest_modification_lsn 排在最老的位置page_lsn 已经大于ro 上面的apply_lsn 了, 那么刷脏是无法进行的, 因为物理复制需要保证page 已经被解析到ro parse buffer才可以进行刷脏. 另外想Page2 这样的Page 虽然newest_modification 和 oldest_modification 没有差很多也无法进行刷脏了. 因为Parse buffer 已经满了.
但是这个时候ro 节点的apply_lsn 已经不推进了, 因为上面的parse buffer 已经满了, parse buffer 推进需要等rw 节点把老的page 刷下去, 老的parse buffer chunk 才可以释放. 但是由于上面rw 节点已经最老的page 都无法刷脏, 那么parse buffer chunk 肯定就没机会释放了.
那么此时就形成了死循环了. 即使写入压力停下来, ro 也是无法恢复的.
所以只要rw 上面最老page 超过了 parse buffer 的大小, 也就是最老page newest_modification_page lsn > ro apply_lsn 之时, 那么死锁就已经形成, 后续都无法避免了
这里copy_page 为何没有生效?
目前copy_page 的机制是刷脏的时候进行的, 在下图中copy page copy 出来的page newest_modification 也是大于ro apply_lsn 的, 所以也是无法刷脏的, 所以这个时候其实这个copy_page 机制是无效的机制.
正确的做法是: 在发现Page newest_modification 有可能超过一定的大小, 那么就应该让该page 进行copy page强行刷脏, 否则到后面在进行刷脏就来不及了.
开启了多版本LogIndex 版本为什么可以规避这个问题?
在因为parse buffer 满导致的刷脏约束中, 如上图所示, Page1, Page2 无法进行刷脏, 但是其他的Page 如果newest_modification < ro apply_lsn 是可以刷脏的, 因此rw 节点buffer pool 里面脏页其实不多.
开启了LogIndex 以后, ro 就可以随意丢弃自己的parse buffer 了, 当然也就不会crash.
但是依然有一个问题是如果Page1 一直修改, 这个Page1 的newest_modification lsn 一直在更新, 那么即使开启LogIndex 也无法将该Page 刷下去, 带来的问题是rw checkpoint 是无法推进, 但是由于有了LogIndex, 其他page 可以随意刷脏, 所以不会出现rw 脏页数不够的问题. 那Page1 刷脏如何解决呢?
通过copy page 解决.
如果rw 开启了copy page 以后, 虽然上图中的Page1 刚刚被copy 出来的时候无法flush, 但是因为开启LogIndex, ro apply_lsn 可以随意推进, 随着ro apply_lsn 的推进, 过一段时间一定可以刷这个copy page, 也就避免了这个问题了.
所以目前版本答案是 LogIndex + copy page 解决了几乎所有问题
另外验证了刷脏约束两种场景
- 大量写入场景
- 有热点页场景
其实大量写入场景即使导致了刷脏约束, 后面还是可以恢复的, 只有热点页场景才无法恢复. 很多时候热点页不一定是用户修改的page, 而是Btree 上面的一些其他page, 比如root page 等等, 我们很难发现的.
另外验证了如果page 以及 redo log 写入延迟都升高, 是不会特别出现刷脏约束问题, 只有出现热点页的场景才会有问题.
上图可以看到
ro parse buffer = ro appply_lsn - rw flush_lsn
apply_lsn 是ro 节点读取redo 并应用推进的速度
flush_lsn 是rw 节点page 刷脏推进的速度
由于IO 延迟同时影响了 redo 和 page, 从公式可以看到, 那么ro parse buffer 不会快速增长的.
从公式里面可以看到, 如果redo 推进速度加快, page 刷脏速度减慢, 那么是最容易出现刷脏约束的. 也就是redo IO 速度不变, Page IO 速度变慢, 就容易出现把RO parse buffer 打满的情况, 但是一样需要出现热点页才能出现parse buffer 被打满的死锁.
如果没有热点页, 这个时候由于parse buffer 还是再推进, 所以不会自动crash, 反而会出现rw 由于被限制了刷脏, buffer pool 里面大量的脏页, 最后找不到空闲Page 的情况. rw crash 的情况.
多版本或者Aurora 如何解决这个问题?
刚才上面的分析有两个链条互相依赖
约束1: rw 的刷脏依赖ro 节点apply_lsn 的推进
约束2: ro 节点释放old parse buffer 依赖rw 节点刷脏
多版本/Aurora 都把约束2 给去掉了, ro 节点可以随意释放old parse buffer. 那么就不会有parse buffer 满的问题, 那么如果ro 节点访问到rw 还未刷下去page, 但是ro 节点已经把Parse buffer 释放了, 那么会通过磁盘上的 logIndex + 磁盘上page 生成想要的版本.
但是这里依然还要去解决约束1 的问题, rw 的刷脏会被ro 给限制. rw 刷脏时候判断 page newest_modification_lsn > ro apply_lsn, 那么在Aurora 里面这个Page 也是无法进行Apply 的, 但是Aurora 和我们区别在于Aurora 可以把这个Page 丢出buffer pool, 但是我们是无法把这样的page 丢出Buffer Pool, 依然会造成Buffer Pool 里面大量的脏页, 最后找不到空闲Page 的情况. 在多版本引擎里面支持把Page newest_modification_lsn > ro apply_lsn 这样的Page 在Buffer Pool 中释放也很重要.