本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人总结
鸟瞰图(Bird eye's view, BEV)检测是一种通过融合多个环视摄像头来进行检测的方法。目前算法大部分算法都是在相同数据集训练并且评测,这导致了这些算法过拟合于不变的相机内参(相机类型)和外参(相机摆放方式)。本文提出了一种基于隐式渲染的BEV检测框架,能够解决未知域的物体检测问题。该框架通隐式渲染来建立物体3D位置和单个视图的透视位置关系,这可以用来纠正透视偏差。此方法在领域泛化(DG)和无监督领域适应(UDA)方面取得了显著的性能提升。该方法首次尝试了只用虚拟数据集上进行训练在真实场景下进行评测BEV检测,可以打破虚实之间的壁垒完成闭环测试。
- 论文链接:https://arxiv.org/pdf/2310.11346.pdf
- 代码链接:https://github.com/EnVision-Research/Generalizable-BEV

BEV检测域泛化问题背景
多相机检测是指利用多台摄像机对三维空间中的物体进行检测和定位的任务。通过结合来自不同视点的信息,多摄像头3D目标检测可以提供更准确和鲁棒的目标检测结果,特别是在某些视点的目标可能被遮挡或部分可见的情况下。近年来,鸟瞰图检测(Bird eye's view, BEV)方法在多相机检测任务中得到了极大的关注。尽管这些方法在多相机信息融合方面具有优势,但当测试环境与训练环境存在显著差异时,这些方法的性能可能会严重下降。
目前BEV检测算法大部分算法都是在相同数据集训练并且评测,这导致了这些算法过拟合于不变的相机内外参数和城市道路条件。然而在BEV检测实际应用中,常常要求算法要适配不同新车型和新摄像头,这导致了这些算法的失效。所以,研究BEV检测的泛化性研究非常重要。此外,无人驾驶的闭环仿真也是非常重要的,但是闭环仿真目前只能在虚拟引擎(例如Carla)中进行评测。所以,打破虚拟引擎和真实场景中的域差异也非常必要。
域泛化(domain generalization, DG)和无监督域自适应(unsupervised domain adaptation, UDA)是缓解分布偏移的两个有前途的方向。DG方法经常解耦和消除特定于领域的特征,从而提高不可见领域的泛化性能。对于UDA,最近的方法通过生成伪标签或潜在特征分布对齐来缓解域偏移。然而,如果不使用来自不同视点、相机参数和环境的数据,纯视觉感知学习与视角和环境无关的特征是非常具有挑战性的。
观察表明单视角(相机平面)的2D检测往往比多视角的3D目标检测具有更强的泛化能力,如图所示。一些研究已经探索了将2D检测整合到BEV检测中,例如将2D信息融合到3D检测器中或建立2D-3D一致性。二维信息融合是一种基于学习的方法,而不是一种机制建模方法,并且仍然受到域迁移的严重影响。现有的2D-3D一致性方法是将3D结果投影到二维平面上并建立一致性。这种约束可能损害目标域中的语义信息,而不是修改目标域的几何信息。此外,这种2D-3D一致性方法使得所有检测头的统一方法具有挑战性。

本论文的的贡献总结
- 本论文提出了一种基于视角去偏的广义BEV检测框架,该框架不仅可以帮助模型学习源域中的视角和上下文不变特征,还可以利用二维检测器进一步纠正目标域中的虚假几何特征。
- 本文首次尝试在BEV检测上研究无监督域自适应,并建立了一个基准。在UDA和DG协议上都取得了最先进的结果。
- 本文首次探索了在没有真实场景注释的虚拟引擎上进行训练,以实现真实世界的BEV检测任务。
BEV检测域泛化问题定义
问题定义
研究主要围绕增强BEV检测的泛化。为了实现这一目标,本文探索了两个广泛具有实际应用价值的协议,即域泛化(domain generalization, DG)和无监督域自适应(unsupervised domain adaptation, UDA):
BEV检测的域泛化(DG):在已有的数据集(源域)训练一个BEV检测算法,提升在具有在未知数据集(目标域)的检测性能。例如,在特定车辆或者场景下训练一个BEV检测模型,能够直接泛化到各种不同的车辆和场景。
BEV检测的无监督域自适应(UDA):在已有的数据集(源域)训练一个BEV检测算法,并且利用目标域的无标签数据来提高检测性能。例如,在一个新的车辆或者城市,只需要采集一些无监督数据就可以提高模型在新车和新环境的性能。值得一提的是DG和UDA的唯一区别是是否可以利用目标域的未标记数据。
视角偏差定义
为了检测物体的未知L=[x,y,z],大部分BEV检测会有关键的两部(1)获取不同视角的图像特征;(2)融合这些图像特征到BEV空间并且得到最后的预测结果:
上面公式描述,域偏差可能来源于特征提取阶段或者BEV融合阶段。然后本文进行了在附录进行了推到,得到了最后3D预测结果投影到2D结果的视角偏差为:
其中k_u, b_u, k_v和b_v与BEV编码器的域偏置有关,d(u,v)为模型的最终预测深度信息。c_u和c_v表示相机光学中心在uv图像平面上的坐标。上面等式提供了几个重要的推论:(1)最终位置偏移的存在会导致视角偏差,这表明优化视角偏差有助于缓解域偏移。(2)即使是相机光心射线上的点在单个视角成像平面上的位置也会发生移位。
直观地说,域偏移改变了BEV特征的位置,这是由于训练数据视点和相机参数有限而产生的过拟合。为了缓解这个问题,从BEV特征中重新渲染新的视图图像是至关重要的,从而使网络能够学习与视角和环境无关的特征。鉴于此,本文旨在解决不同渲染视点相关的视角偏差,以提高模型的泛化能力。
详解PD-BEV算法
PD-BEV一共分为三个部分:语义渲染,源域去偏见和目标域去偏见如图1所示。语义渲染是阐述如如何通过BEV特征建立2D和3D的透视关系。源域去偏见是描述在源域如何通过语义渲染来提高模型泛化能力。目标域去偏见是描述在目标域利用无标住的数据通过语义渲染来提高模型泛化能力。

语义渲染
因为很多算法都会讲BEV volume的高度拍扁成为二维的特征,这部分讲先利用一个BEV Decoder将BEV特征提升成一个Volume:
上面的公式其实就是对BEV平面进行了提升,增加了一个高度维度。然后通过相机的内外参数就可以在这个Volume采样成为一个2D的特征图,然后这个2D特征图和相机内外参数送到一个RenderNet里面来预测对应视角的heatmap和物体的属性。通过这样的类似于Nerf的操作就可以建立起2D和3D的桥梁。
源域去偏见
这个部分在源域如何提高模型泛化性能的。为了减少视角偏差,源域的3D框可以用来监控新渲染视图的热图和属性。此外,还利用归一化深度信息来帮助图像编码器更好地学习几何信息。
视角语义监督:基于语义渲染,热图和属性从不同的角度渲染(RenderNet的输出)。同时,随机采样一个相机内外参数,将物体的方框从3D坐标利用这些内外参数投射到二维相机平面内。然后对投影后的2Dbox与渲染的结果使用Focal loss和L1 loss进行约束:
通过这个操作可以降低对相机内外参数的过拟合以及对新视角的鲁棒性。值得一提的是,这个论文将监督从RGB图像换成了物体中心的heatmaps,可以避免Nerf在无人驾驶领域缺少新视角RGB监督的缺点。
几何监督:提供明确的深度信息可以有效地提高多相机3D目标检测的性能。然而,网络预测的深度倾向于过拟合内在参数。因此,这个论文借鉴了一种虚拟深度的方式:
其中BCE()表示二进制交叉熵损失,D_{pre}表示DepthNet的预测深度。f_u和f_v分别为像平面的u和v焦距,U为常数。值得注意的是,这里的深度是使用3D框而不是点云提供的前景深度信息。通过这样做,DepthNet更有可能专注于前景物体的深度。最后,当使用实际深度信息将语义特征提升到BEV平面时,将虚拟深度转换回实际深度。
目标域去偏见
在目标域就没有标注了,所以就不能用3D box监督来提高模型的泛化能力了。所以这个论文阐述说,2D检测的结果比起3D结果更加鲁棒。所以这个论文利用在源域中的2D预训练的检测器作为渲染后的视角的的监督,并且还利用了伪标签的机制:
这个操作可以有效地利用精确的二维检测来校正BEV空间中的前景目标位置,这是一种目标域的无监督正则化。为了进一步增强二维预测的校正能力,采用伪方法增强预测热图的置信度。这个论文在3.2和补充材料里给出了数学证明说明了3D结果在2D投影误差的原因。以及阐述了为什么通过这种方式可以去偏见,详细的可以参考原论文。
总体的监督
虽然本文已经添加了一些网络来帮助训练,但这些网络在推理中是不需要的。换句话说,本文的方法适用于大多数BEV检测方法学习透视不变特征。为了测试我们框架的有效性,BEVDepth被实例化为测评对象。在源域上使用BEVDepth的原始损失作为主要的三维检测监督。总之,算法的最终损失是:
跨域实验结果
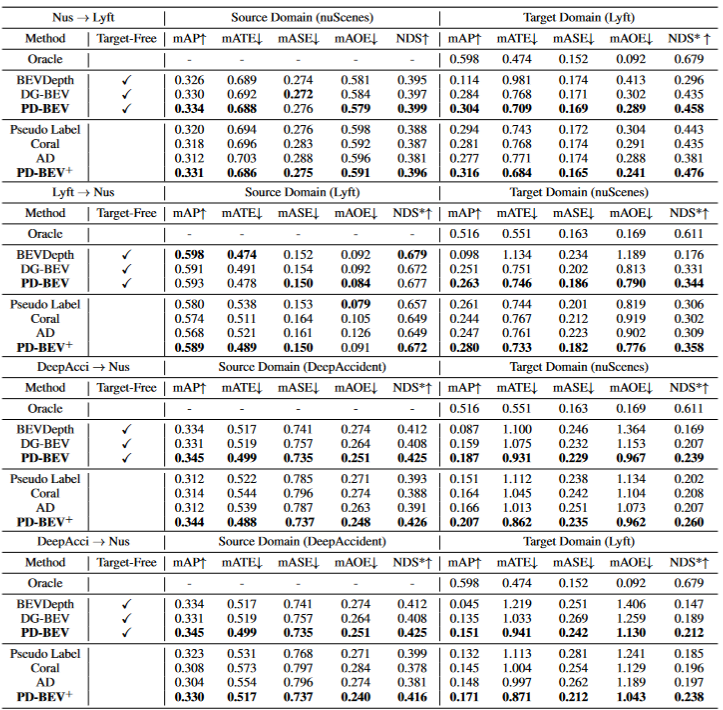
表格1展示了在领域泛化(DG)和无监督领域适应(UDA)协议下不同方法的效果比较。其中,Target-Free表示DG协议,Pseudo Label、Coral和AD是在UDA协议上的一些常见方法。图表中,方法在目标域取得了显著的改进。它表明语义渲染作为一个桥梁可以帮助学习针对域移位的透视不变特征。此外,方法不会牺牲源域的性能,甚至在大多数情况下有一些改进。值得一提的是,DeepAccident来源于一个Carla虚拟引擎,算法也通过在DeepAccident上的训练获得了令人满意的泛化能力。此外,测试了其他BEV检测方法,在没有特殊设计的情况下,它们的泛化性能非常差。为了进一步验证利用目标域无监督数据集的能力,还建立了一个UDA基准,并在DG-BEV上应用了UDA方法(包括Pseudo Label、Coral 和AD。算法实现了显著的性能提升。隐式渲染充分利用具有更好泛化性能的二维探测器来校正三维探测器的虚假几何信息。此外,发现大多数算法倾向于降低源域的性能,本文方法相对温和。值得一提的是,发现AD和Coral在从虚拟数据集转移到真实数据集时表现出显着的改进,但在真实测试中测试时表现出性能下降。这是因为这两种算法是为解决风格变化而设计的,但在样式变化很小的场景中,它们可能会破坏语义信息。对于Pseudo Label算法,它可以通过在一些相对较好的目标域中增加置信度来提高模型的泛化性能,但盲目地增加目标域中的置信度实际上会使模型变得更差。实验结果证明了算法在DG和UDA方面取得了显著的性能提升。
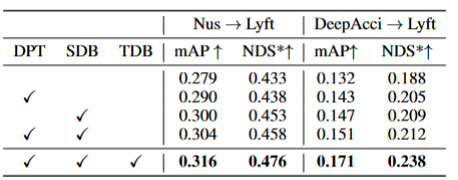
表格2展示了算法在三个关键组件上的消融实验结果:2D检测器预训练(DPT)、源域去偏(SDB)和目标域去偏(TDB)。实验结果表明,每个组件都取得了改进,其中SDB和TDB表现出相对显著的效果。
表格3展示了算法算法可以迁移到BEVFormer和FB-OCC算法上。因为这个算法是只需要对图像特征和BEV特征加上额外的操作,所以可以对有BEV特征的算法都有提升作用。
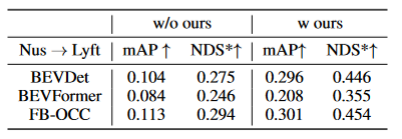
图5展示了检测到的未标记物体。第一行是标签的3D框,第二行是算法的检测结果。蓝色框表示算法可以检测到一些未标记的框。这表明方法在目标域甚至可以检测到没有标记的样本,例如过远或者街道两侧建筑内的车辆。

总结
本文提出了一种基于透视去偏的通用多摄像头3D物体检测框架,能够解决未知领域的物体检测问题。该框架通过将3D检测结果投影到2D相机平面,并纠正透视偏差,实现一致和准确的检测。此外,该框架还引入了透视去偏策略,通过渲染不同视角的图像来增强模型的鲁棒性。实验结果表明,该方法在领域泛化和无监督领域适应方面取得了显著的性能提升。此外,该方法还可以在虚拟数据集上进行训练,无需真实场景标注,为实时应用和大规模部署提供了便利。这些亮点展示了该方法在解决多摄像头3D物体检测中的挑战和潜力。这篇论文尝试利用Nerf的思路来提高BEV的泛化能力,同时可以利用有标签的源域数据和无标签的目标域数据。此外,尝试了Sim2Real的实验范式,这对于无人驾驶闭环具有潜在价值。从定性和定量结果都有很好的结果,并且开源了代码值得看一看。

原文链接:https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2g