












在大模型时代,Transformer 凭一己之力撑起了整个科研领域。自发布以来,基于 Transformer 的 LLM 在各种任务上表现出卓越的性能,其底层的 Transformer 架构已成为自然语言建模和推理的最先进技术,并在计算机视觉和强化学习等领域显示出强有力的前景。
然而,当前 Transformer 架构非常庞大,通常需要大量计算资源来进行训练和推理。
这是有意为之的,因为经过更多参数或数据训练的 Transformer 显然比其他模型更有能力。尽管如此,越来越多的工作表明,基于 Transformer 的模型以及神经网络不需要所有拟合参数来保留其学到的假设。
一般来讲,在训练模型时大规模过度参数化似乎很有帮助,但这些模型可以在推理之前进行大幅剪枝;有研究表明神经网络通常可以去除 90% 以上的权重,而性能不会出现任何显著下降。这种现象促使研究者开始转向有助于模型推理的剪枝策略研究。
来自 MIT、微软的研究者在论文《 The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction 》中提出了一个令人惊讶的发现,即在 Transformer 模型的特定层上进行仔细的剪枝可以显著提高模型在某些任务的性能。

- 论文地址:https://arxiv.org/pdf/2312.13558.pdf
- 论文主页:https://pratyushasharma.github.io/laser/
该研究将这种简单的干预措施称之为 LASER( LAyer SElective Rank reduction ,层选择性降秩),通过奇异值分解来选择性地减少 Transformer 模型中特定层的学习权重矩阵的高阶分量,从而显著提高 LLM 的性能,这种操作可以在模型训练完成后进行,并且不需要额外的参数或数据。
操作过程中,权重的减少是在模型特定权重矩阵和层中执行的,该研究还发现许多类似矩阵都可以显著减少权重,并且在完全删除 90% 以上的组件之前通常不会观察到性能下降。
该研究还发现这些减少可以显著提高准确率,这一发现似乎不仅限于自然语言,在强化学习中也发现了性能提升。
此外,该研究尝试推断出高阶组件中存储的内容是什么,以便进行删除从而提高性能。该研究发现经过 LASER 回答正确的问题,但在干预之前,原始模型主要用高频词 (如 “the”、“of” 等) 来回应,这些词甚至与正确答案的语义类型都不相同,也就是说这些成分在未经干预的情况下会导致模型生成一些不相干的高频词汇。
然而,通过进行一定程度的降秩后,模型的回答可以转变为正确的。
为了理解这一点,该研究还探索了其余组件各自编码的内容,他们仅使用其高阶奇异向量来近似权重矩阵。结果发现这些组件描述了与正确答案相同语义类别的不同响应或通用高频词。
这些结果表明,当嘈杂的高阶分量与低阶分量组合时,它们相互冲突的响应会产生一种平均答案,这可能是不正确的。图 1 直观地展示了 Transformer 架构和 LASER 遵循的程序。在这里,特定层的多层感知器(MLP)的权重矩阵被替换为其低秩近似。
LASER 概览
研究者详细介绍了 LASER 干预。单步 LASER 干预由包含参数 τ、层数ℓ和降秩 ρ 的三元组 (τ, ℓ, ρ) 定义。这些值共同描述了哪个矩阵会被它们的低秩近似所替代以及近似的严格程度。研究者依赖参数类型对他们将要干预的矩阵类型进行分类。
研究者重点关注 W = {W_q, W_k, W_v, W_o, U_in, U_out} 中的矩阵,它由 MLP 和注意力层中的矩阵组成。层数表示了研究者干预的层(第一层从 0 开始索引)。例如 Llama-2 有 32 层,因此 ℓ ∈ {0, 1, 2,・・・31}。
最终,ρ ∈ [0, 1) 描述了在做低秩近似时应该保留最大秩的哪一部分。例如设 ,则该矩阵的最大秩为 d。研究者将它替换为⌊ρ・d⌋- 近似。
,则该矩阵的最大秩为 d。研究者将它替换为⌊ρ・d⌋- 近似。
下图 1 为 LASER 示例,该图中,τ = U_in 和ℓ = L 表示在 L^th 层的 Transformer 块中来更新 MLP 第一层的权重矩阵。另一个参数控制 rank-k 近似中的 k。

LASER 可以限制网络中某些信息的流动,并出乎意料地产生显著的性能优势。这些干预也可以很容易组合起来,比如以任何顺序来应用一组干预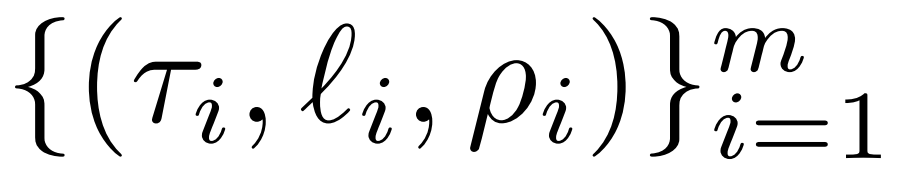 。
。
LASER 方法只是对这类干预进行简单的搜索,并修改以带来最大收益。不过,还有很多其他方法可以将这些干预组合起来,这是研究者未来工作的方向。
实验结果
在实验部分,研究者使用了在 PILE 数据集上预训练的 GPT-J 模型,该模型的层数为 27,参数为 60 亿。然后在 CounterFact 数据集上评估模型的行为,该数据集包含(主题、关系和答案)三元组的样本,每个问题提供了三个释义 prompt。
首先是 CounterFact 数据集上对 GPT-J 模型的分析。下图 2 展示了在 Transformer 架构中为每个矩阵应用不同数量降秩的结果对数据集分类损失的影响。其中每个 Transformer 层都由一个两层的小型 MLP 组成,输入和输出矩阵分别显示。不同的颜色表示移除组件的不同百分比。
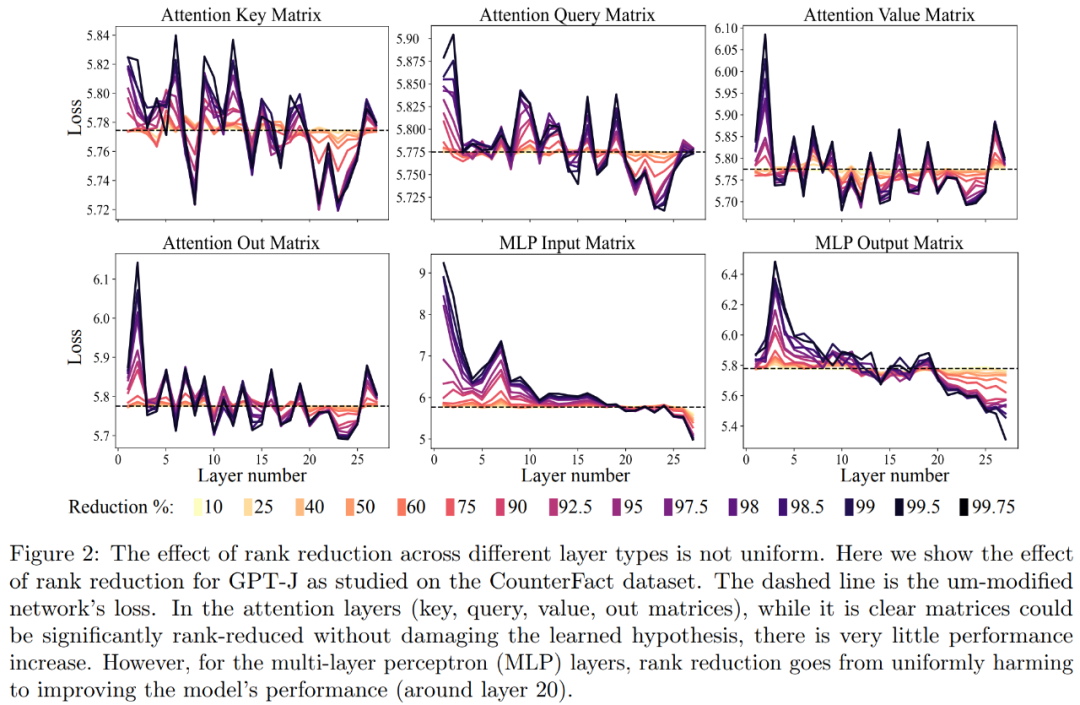
关于提升释义的准确度和稳健性,如上图 2 和下表 1 所示,研究者发现,当在单层上进行降秩时,GPT-J 模型在 CounterFact 数据集上的事实准确度从 13.1% 增加到了 24.0%。需要注意一点,这些改进只是降秩的结果,并不涉及对模型的任何进一步训练或微调。

数据集中的哪些事实会通过降秩恢复呢?研究者发现,通过降秩恢复的事实极大可能很少出现在数据中,如下图 3 所示。

高阶组件存储什么呢?研究者使用高阶组件近似最终的权重矩阵(而不像 LASER 那样使用低阶组件来近似),如下图 5 (a) 所示。当使用不同数量的高阶组件来近似矩阵时,他们测量了真实答案相对于预测答案的平均余弦相似度,如下图 5 (b) 所示。

最后,研究者评估了自身发现对 3 种不同的 LLM 在多项语言理解任务上的普遍性。对于每项任务,他们通过生成准确度、分类准确度和损失三种指标来评估模型的性能。如上表 1 所示,即使降秩很大也不会导致模型准确度下降,却可以提升模型性能。




















