












本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&&笔者的个人理解
目前基于纯相机的自动驾驶3D感知算法也可以按照2D目标检测的技术路线分为包含后处理的感知算法和不需要后处理(端到端)的感知算法。
诸如BEVDet这类密集检测的感知算法会在BEV特征的每个单元网格上利用3D Head来输出相应的感知结果,这就导致这类密集检测的感知结果最后需要利用3D NMS等后处理操作来抑制掉重复的检测框。
但是仿照2D目标检测中End-to-End的方法,在自动驾驶感知算法中也有Query-Based的检测算法,利用Transformer的Decoder模块直接输出最终的检测结果,省去了NMS后处理的操作。
虽然,目前这类Query-Based的算法模型的感知性能正在逐渐逼近或者超过BEV-Based的感知模型。但是,作者认为BEV-Based的感知算法相比于Query-Based的感知算法而言,更加的有利于对于整体的场景理解,因为BEV-Based的感知算法会对车身周围的前景区域或者背景区域均输出相应的语义特征。
同时,作者认为BEV-Based的算法目前落后于Query-Based的算法主要是由于缺少更加先进的网络设计和训练技巧。基于此,作者将目前经典的BEV-Based算法进行分析,并总结出了三条缺点,列举如下:
- 2D建模还不够不充分
在BEV-Based的感知算法当中,通常会利用一个由激光雷达采集的点云信号进行监督的深度估计网络来提高模型的2D建模能力。但是采集的点云信号很大程度上会受到激光雷达分辨率的限制,从而造成模型对于深度的感知不够准确,影响模型的感知性能。 - 时序建模能力还比较差
目前,基于BEV框架的感知算法对于时序的建模能力依旧比较有限,但是对于时序信息的理解对于自动驾驶感知算法而言却是非常重要的一环。在时序建模的过程中,当自车以及周围的物体在不断运动时,建立一个大感受野对于时序信息的融合是至关重要的。 - 投影转换中的特征失真
在基于BEV-Based的算法当中,在进行不同坐标系之间的坐标转换,或者特征图分辨率的变换过程中特征图的失真是非常容易发生的一件事情。而特征的失真问题对于自动驾驶的感知性能影响很非常大。
基于上述提到的几点问题,作者提出了一个更加先进的BEV-Based的算法模型,即BEV-NeXt。
论文的arxiv链接:https://arxiv.org/pdf/2312.01696.pdf
BEVNeXt算法流程
BEVNeXt是基于现有的LSS算法基础上构建起来的。BEVNeXt算法模型的整体框图如下所示。
 BEVNeXt算法模型的整体网络结构
BEVNeXt算法模型的整体网络结构
通过上图可知,BEVNeXt算法模型主要由三个子模块组成,分别是BEV Generation模块,BEV Encoder模块以及Detection Head模块。下面依次为大家介绍各个模块的功能及用途。
BEV Generation模块
首先针对网络模型输入的六张环视图像,利用2D主干网络提取输入环视图像的多尺度特征。论文中提取到的多尺度特征分别是原始输入图像的降采样4倍、8倍、16倍、32倍的特征结果。
接下来会将主干网络提取到的多尺度特征送入到深度估计网络Depth Net中预测离散的深度概率分布。然后利用论文中提出的Conditional Random Fields(CRF)利用输入图像的色彩信息对估计出来的深度信息进行调制,从而得到调制后的深度概率估计。接下来让我们来看看CRF-Modulated子模块具体是怎么来实现的。
- CRF-Modulated深度估计子模块
在基于BEV-Based的感知算法当中,对物体的深度信息进行估计可以帮助模型提高对于2D的建模能力。论文中指出提高2D的建模能力可以缓解模型在构建BEV特征过程中的失真问题。
因此对于纯视觉的感知任务而言,获取准确和高精度的深度估计对于模型的定位能力是非常有帮助的。因此论文中将深度估计看作是一个语义分割任务,并利用Conditional Random Fields(CRF)来增强模型的深度估计能力。
具体而言,论文中希望施加颜色平滑的方法来调制深度估计,从而缓解2D深度估计的不足实现在像素级别执行深度的一致性功能。
假设代表降采样特征图所包含的个像素,代表需要估计的个离散的深度信息。而深度估计网络的目标就是为每一个像素值分配对应的离散深度,用数学公式表示为。所以最终所需要优化的目标就是使得相应的Energy Cost最小,代价公式计算方式如下:其中,公式里的
用来衡量与深度估计网络初始输出的代价损失。而其具体的衡量公式如下所示:
其中,和代表图像块的平均RGB色彩像素值,表示两个离散的深度网格之间的label兼容性,用来衡量其在现实世界中的实际距离。
最后利用View Transformer结合提取出来的多尺度图像特征以及调制后的离散深度概率值来构建最终当前T时刻的BEV特征。
BEV Encoder模块
论文中设计的BEV Encoder模块用于融合过去K帧计算得到的历史BEV特征信息。由于前文已经提到了,在时序信息融合的过程当中需要足够大的感受野来获取自车周围运动的目标特征信息。而这一过程是通过论文提出的Res2Fusion子网络来实现的。
- Res2Fusion子网络
作者认为将当前时刻的BEV特征与历史帧的BEV特征进行融合有助于提高模型对于动态物体的感知能力。然而,在BEV空间扩展模型的感受野是非常有挑战性的,如果简单的扩大卷积核的大小不仅会增加模型的计算量还会增加模型的过拟合风险。
为此,论文中是提出了Res2Fusion子网络,该部分的网络结构如下图所示
 Res2Fusion子网络整体网络结构
Res2Fusion子网络整体网络结构
针对当前帧以及前K个时刻的历史BEV特征信息,首先以窗口大小为尺寸将所有BEV特征分成组。然后利 用卷积降低每组特征的通道数,该部分可以表示成
再降低通道数之后,再采用多尺度卷积操作进行特征提取从而扩大模型的感受野,提高模型对于时序信息的建模能力。该部分的数学 表达式如下:
Detection Head模块
最后将得到的统一BEV特征,利用Center-Based的3D检测头进行处理,从而获取最终的3D感知结果。但是生成最终检测结果的过程当中,作者采用CRF-Modulated深度估计子模块得到的深度估计概率帮助模型区分不同位置的目标特征。
- Perspective Refinement
前文也有提到,将2D的图像特征利用坐标转换关系变换到3D空间会造成特征的失真问题。所以在本文中,作者利用透视精修的方法来对齐前景区域的特征。
具体而言,作者利用CenterPoint中的3D检测头来获取目标的中心位置,在此中心位置的基础上考虑大小的邻域范围,利用一组可学习的查询,使用可变形注意力来实现透视精修的过程。为了进一步的引入深度信息的指导,论文中将CRF-Modulated子网络中估计出来的深度信息嵌入到了2D图像特征当中,具体公式如下其中,代表可变形卷积运算,是将点Lift到高度后的一组参考点。
实验
作者在nuScenes数据集上来验证提出的算法模型的有效性。通过表格中的结果可以看出,在采用不同2D Backbone的情况下,BEVNeXt均实现了非常出色的检测结果。
 BEVNeXt算法模型在nuScenes val数据集上的实验结果对比
BEVNeXt算法模型在nuScenes val数据集上的实验结果对比
此外,论文为了更加直观的展示所提出的CRF-Modulated深度估计网络的效果,分别对几组输入图像进行了可视化,如下图所示

Conditional Random Field模块的可视化效果对比
通过可视化结果也可以比较清晰的看出,采用了CRF模块的深度估计更加的准确,目标的边缘更加的锐利,前景区域和背景区域区分的也更加的明显,从而证明了所提出的CRF模块的有效性。
除此之外,论文也通过可视化的方式来验证了提出的Perspective Refinement创新点的有效性。
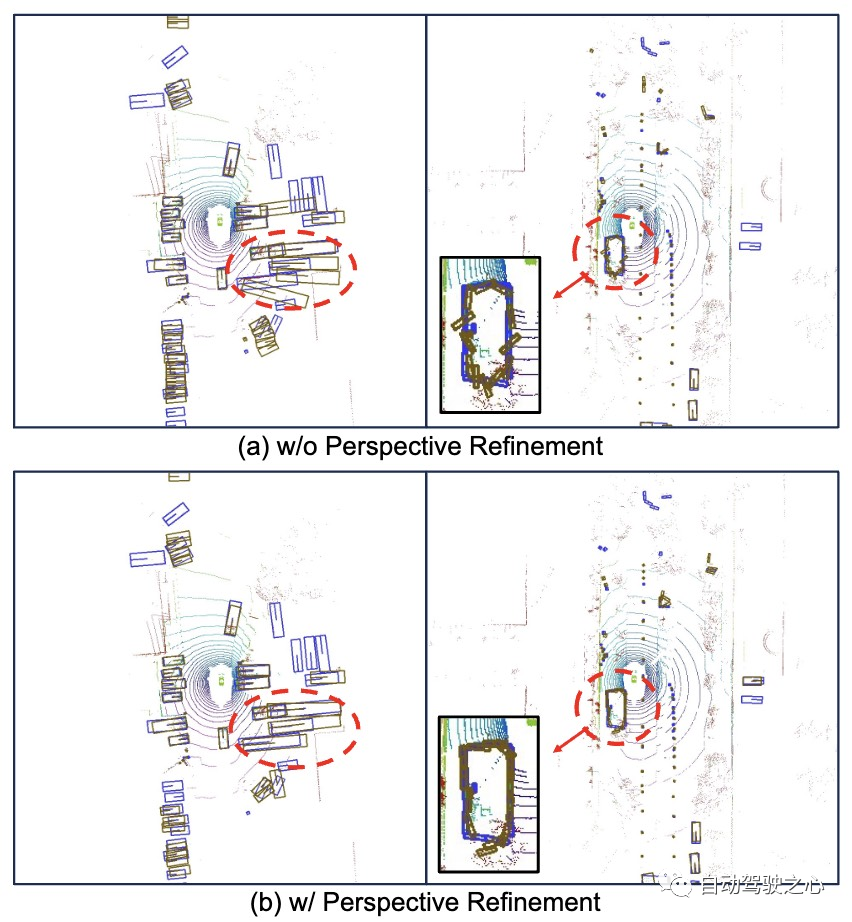
Perspective Refinement模块可视化效果对比
通过上面的可视化结果可以比较清楚的看出,无论是大目标还是小目标都可以从提出的Perspective Refinement模块上受益。同时通过进一步的细化,模型在方向上的预测更加准确。
总结
目前虽然Query-Based的算法模型整体感知性能要好于BEV-Based的算法,但是作者将原因归结于目前密集BEV-Based检测模型的网络结构和训练策略,基于提到的相关缺点,本文介绍的BEVNeXt分别从2D建模能力、时序信息融合、透视精修等角度对BEV-Based的算法模型进行增强,希望本文可以给大家带来帮助~

原文链接:https://mp.weixin.qq.com/s/vPDCMSSW1bp0zZ2d73xYzg






























