












本文经自动驾驶之心公众号授权转载,转载请联系出处。
原标题:Point Transformer V3: Simpler, Faster, Stronger
论文链接:https://arxiv.org/pdf/2312.10035.pdf
代码链接:https://github.com/Pointcept/PointTransformerV3
作者单位:HKU SH AI Lab MPI PKU MIT
论文思路:
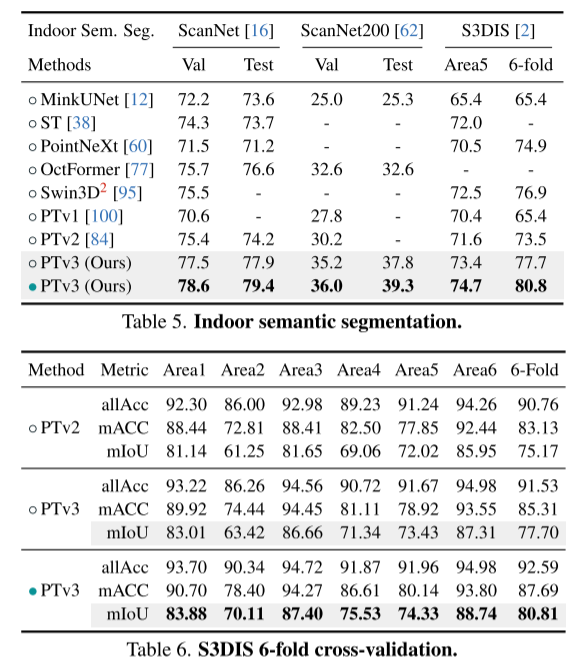
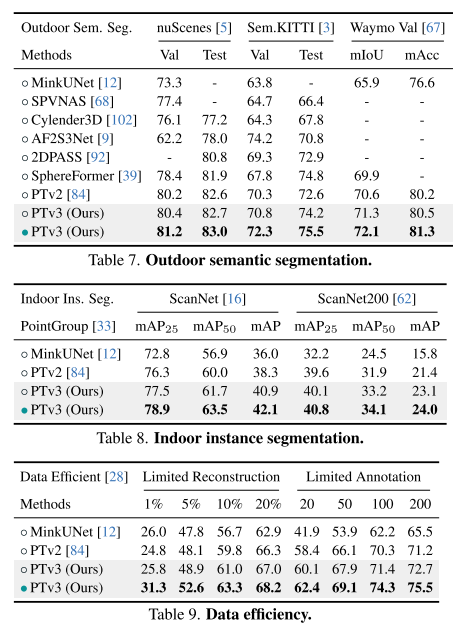
本文无意在注意力机制内寻求创新。相反,它侧重于利用规模(scale)的力量,克服点云处理背景下准确性和效率之间现有的权衡。从 3D 大规模表示学习的最新进展中汲取灵感,本文认识到模型性能更多地受到规模的影响,而不是复杂的设计。因此,本文提出了 Point Transformer V3 (PTv3),它优先考虑简单性和效率,而不是某些机制的准确性,这些机制对 scaling 后的整体性能影响较小,例如用以特定模式组织的点云的高效序列化邻域映射来替换 KNN 的精确邻域搜索。这一原理实现了显着的 scaling,将感受野从 16 点扩展到 1024 点,同时保持高效(与前身 PTv2 相比,处理速度提高了 3 倍,内存效率提高了 10 倍)。PTv3 在涵盖室内和室外场景的 20 多个下游任务中取得了最先进的结果。通过多数据集联合训练的进一步增强,PTv3 将这些结果推向了更高的水平。
网络设计:
3D 表示学习的最新进展 [85] 通过引入跨多个 3D 数据集的协同训练方法,在克服点云处理中的数据规模限制方面取得了进展。与该策略相结合,高效的卷积 backbone [12] 有效地弥补了通常与 point cloud transformers [38, 84] 相关的精度差距。然而,由于与稀疏卷积相比,point cloud transformers 的效率存在差距,因此 point cloud transformers 本身尚未完全受益于这种规模优势。这一发现塑造了本文工作的最初动机:用 scaling principle 的视角重新权衡 point transformers 的设计选择。本文认为模型性能受规模的影响比受复杂设计的影响更显着。
因此,本文引入了 Point Transformer V3 (PTv3),它优先考虑简单性和效率,而不是某些机制的准确性,从而实现 scalability 。这样的调整对 scaling 后的整体性能影响可以忽略不计。具体来说,PTv3 进行了以下调整以实现卓越的效率和 scalability :
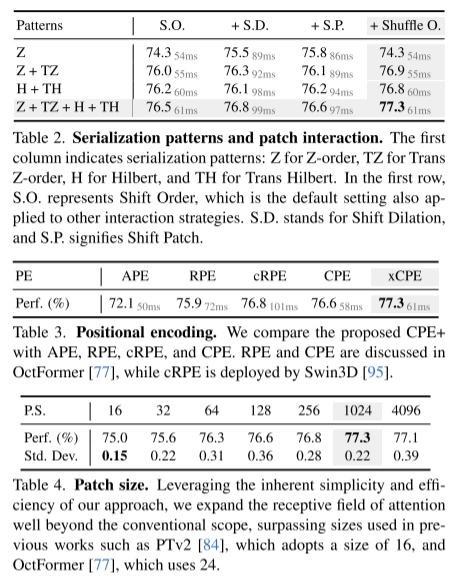
- 受到最近两项进展 [48, 77] 的启发,并认识到结构化非结构化点云的 scalability 优势,PTv3 改变了由 K-Nearest Neighbors (KNN) query 定义的传统空间邻近性,占 forward time 的 28%。相反,它探索了点云中根据特定模式组织的序列化邻域的潜力。
- PTv3 采用专为序列化点云量身定制的简化方法,取代了更复杂的注意力 patch 交互机制,例如 shift-window(阻碍注意力算子的融合)和邻域机制(导致高内存消耗)。
- PTv3 消除了对占 forward time 26% 的相对位置编码的依赖,有利于更简单的前置稀疏卷积层。
本文认为这些设计是由现有 point cloud transformers 的 scaling principles 和进步驱动的直观选择。重要的是,本文强调了认识 scalability 如何影响 backbone 设计的至关重要性,而不是详细的模块设计。
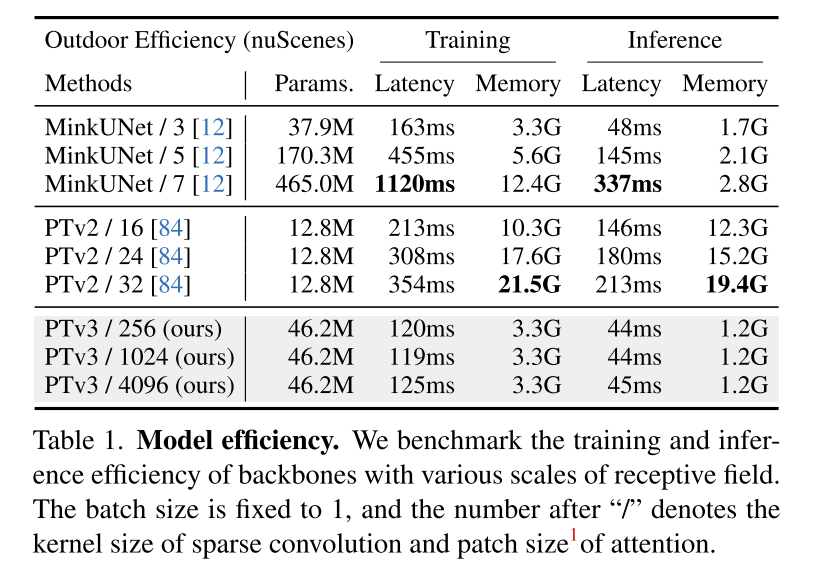
这一原则显着增强了 scalability ,克服了准确性和效率之间的传统权衡(见图 1)。与前身相比,PTv3 的推理速度提高了 3.3 倍,内存使用量降低了 10.2 倍。更重要的是,PTv3 利用其固有的 scale 感知范围的能力,将其感受野从 16 点扩展到 1024 点,同时保持效率。这种 scalability 支撑了其在现实世界感知任务中的卓越性能,其中 PTv3 在室内和室外场景中的 20 多个下游任务中取得了最先进的结果。PTv3 通过多数据集训练进一步扩大其数据规模 [85],进一步提升了这些结果。本文希望本文的见解能够激发未来这一方向的研究。

图 1.Point Transformer V3 (PTv3) 概述。与其前身PTv2[84]相比,本文的PTv3在以下方面表现出优越性:1.性能更强。PTv3 在各种室内和室外 3D 感知任务中均取得了最先进的结果。2.更宽的感受野。受益于简单性和效率,PTv3 将感受野从 16 点扩展到 1024 点。3、速度更快。PTv3 显着提高了处理速度,使其适合对延迟敏感的应用程序。4. 降低内存消耗。PTv3 减少了内存使用量,增强了更广泛情况下的可访问性。
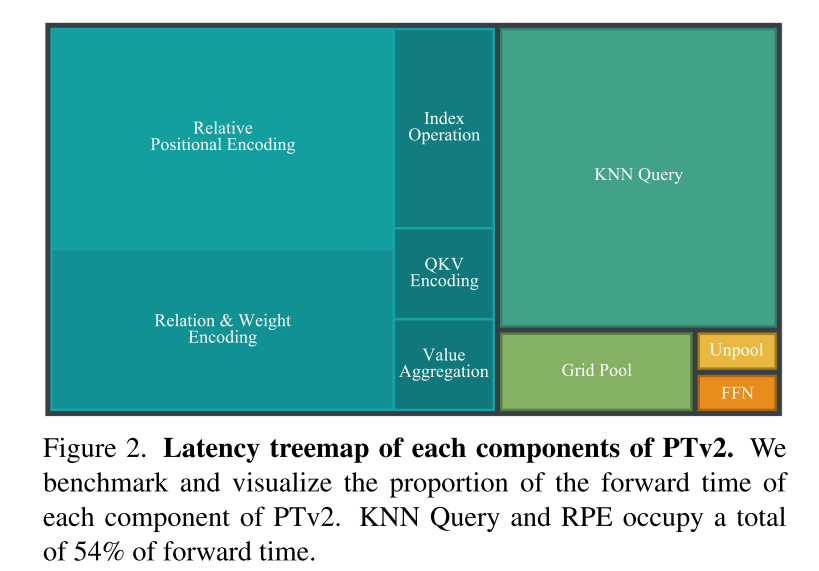
图 2. PTv2 各组件的延迟树形图。本文对 PTv2 的每个组件的 forward time 比例进行基准测试和可视化。KNN Query 和 RPE 总共占用了 54% 的 forward time 。

图 3.点云序列化。本文通过三元组可视化展示了四种序列化模式。对于每个三元组,显示了用于序列化的空间填充曲线(左)、空间填充曲线内的点云序列化变量排序顺序(中)以及用于局部注意力的序列化点云的 grouped patches(右)。四种序列化模式的转换允许注意力机制捕获各种空间关系和上下文,从而提高模型准确性和泛化能力。
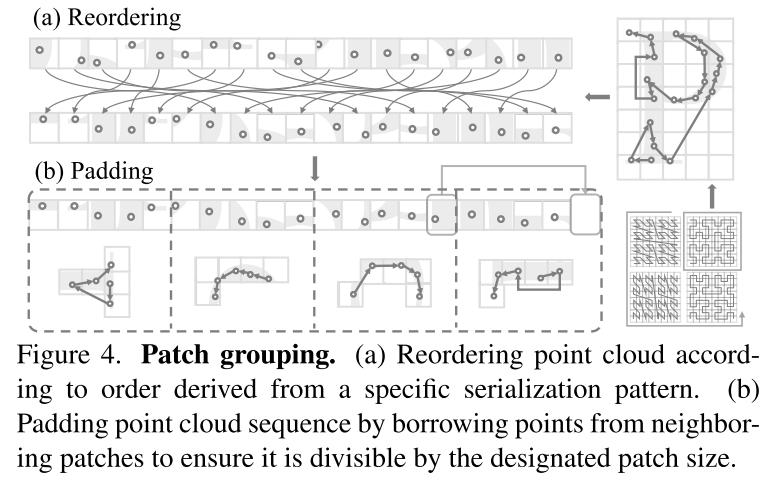
图 4. Patch grouping。(a) 根据从特定序列化模式导出的顺序对点云进行重新排序。(b) 通过借用相邻 patches 的点来填充点云序列,以确保它可以被指定的 patch size 整除。
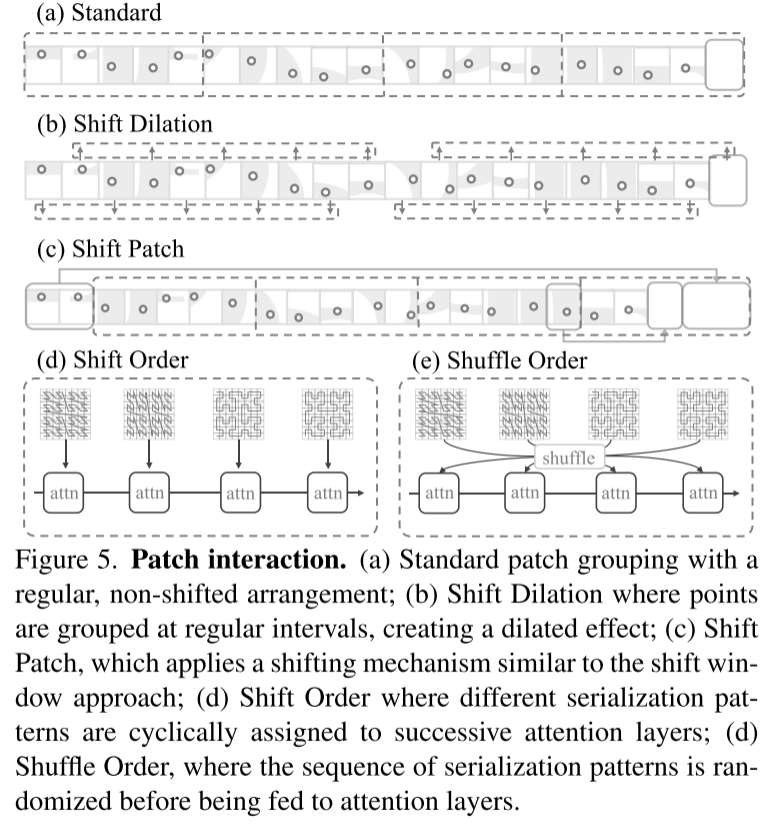
图 5. Patch interaction。(a) Standard patch grouping,具有规则的、非移位的排列;(b) 平移扩张,其中点按规则间隔聚合,产生扩张效果;(c) Shift Patch,采用类似于 shift window 方法的移位机制;(d) Shift Order,其中不同的序列化模式被循环分配给连续的注意力层;(d) Shuffle Order,序列化模式的序列在输入到注意层之前被随机化。
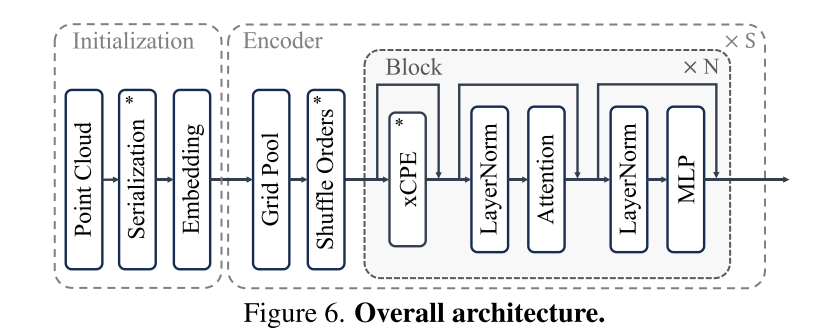
图 6. 整体架构。
实验结果:
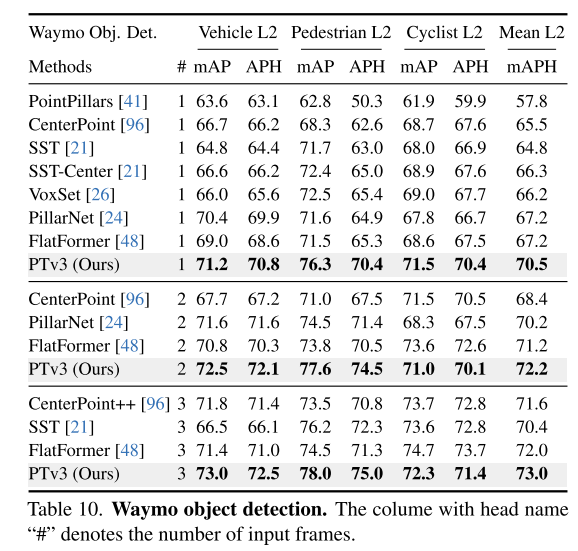
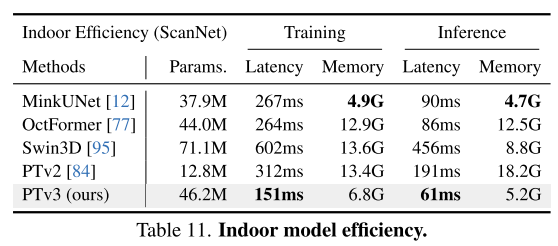
总结:
本文介绍了 Point Transformer V3,它朝着克服点云处理中准确性和效率之间的传统权衡迈出了一大步。在对 backbone 设计中 scaling principle 的新颖解释的指导下,本文认为模型性能受规模的影响比受复杂设计的影响更深刻。通过优先考虑效率而不是影响较小的机制的准确性,本文利用规模的力量,从而提高性能。简而言之,通过使模型更简单、更快,本文可以使其变得更强大。
引用:
Wu, X., Jiang, L., Wang, P., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., & Zhao, H. (2023). Point Transformer V3: Simpler, Faster, Stronger. ArXiv. /abs/2312.10035

原文链接:https://mp.weixin.qq.com/s/u_kN8bCHO96x9FfS4HQGiA
















