














在开发中,我们经常会遇到这样的需求,将Excel的数据导入数据库中。
一、一般我会这样做:
- 通过POI读取需要导入的Excel。
- 以文件名为表名、列头为列名、并将数据拼接成sql。
- 通过JDBC或mybatis插入数据库。

操作起来,如果文件比较多,数据量都很大的时候,会非常慢。
访问之后,感觉没什么反应,实际上已经在读取 + 入库了,只是比较慢而已。
读取一个10万行的Excel,居然用了191s,我还以为它卡死了呢!
private void readXls(String filePath, String filename) throws Exception {
@SuppressWarnings("resource")
XSSFWorkbook xssfWorkbook = new XSSFWorkbook(new FileInputStream(filePath));
// 读取第一个工作表
XSSFSheet sheet = xssfWorkbook.getSheetAt(0);
// 总行数
int maxRow = sheet.getLastRowNum();
StringBuilder insertBuilder = new StringBuilder();
insertBuilder.append("insert into ").append(filename).append(" ( UUID,");
XSSFRow row = sheet.getRow(0);
for (int i = 0; i < row.getPhysicalNumberOfCells(); i++) {
insertBuilder.append(row.getCell(i)).append(",");
}
insertBuilder.deleteCharAt(insertBuilder.length() - 1);
insertBuilder.append(" ) values ( ");
StringBuilder stringBuilder = new StringBuilder();
for (int i = 1; i <= maxRow; i++) {
XSSFRow xssfRow = sheet.getRow(i);
String id = "";
String name = "";
for (int j = 0; j < row.getPhysicalNumberOfCells(); j++) {
if (j == 0) {
id = xssfRow.getCell(j) + "";
} else if (j == 1) {
name = xssfRow.getCell(j) + "";
}
}
boolean flag = isExisted(id, name);
if (!flag) {
stringBuilder.append(insertBuilder);
stringBuilder.append('\'').append(uuid()).append('\'').append(",");
for (int j = 0; j < row.getPhysicalNumberOfCells(); j++) {
stringBuilder.append('\'').append(value).append('\'').append(",");
}
stringBuilder.deleteCharAt(stringBuilder.length() - 1);
stringBuilder.append(" )").append("\n");
}
}
List<String> collect = Arrays.stream(stringBuilder.toString().split("\n")).collect(Collectors.toList());
int sum = JdbcUtil.executeDML(collect);
}
private static boolean isExisted(String id, String name) {
String sql = "select count(1) as num from " + static_TABLE + " where ID = '" + id + "' and NAME = '" + name + "'";
String num = JdbcUtil.executeSelect(sql, "num");
return Integer.valueOf(num) > 0;
}
private static String uuid() {
return UUID.randomUUID().toString().replace("-", "");
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
二、谁写的?拖出去,斩了!
- 优化1:先查询全部数据,缓存到map中,插入前再进行判断,速度快了很多。
- 优化2:如果单个Excel文件过大,可以采用 异步 + 多线程 读取若干行,分批入库。
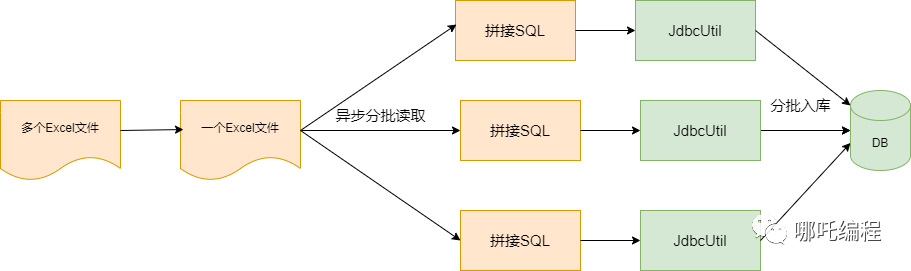
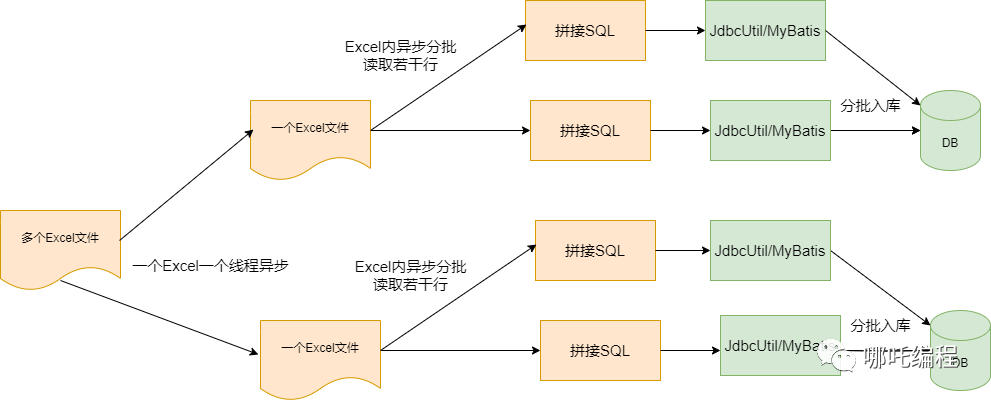
使用双异步后,从 191s 优化到 2s,你敢信?
下面贴出异步读取Excel文件、并分批读取大Excel文件的关键代码
1、readExcelCacheAsync控制类
@RequestMapping(value = "/readExcelCacheAsync", method = RequestMethod.POST)
@ResponseBody
public String readExcelCacheAsync() {
String path = "G:\\测试\\data\\";
try {
// 在读取Excel之前,缓存所有数据
USER_INFO_SET = getUserInfo();
File file = new File(path);
String[] xlsxArr = file.list();
for (int i = 0; i < xlsxArr.length; i++) {
File fileTemp = new File(path + "\\" + xlsxArr[i]);
String filename = fileTemp.getName().replace(".xlsx", "");
readExcelCacheAsyncService.readXls(path + filename + ".xlsx", filename);
}
} catch (Exception e) {
logger.error("|#ReadDBCsv|#异常: ", e);
return "error";
}
return "success";
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
2、分批读取超大Excel文件
@Async("async-executor")
public void readXls(String filePath, String filename) throws Exception {
@SuppressWarnings("resource")
XSSFWorkbook xssfWorkbook = new XSSFWorkbook(new FileInputStream(filePath));
// 读取第一个工作表
XSSFSheet sheet = xssfWorkbook.getSheetAt(0);
// 总行数
int maxRow = sheet.getLastRowNum();
logger.info(filename + ".xlsx,一共" + maxRow + "行数据!");
StringBuilder insertBuilder = new StringBuilder();
insertBuilder.append("insert into ").append(filename).append(" ( UUID,");
XSSFRow row = sheet.getRow(0);
for (int i = 0; i < row.getPhysicalNumberOfCells(); i++) {
insertBuilder.append(row.getCell(i)).append(",");
}
insertBuilder.deleteCharAt(insertBuilder.length() - 1);
insertBuilder.append(" ) values ( ");
int times = maxRow / STEP + 1;
//logger.info("将" + maxRow + "行数据分" + times + "次插入数据库!");
for (int time = 0; time < times; time++) {
int start = STEP * time + 1;
int end = STEP * time + STEP;
if (time == times - 1) {
end = maxRow;
}
if(end + 1 - start > 0){
//logger.info("第" + (time + 1) + "次插入数据库!" + "准备插入" + (end + 1 - start) + "条数据!");
//readExcelDataAsyncService.readXlsCacheAsync(sheet, row, start, end, insertBuilder);
readExcelDataAsyncService.readXlsCacheAsyncMybatis(sheet, row, start, end, insertBuilder);
}
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
3、异步批量入库
@Async("async-executor")
public void readXlsCacheAsync(XSSFSheet sheet, XSSFRow row, int start, int end, StringBuilder insertBuilder) {
StringBuilder stringBuilder = new StringBuilder();
for (int i = start; i <= end; i++) {
XSSFRow xssfRow = sheet.getRow(i);
String id = "";
String name = "";
for (int j = 0; j < row.getPhysicalNumberOfCells(); j++) {
if (j == 0) {
id = xssfRow.getCell(j) + "";
} else if (j == 1) {
name = xssfRow.getCell(j) + "";
}
}
// 先在读取Excel之前,缓存所有数据,再做判断
boolean flag = isExisted(id, name);
if (!flag) {
stringBuilder.append(insertBuilder);
stringBuilder.append('\'').append(uuid()).append('\'').append(",");
for (int j = 0; j < row.getPhysicalNumberOfCells(); j++) {
stringBuilder.append('\'').append(value).append('\'').append(",");
}
stringBuilder.deleteCharAt(stringBuilder.length() - 1);
stringBuilder.append(" )").append("\n");
}
}
List<String> collect = Arrays.stream(stringBuilder.toString().split("\n")).collect(Collectors.toList());
if (collect != null && collect.size() > 0) {
int sum = JdbcUtil.executeDML(collect);
}
}
private boolean isExisted(String id, String name) {
return ReadExcelCacheAsyncController.USER_INFO_SET.contains(id + "," + name);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
4、异步线程池工具类
@Async的作用就是异步处理任务。
- 在方法上添加@Async,表示此方法是异步方法;
- 在类上添加@Async,表示类中的所有方法都是异步方法;
- 使用此注解的类,必须是Spring管理的类;
- 需要在启动类或配置类中加入@EnableAsync注解,@Async才会生效;
在使用@Async时,如果不指定线程池的名称,也就是不自定义线程池,@Async是有默认线程池的,使用的是Spring默认的线程池SimpleAsyncTaskExecutor。
默认线程池的默认配置如下:
- 默认核心线程数:8;
- 最大线程数:Integet.MAX_VALUE;
- 队列使用LinkedBlockingQueue;
- 容量是:Integet.MAX_VALUE;
- 空闲线程保留时间:60s;
- 线程池拒绝策略:AbortPolicy;
从最大线程数可以看出,在并发情况下,会无限制的创建线程,我勒个吗啊。
也可以通过yml重新配置:
spring:
task:
execution:
pool:
max-size: 10
core-size: 5
keep-alive: 3s
queue-capacity: 1000
thread-name-prefix: my-executor- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
也可以自定义线程池,下面通过简单的代码来实现以下@Async自定义线程池。
@EnableAsync// 支持异步操作
@Configuration
public class AsyncTaskConfig {
/**
* com.google.guava中的线程池
* @return
*/
@Bean("my-executor")
public Executor firstExecutor() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("my-executor").build();
// 获取CPU的处理器数量
int curSystemThreads = Runtime.getRuntime().availableProcessors() * 2;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(curSystemThreads, 100,
200, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), threadFactory);
threadPool.allowsCoreThreadTimeOut();
return threadPool;
}
/**
* Spring线程池
* @return
*/
@Bean("async-executor")
public Executor asyncExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
// 核心线程数
taskExecutor.setCorePoolSize(24);
// 线程池维护线程的最大数量,只有在缓冲队列满了之后才会申请超过核心线程数的线程
taskExecutor.setMaxPoolSize(200);
// 缓存队列
taskExecutor.setQueueCapacity(50);
// 空闲时间,当超过了核心线程数之外的线程在空闲时间到达之后会被销毁
taskExecutor.setKeepAliveSeconds(200);
// 异步方法内部线程名称
taskExecutor.setThreadNamePrefix("async-executor-");
/**
* 当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略
* 通常有以下四种策略:
* ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
* ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
* ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
* ThreadPoolExecutor.CallerRunsPolicy:重试添加当前的任务,自动重复调用 execute() 方法,直到成功
*/
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.initialize();
return taskExecutor;
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
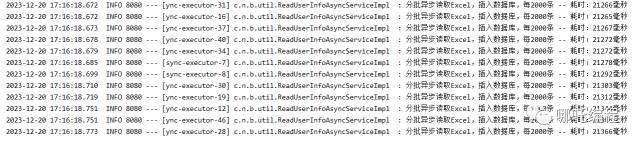
5、异步失效的原因
- 注解@Async的方法不是public方法。
- 注解@Async的返回值只能为void或Future。
- 注解@Async方法使用static修饰也会失效。
- 没加@EnableAsync注解。
- 调用方和@Async不能在一个类中。
- 在Async方法上标注@Transactional是没用的,但在Async方法调用的方法上标注@Transcational是有效的。
三、线程池中的核心线程数设置问题
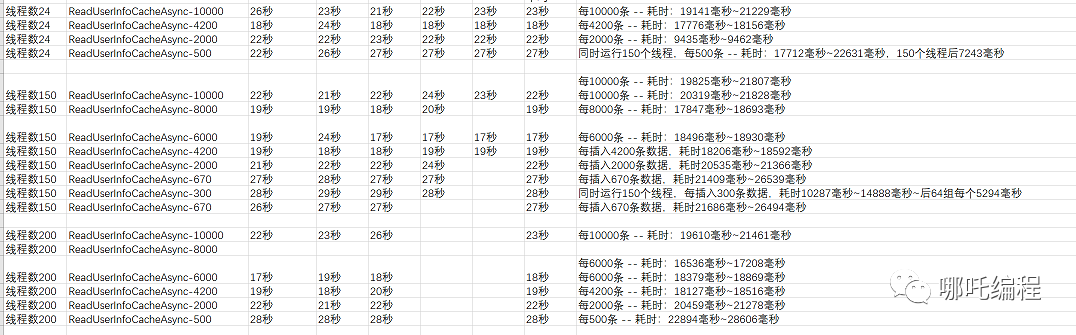
有一个问题,一直没时间摸索,线程池中的核心线程数CorePoolSize、最大线程数MaxPoolSize,设置成多少,最合适,效率最高。
借着这个机会,测试一下。
1、我记得有这样一个说法,CPU的处理器数量
将核心线程数CorePoolSize设置成CPU的处理器数量,是不是效率最高的?
// 获取CPU的处理器数量
int curSystemThreads = Runtime.getRuntime().availableProcessors() * 2;- 1.
- 2.
Runtime.getRuntime().availableProcessors()获取的是CPU核心线程数,也就是计算资源。
- CPU密集型,线程池大小设置为N,也就是和cpu的线程数相同,可以尽可能地避免线程间上下文切换,但在实际开发中,一般会设置为N+1,为了防止意外情况出现线程阻塞,如果出现阻塞,多出来的线程会继续执行任务,保证CPU的利用效率。
- IO密集型,线程池大小设置为2N,这个数是根据业务压测出来的,如果不涉及业务就使用推荐。
在实际中,需要对具体的线程池大小进行调整,可以通过压测及机器设备现状,进行调整大小。
如果线程池太大,则会造成CPU不断的切换,对整个系统性能也不会有太大的提升,反而会导致系统缓慢。
我的电脑的CPU的处理器数量是24。
那么一次读取多少行最合适呢?
测试的Excel中含有10万条数据,10万/24 = 4166,那么我设置成4200,是不是效率最佳呢?
测试的过程中发现,好像真的是这样的。
2、我记得大家都习惯性的将核心线程数CorePoolSize和最大线程数MaxPoolSize设置成一样的,都爱设置成200
是随便写的,还是经验而为之?
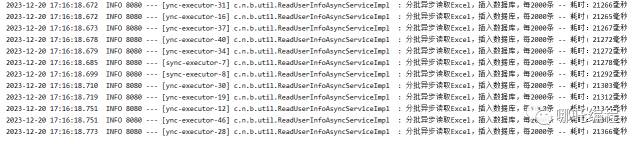
测试发现,当你将核心线程数CorePoolSize和最大线程数MaxPoolSize都设置为200的时候,第一次它会同时开启150个线程,来进行工作。
这个是为什么?
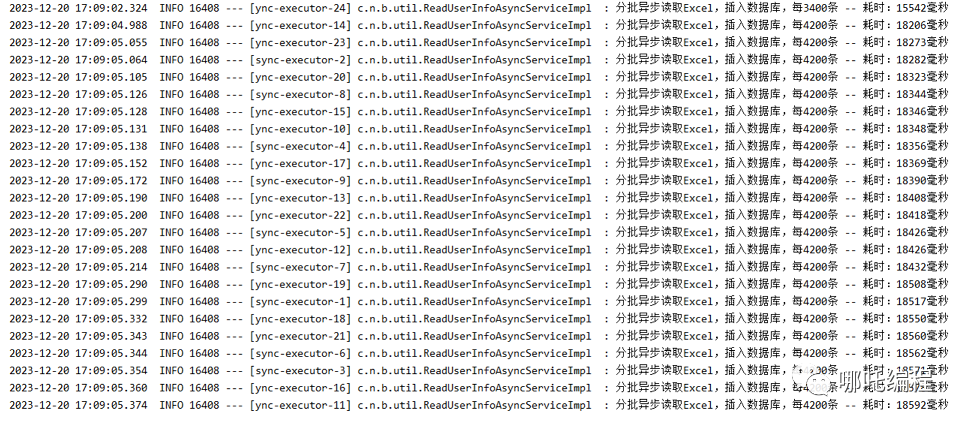
3、经过数十次的测试
- 发现核心线程数好像差别不大。
- 每次读取和入库的数量是关键,不能太多,因为每次入库会变慢。
- 也不能太少,如果太少,超过了150个线程,就会造成线程阻塞,也会变慢。
四、通过EasyExcel读取并插入数据库
EasyExcel的方式,我就不写双异步优化了,大家切记陷入低水平勤奋的怪圈。
1、ReadEasyExcelController
@RequestMapping(value = "/readEasyExcel", method = RequestMethod.POST)
@ResponseBody
public String readEasyExcel() {
try {
String path = "G:\\测试\\data\\";
String[] xlsxArr = new File(path).list();
for (int i = 0; i < xlsxArr.length; i++) {
String filePath = path + xlsxArr[i];
File fileTemp = new File(path + xlsxArr[i]);
String fileName = fileTemp.getName().replace(".xlsx", "");
List<UserInfo> list = new ArrayList<>();
EasyExcel.read(filePath, UserInfo.class, new ReadEasyExeclAsyncListener(readEasyExeclService, fileName, batchCount, list)).sheet().doRead();
}
}catch (Exception e){
logger.error("readEasyExcel 异常:",e);
return "error";
}
return "suceess";
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
2、ReadEasyExeclAsyncListener
public ReadEasyExeclService readEasyExeclService;
// 表名
public String TABLE_NAME;
// 批量插入阈值
private int BATCH_COUNT;
// 数据集合
private List<UserInfo> LIST;
public ReadEasyExeclAsyncListener(ReadEasyExeclService readEasyExeclService, String tableName, int batchCount, List<UserInfo> list) {
this.readEasyExeclService = readEasyExeclService;
this.TABLE_NAME = tableName;
this.BATCH_COUNT = batchCount;
this.LIST = list;
}
@Override
public void invoke(UserInfo data, AnalysisContext analysisContext) {
data.setUuid(uuid());
data.setTableName(TABLE_NAME);
LIST.add(data);
if(LIST.size() >= BATCH_COUNT){
// 批量入库
readEasyExeclService.saveDataBatch(LIST);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
if(LIST.size() > 0){
// 最后一批入库
readEasyExeclService.saveDataBatch(LIST);
}
}
public static String uuid() {
return UUID.randomUUID().toString().replace("-", "");
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
3、ReadEasyExeclServiceImpl
@Service
public class ReadEasyExeclServiceImpl implements ReadEasyExeclService {
@Resource
private ReadEasyExeclMapper readEasyExeclMapper;
@Override
public void saveDataBatch(List<UserInfo> list) {
// 通过mybatis入库
readEasyExeclMapper.saveDataBatch(list);
// 通过JDBC入库
// insertByJdbc(list);
list.clear();
}
private void insertByJdbc(List<UserInfo> list){
List<String> sqlList = new ArrayList<>();
for (UserInfo u : list){
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("insert into ").append(u.getTableName()).append(" ( UUID,ID,NAME,AGE,ADDRESS,PHONE,OP_TIME ) values ( ");
sqlBuilder.append("'").append(ReadEasyExeclAsyncListener.uuid()).append("',")
.append("'").append(u.getId()).append("',")
.append("'").append(u.getName()).append("',")
.append("'").append(u.getAge()).append("',")
.append("'").append(u.getAddress()).append("',")
.append("'").append(u.getPhone()).append("',")
.append("sysdate )");
sqlList.add(sqlBuilder.toString());
}
JdbcUtil.executeDML(sqlList);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
4、UserInfo
@Data
public class UserInfo {
private String tableName;
private String uuid;
@ExcelProperty(value = "ID")
private String id;
@ExcelProperty(value = "NAME")
private String name;
@ExcelProperty(value = "AGE")
private String age;
@ExcelProperty(value = "ADDRESS")
private String address;
@ExcelProperty(value = "PHONE")
private String phone;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.












